Redis内部数据结构详解(7)——intset
2016-11-22
本文是《Redis内部数据结构详解》系列的第七篇。在本文中,我们围绕一个Redis的内部数据结构——intset展开讨论。
Redis里面使用intset是为了实现集合(set)这种对外的数据结构。set结构类似于数学上的集合的概念,它包含的元素无序,且不能重复。Redis里的set结构还实现了基础的集合并、交、差的操作。与Redis对外暴露的其它数据结构类似,set的底层实现,随着元素类型是否是整型以及添加的元素的数目多少,而有所变化。概括来讲,当set中添加的元素都是整型且元素数目较少时,set使用intset作为底层数据结构,否则,set使用dict作为底层数据结构。
在本文中我们将大体分成三个部分进行介绍:
- 集中介绍intset数据结构。
- 讨论set是如何在intset和dict基础上构建起来的。
- 集中讨论set的并、交、差的算法实现以及时间复杂度。注意,其中差集的计算在Redis中实现了两种算法。
我们在讨论中还会涉及到一个Redis配置(在redis.conf中的ADVANCED CONFIG部分):
set-max-intset-entries 512
注:本文讨论的代码实现基于Redis源码的3.2分支。
intset数据结构简介
intset顾名思义,是由整数组成的集合。实际上,intset是一个由整数组成的有序集合,从而便于在上面进行二分查找,用于快速地判断一个元素是否属于这个集合。它在内存分配上与ziplist有些类似,是连续的一整块内存空间,而且对于大整数和小整数(按绝对值)采取了不同的编码,尽量对内存的使用进行了优化。
intset的数据结构定义如下(出自intset.h和intset.c):
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))
各个字段含义如下:
encoding: 数据编码,表示intset中的每个数据元素用几个字节来存储。它有三种可能的取值:INTSET_ENC_INT16表示每个元素用2个字节存储,INTSET_ENC_INT32表示每个元素用4个字节存储,INTSET_ENC_INT64表示每个元素用8个字节存储。因此,intset中存储的整数最多只能占用64bit。length: 表示intset中的元素个数。encoding和length两个字段构成了intset的头部(header)。contents: 是一个柔性数组(flexible array member),表示intset的header后面紧跟着数据元素。这个数组的总长度(即总字节数)等于encoding * length。柔性数组在Redis的很多数据结构的定义中都出现过(例如sds, quicklist, skiplist),用于表达一个偏移量。contents需要单独为其分配空间,这部分内存不包含在intset结构当中。
其中需要注意的是,intset可能会随着数据的添加而改变它的数据编码:
- 最开始,新创建的intset使用占内存最小的INTSET_ENC_INT16(值为2)作为数据编码。
- 每添加一个新元素,则根据元素大小决定是否对数据编码进行升级。
下图给出了一个添加数据的具体例子(点击看大图)。
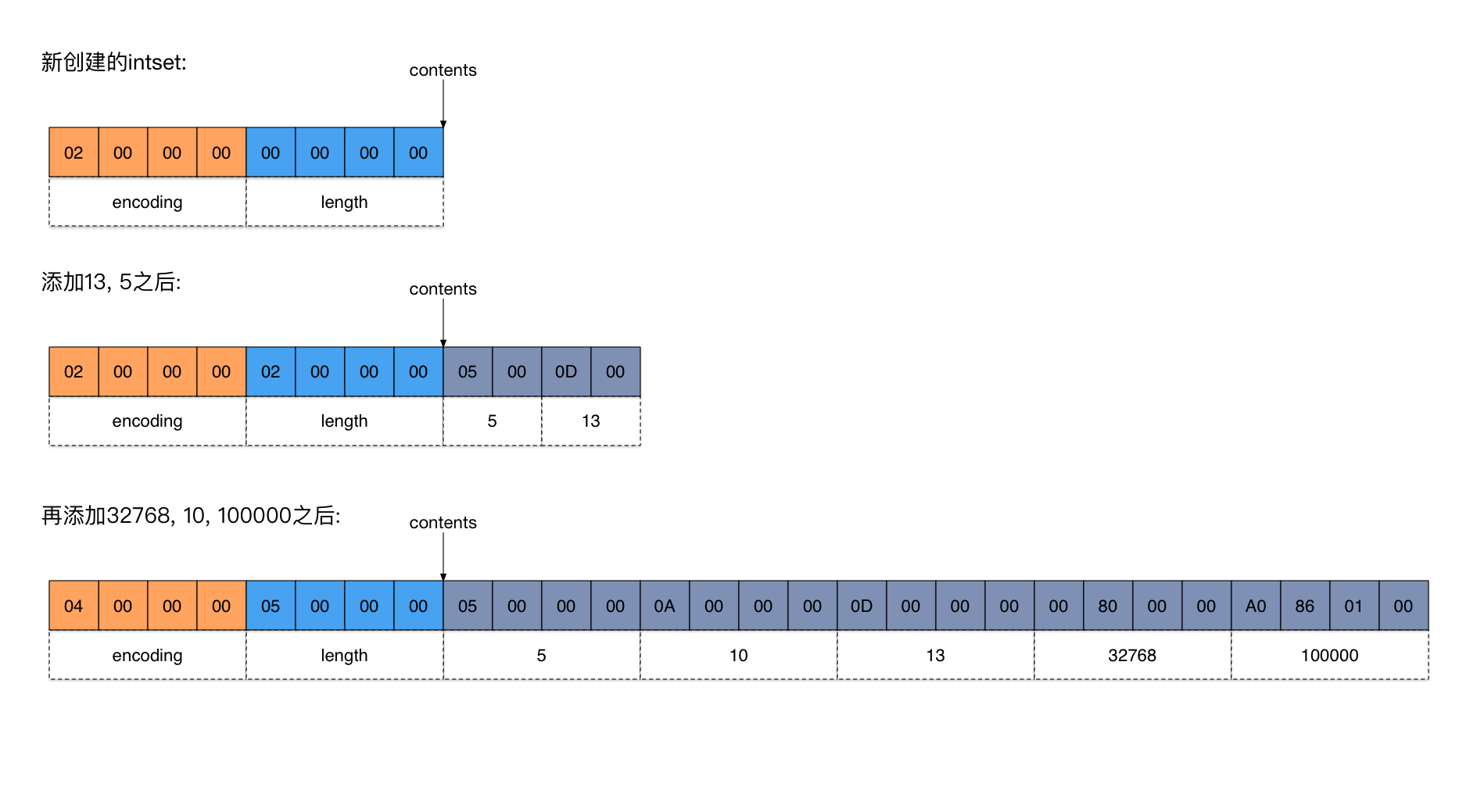
在上图中:
- 新创建的intset只有一个header,总共8个字节。其中
encoding= 2,length= 0。 - 添加13, 5两个元素之后,因为它们是比较小的整数,都能使用2个字节表示,所以
encoding不变,值还是2。 - 当添加32768的时候,它不再能用2个字节来表示了(2个字节能表达的数据范围是-215~215-1,而32768等于215,超出范围了),因此
encoding必须升级到INTSET_ENC_INT32(值为4),即用4个字节表示一个元素。 - 在添加每个元素的过程中,intset始终保持从小到大有序。
- 与ziplist类似,intset也是按小端(little endian)模式存储的(参见维基百科词条Endianness)。比如,在上图中intset添加完所有数据之后,表示
encoding字段的4个字节应该解释成0x00000004,而第5个数据应该解释成0x000186A0 = 100000。
intset与ziplist相比:
- ziplist可以存储任意二进制串,而intset只能存储整数。
- ziplist是无序的,而intset是从小到大有序的。因此,在ziplist上查找只能遍历,而在intset上可以进行二分查找,性能更高。
- ziplist可以对每个数据项进行不同的变长编码(每个数据项前面都有数据长度字段
len),而intset只能整体使用一个统一的编码(encoding)。
intset的查找和添加操作
要理解intset的一些实现细节,只需要关注intset的两个关键操作基本就可以了:查找(intsetFind)和添加(intsetAdd)元素。
intsetFind的关键代码如下所示(出自intset.c):
uint8_t intsetFind(intset *is, int64_t value) {
uint8_t valenc = _intsetValueEncoding(value);
return valenc <= intrev32ifbe(is->encoding) && intsetSearch(is,value,NULL);
}
static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) {
int min = 0, max = intrev32ifbe(is->length)-1, mid = -1;
int64_t cur = -1;
/* The value can never be found when the set is empty */
if (intrev32ifbe(is->length) == 0) {
if (pos) *pos = 0;
return 0;
} else {
/* Check for the case where we know we cannot find the value,
* but do know the insert position. */
if (value > _intsetGet(is,intrev32ifbe(is->length)-1)) {
if (pos) *pos = intrev32ifbe(is->length);
return 0;
} else if (value < _intsetGet(is,0)) {
if (pos) *pos = 0;
return 0;
}
}
while(max >= min) {
mid = ((unsigned int)min + (unsigned int)max) >> 1;
cur = _intsetGet(is,mid);
if (value > cur) {
min = mid+1;
} else if (value < cur) {
max = mid-1;
} else {
break;
}
}
if (value == cur) {
if (pos) *pos = mid;
return 1;
} else {
if (pos) *pos = min;
return 0;
}
}
关于以上代码,我们需要注意的地方包括:
intsetFind在指定的intset中查找指定的元素value,找到返回1,没找到返回0。_intsetValueEncoding函数会根据要查找的value落在哪个范围而计算出相应的数据编码(即它应该用几个字节来存储)。- 如果
value所需的数据编码比当前intset的编码要大,则它肯定在当前intset所能存储的数据范围之外(特别大或特别小),所以这时会直接返回0;否则调用intsetSearch执行一个二分查找算法。 intsetSearch在指定的intset中查找指定的元素value,如果找到,则返回1并且将参数pos指向找到的元素位置;如果没找到,则返回0并且将参数pos指向能插入该元素的位置。intsetSearch是对于二分查找算法的一个实现,它大致分为三个部分:- 特殊处理intset为空的情况。
- 特殊处理两个边界情况:当要查找的
value比最后一个元素还要大或者比第一个元素还要小的时候。实际上,这两部分的特殊处理,在二分查找中并不是必须的,但它们在这里提供了特殊情况下快速失败的可能。 - 真正执行二分查找过程。注意:如果最后没找到,插入位置在
min指定的位置。
- 代码中出现的
intrev32ifbe是为了在需要的时候做大小端转换的。前面我们提到过,intset里的数据是按小端(little endian)模式存储的,因此在大端(big endian)机器上运行时,这里的intrev32ifbe会做相应的转换。 - 这个查找算法的总的时间复杂度为O(log n)。
而intsetAdd的关键代码如下所示(出自intset.c):
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 1;
/* Upgrade encoding if necessary. If we need to upgrade, we know that
* this value should be either appended (if > 0) or prepended (if < 0),
* because it lies outside the range of existing values. */
if (valenc > intrev32ifbe(is->encoding)) {
/* This always succeeds, so we don't need to curry *success. */
return intsetUpgradeAndAdd(is,value);
} else {
/* Abort if the value is already present in the set.
* This call will populate "pos" with the right position to insert
* the value when it cannot be found. */
if (intsetSearch(is,value,&pos)) {
if (success) *success = 0;
return is;
}
is = intsetResize(is,intrev32ifbe(is->length)+1);
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1);
}
_intsetSet(is,pos,value);
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}
关于以上代码,我们需要注意的地方包括:
intsetAdd在intset中添加新元素value。如果value在添加前已经存在,则不会重复添加,这时参数success被置为0;如果value在原来intset中不存在,则将value插入到适当位置,这时参数success被置为0。- 如果要添加的元素
value所需的数据编码比当前intset的编码要大,那么则调用intsetUpgradeAndAdd将intset的编码进行升级后再插入value。 - 调用
intsetSearch,如果能查到,则不会重复添加。 - 如果没查到,则调用
intsetResize对intset进行内存扩充,使得它能够容纳新添加的元素。因为intset是一块连续空间,因此这个操作会引发内存的realloc(参见http://man.cx/realloc)。这有可能带来一次数据拷贝。同时调用intsetMoveTail将待插入位置后面的元素统一向后移动1个位置,这也涉及到一次数据拷贝。值得注意的是,在intsetMoveTail中是调用memmove完成这次数据拷贝的。memmove保证了在拷贝过程中不会造成数据重叠或覆盖,具体参见http://man.cx/memmove。 intsetUpgradeAndAdd的实现中也会调用intsetResize来完成内存扩充。在进行编码升级时,intsetUpgradeAndAdd的实现会把原来intset中的每个元素取出来,再用新的编码重新写入新的位置。- 注意一下
intsetAdd的返回值,它返回一个新的intset指针。它可能与传入的intset指针is相同,也可能不同。调用方必须用这里返回的新的intset,替换之前传进来的旧的intset变量。类似这种接口使用模式,在Redis的实现代码中是很常见的,比如我们之前在介绍sds和ziplist的时候都碰到过类似的情况。 - 显然,这个
intsetAdd算法总的时间复杂度为O(n)。
Redis的set
为了更好地理解Redis对外暴露的set数据结构,我们先看一下set的一些关键的命令。下面是一些命令举例:
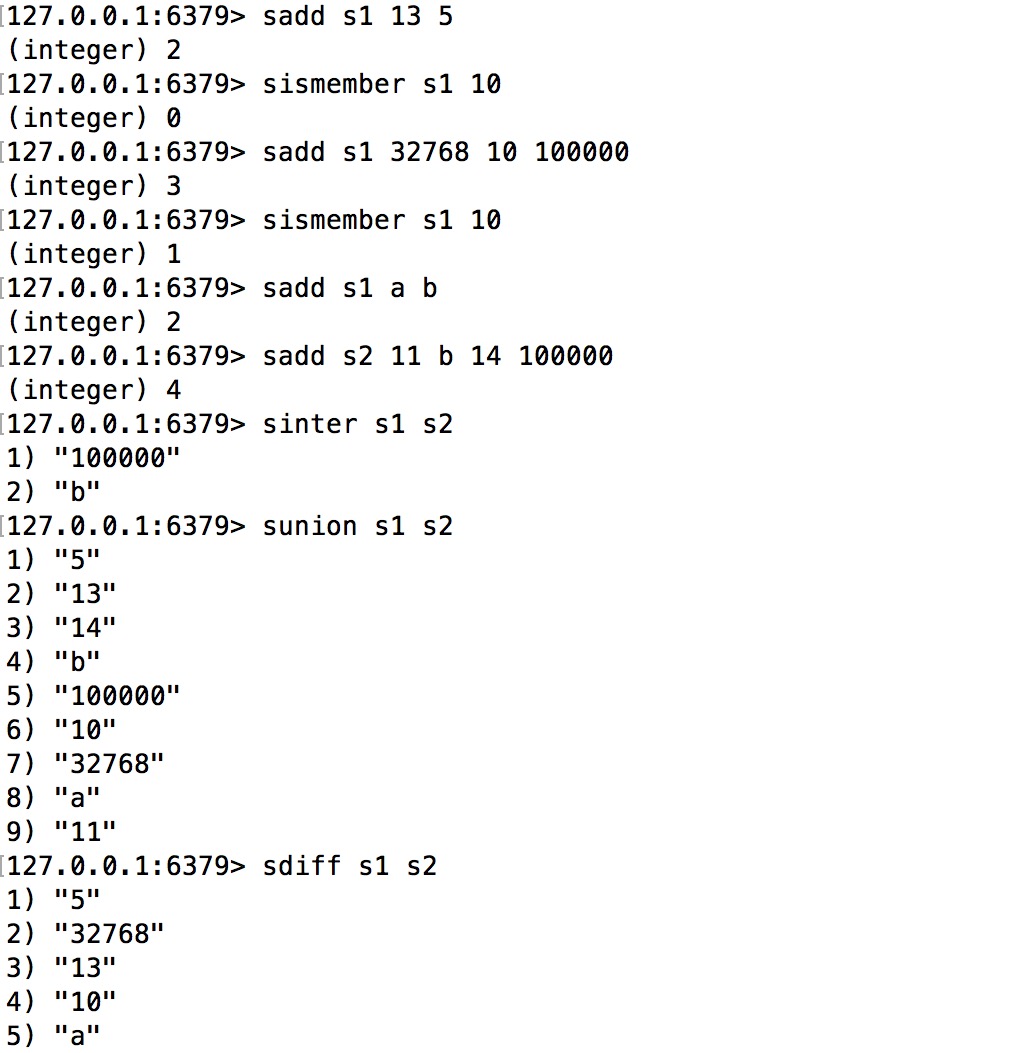
上面这些命令的含义:
sadd用于分别向集合s1和s2中添加元素。添加的元素既有数字,也有非数字(”a”和”b”)。sismember用于判断指定的元素是否在集合内存在。sinter,sunion和sdiff分别用于计算集合的交集、并集和差集。
我们前面提到过,set的底层实现,随着元素类型是否是整型以及添加的元素的数目多少,而有所变化。例如,具体到上述命令的执行过程中,集合s1的底层数据结构会发生如下变化:
- 在开始执行完
sadd s1 13 5之后,由于添加的都是比较小的整数,所以s1底层是一个intset,其数据编码encoding= 2。 - 在执行完
sadd s1 32768 10 100000之后,s1底层仍然是一个intset,但其数据编码encoding从2升级到了4。 - 在执行完
sadd s1 a b之后,由于添加的元素不再是数字,s1底层的实现会转成一个dict。
我们知道,dict是一个用于维护key和value映射关系的数据结构,那么当set底层用dict表示的时候,它的key和value分别是什么呢?实际上,key就是要添加的集合元素,而value是NULL。
除了前面提到的由于添加非数字元素造成集合底层由intset转成dict之外,还有两种情况可能造成这种转换:
- 添加了一个数字,但它无法用64bit的有符号数来表达。intset能够表达的最大的整数范围为-264~264-1,因此,如果添加的数字超出了这个范围,这也会导致intset转成dict。
- 添加的集合元素个数超过了
set-max-intset-entries配置的值的时候,也会导致intset转成dict(具体的触发条件参见t_set.c中的setTypeAdd相关代码)。
对于小集合使用intset来存储,主要的原因是节省内存。特别是当存储的元素个数较少的时候,dict所带来的内存开销要大得多(包含两个哈希表、链表指针以及大量的其它元数据)。所以,当存储大量的小集合而且集合元素都是数字的时候,用intset能节省下一笔可观的内存空间。
实际上,从时间复杂度上比较,intset的平均情况是没有dict性能高的。以查找为例,intset是O(log n)的,而dict可以认为是O(1)的。但是,由于使用intset的时候集合元素个数比较少,所以这个影响不大。
Redis set的并、交、差算法
Redis set的并、交、差算法的实现代码,在t_set.c中。其中计算交集调用的是sinterGenericCommand,计算并集和差集调用的是sunionDiffGenericCommand。它们都能同时对多个(可以多于2个)集合进行运算。当对多个集合进行差集运算时,它表达的含义是:用第一个集合与第二个集合做差集,所得结果再与第三个集合做差集,依次向后类推。
我们在这里简要介绍一下三个算法的实现思路。
交集
计算交集的过程大概可以分为三部分:
- 检查各个集合,对于不存在的集合当做空集来处理。一旦出现空集,则不用继续计算了,最终的交集就是空集。
- 对各个集合按照元素个数由少到多进行排序。这个排序有利于后面计算的时候从最小的集合开始,需要处理的元素个数较少。
- 对排序后第一个集合(也就是最小集合)进行遍历,对于它的每一个元素,依次在后面的所有集合中进行查找。只有在所有集合中都能找到的元素,才加入到最后的结果集合中。
需要注意的是,上述第3步在集合中进行查找,对于intset和dict的存储来说时间复杂度分别是O(log n)和O(1)。但由于只有小集合才使用intset,所以可以粗略地认为intset的查找也是常数时间复杂度的。因此,如Redis官方文档上所说(http://redis.io/commands/sinter),sinter命令的时间复杂度为:
O(N*M) worst case where N is the cardinality of the smallest set and M is the number of sets.
并集
计算并集最简单,只需要遍历所有集合,将每一个元素都添加到最后的结果集合中。向集合中添加元素会自动去重。
由于要遍历所有集合的每个元素,所以Redis官方文档给出的sunion命令的时间复杂度为(http://redis.io/commands/sunion):
O(N) where N is the total number of elements in all given sets.
注意,这里同前面讨论交集计算一样,将元素插入到结果集合的过程,忽略intset的情况,认为时间复杂度为O(1)。
差集
计算差集有两种可能的算法,它们的时间复杂度有所区别。
第一种算法:
- 对第一个集合进行遍历,对于它的每一个元素,依次在后面的所有集合中进行查找。只有在所有集合中都找不到的元素,才加入到最后的结果集合中。
这种算法的时间复杂度为O(N*M),其中N是第一个集合的元素个数,M是集合数目。
第二种算法:
- 将第一个集合的所有元素都加入到一个中间集合中。
- 遍历后面所有的集合,对于碰到的每一个元素,从中间集合中删掉它。
- 最后中间集合剩下的元素就构成了差集。
这种算法的时间复杂度为O(N),其中N是所有集合的元素个数总和。
在计算差集的开始部分,会先分别估算一下两种算法预期的时间复杂度,然后选择复杂度低的算法来进行运算。还有两点需要注意:
- 在一定程度上优先选择第一种算法,因为它涉及到的操作比较少,只用添加,而第二种算法要先添加再删除。
- 如果选择了第一种算法,那么在执行该算法之前,Redis的实现中对于第二个集合之后的所有集合,按照元素个数由多到少进行了排序。这个排序有利于以更大的概率查找到元素,从而更快地结束查找。
对于sdiff的时间复杂度,Redis官方文档(http://redis.io/commands/sdiff)只给出了第二种算法的结果,是不准确的。
系列下一篇待续,敬请期待。
(完)
其它精选文章:
- Redis内部数据结构详解(6)——skiplist
- Redis内部数据结构详解(5)——quicklist
- Redis内部数据结构详解(4)——ziplist
- Redis内部数据结构详解(3)——robj
- Redis内部数据结构详解(2)——sds
- Redis内部数据结构详解(1)——dict
- 小白的数据进阶之路
- 互联网风雨十年,我所经历的技术变迁
- 你需要了解深度学习和神经网络这项技术吗?
- 技术的正宗与野路子
- 论人生之转折
- Android端外推送到底有多烦?
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-redis-intset.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。

最新文章
- 为什么agent和workflow可以融合在同一个架构里?
- 万字长文!两栖模式构建Agent,与OpenClaw/Hermes不一样的解法——开源AmphiLoop
- Claude Managed Agents意味着什么?
- 【开源】专为「探路+编码」范式设计的全新浏览器工具集+Skills
- 不用手写一行代码,10分钟立等可取,爬取twitter和github动态
- 使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
- 过年了,聊聊AI和人文
- 使用Bridgic长程自主模块+MCP,控制你的浏览器
- AI智能体纪元或将从2026开始归零
- 从Python异步编程的剖析中体会智能体并发编程模式