开发AI Agent到底用什么框架——LangGraph VS. LlamaIndex
2025-06-15
如何开发AI Agent,存在不同的工程体系。当前正处于群雄混战的「战国」时代。在这种「乱局」下,AI从业者如何选择,就需要更审慎的思考。
今天我们来讨论一下两个具体的开发框架,LangGraph和LlamaIndex,结合上篇我们对Agent概念本质的剖析,来做一个提纲挈领(而非细节)的对比。
市面上的AI开发框架远不止这两个,而且在Agent开发之外,LangGraph和LlamaIndex也都包含了众多其他的能力。之所以本篇我选择这两个框架进行对比,一个是因为它们都算是AI时代「老牌」的框架了,使用者广泛;另一个则是因为篇幅有限,我们需要一个一个地来聊。
本文集中精力讨论清楚三件事:
- LangGraph和LlamaIndex各自对agent的抽象是什么?这反映了他们的底层设计哲学和世界观。
- 在LangGraph和LlamaIndex之上,分别如何搭建multi-agent的Agentic System?
- 在几个关键特性上(如状态管理、接口易用性、对并发及streaming的支持等),简要对比一下LangGraph和LlamaIndex。
两个框架对于Agent的抽象
根据我们上一篇的讨论,业界对于agent的理解,基本上有了一个初步的共识:Workflow和Autonomous Agent之间并不存在「非黑即白」的界限。不过呢,由于以前大家约定俗成的一些用词习惯,当人们提到Workflow的时候,就倾向于理解成那种提前定义好的、每一步都按照预定计划精准执行的工作流;而当人们提到Agent的时候,就倾向于理解成具有高度自主性的系统。所以说,有人发明了一个新的词,用Agentic System一词来表示所有具备一定自主程度的系统,这个概念既包含了Workflow又包含了Agent,以及介于两者之间的东西。
在关于Agentic System这一统一概念的认知上,LangGraph和LlamaIndex是基本一致的[1][2]。但是,在具体的实现机制的层面,LangGraph和LlamaIndex则采取了完全不同的抽象方式。
先来聊聊LangGraph。
LangGraph是在LangChain之后全新设计的一套框架和平台,代表了LangChain团队全新的思维模式。所以说,在推进Workflow和Agent的融合上,LangGraph可以说已经将革命进行到底了。LangGraph在底层构建了一套基于「图」的编排框架,上层不管是Workflow还是Multi-Agent系统,都能基于这个「图」编排出来。
为什么抽象成图呢?一般来说,传统的Workflow大部分情况下都能用一个DAG (Directed Acyclic Graph) 来表达。但是,复杂的控制流(特别是自主性的Agent),必定会产生执行循环。这就不是一个DAG能够表达的了。
图是由节点和边组成的。在Agentic System的构建中,节点可以执行任意的逻辑,既包括精确的程序逻辑,也包括基于LLM的动态决策逻辑。边则表达了节点之间的执行顺序(一种偏序关系)。
底层统一成一个基于「图」的编排框架,而上层创生出各种各样的Agentic System,听起来是很美好的架构。为了能达到这个目的,就要求这个图的编排具备很多关键的能力。比如:
- 能够指定节点之间的偏序执行关系。
- 能够在节点之间传递或共享数据。
- 能够让某些节点并发执行,并在并发结束后同步 (sync) 执行结果。
- 还有很重要的一点:能够执行动态的逻辑,甚至动态地产生偏序关系,这样才能出现循环(这一点我们稍后再详述)。
LlamaIndex的情况则有点复杂。
在LlamaIndex在官方文档中[2],它把Agentic System严格分为两类:一类是高度自主的系统,称为Agent[3];一类是开发者可以有更多精确控制和自定义的系统,称为Workflow[4]。给人的感觉是,LlamaIndex的「Agent」和「Workflow」是两套完全不同的系统,它们可能是基于两套完全不同的底层架构来构建的。
但LlamaIndex可能正处于演变之中,这使得这个问题有点复杂。我们来讨论一个具体的例子。我们知道,基于ReAct模式[5]的Agent,我们一般认为是一个高度自主的系统。它在一个agent loop中循环迭代,借助LLM动态决策,自动调用适当的工具并存取恰当的记忆。每经过一次循环,就向着任务目标前进一步。作为高度自主系统的典型代表,ReActAgent在LlamaIndex中存在三种不同的实现,分别是:
llama_index.core.agent.legacy.react.base.ReActAgent
llama_index.core.agent.react.ReActAgent
llama_index.core.agent.workflow.ReActAgent
上面第一个ReActAgent,已经标记了「legacy」。而第三个ReActAgent,则已经放在了「workflow」的package下面。我们可以猜测:LlamaIndex似乎正在逐步将它的agent实现迁移到一个统一的Workflow系统上面去。这听起来有点奇怪,可能需要解释一下。
LlamaIndex的Workflow系统(具体代码参考llama_index.core.workflow.Workflow),其实也是一个比较完备的编排系统。按照官方文档的介绍[4],LlamaIndex的Workflow是一个事件驱动的 (event-driven) 的系统,每个Workflow由多个step组成,而每个step负责处理一些事件同时发出一些新的事件。通过一个具体例子我们会看得更清楚一些(下图出自[6]):
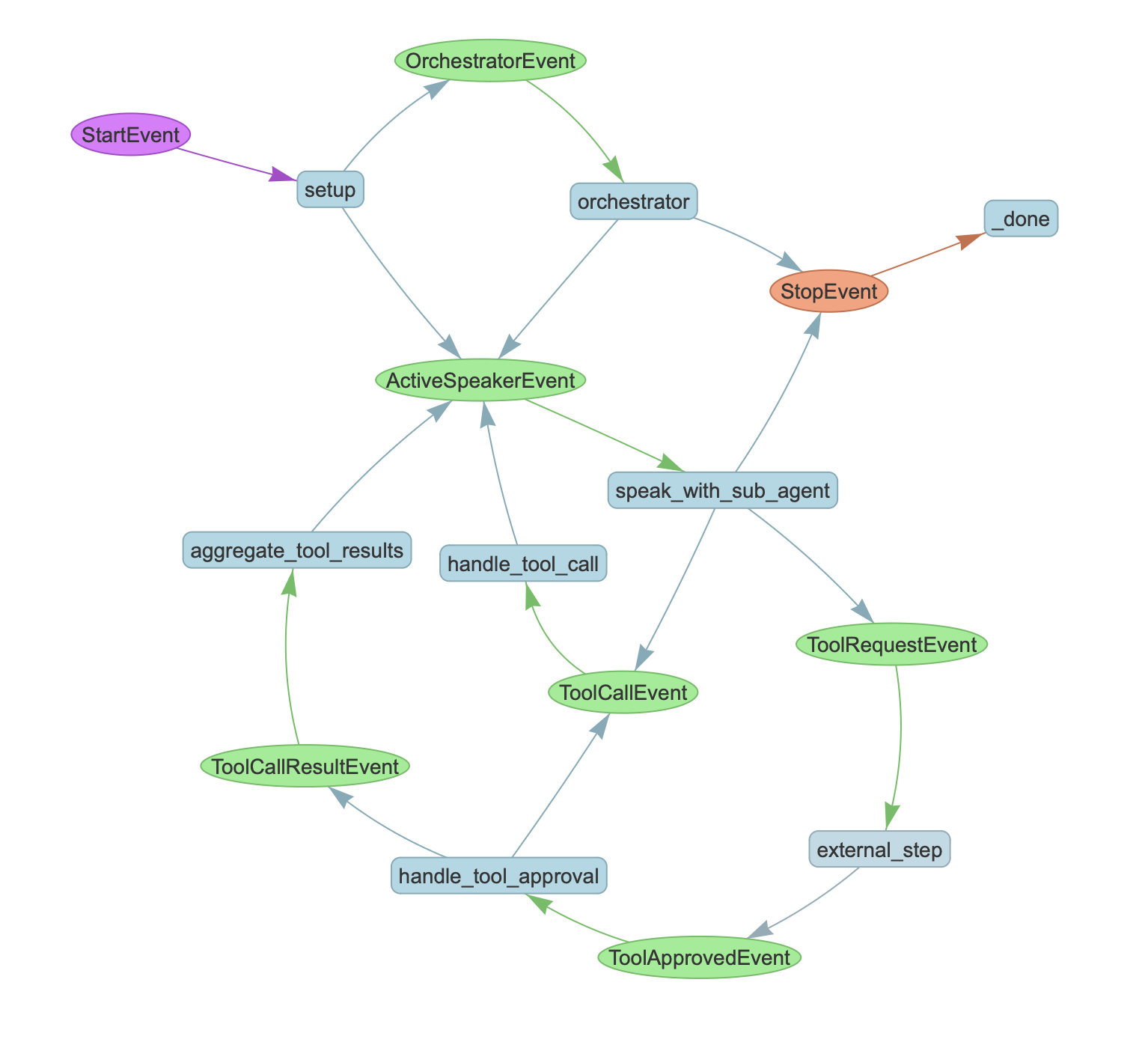
显然,依据上图,LlamaIndex的Workflow实际上也是一个由节点和边组成的图。在上图中,圆角矩形的节点,就对应了step,它代表某种执行逻辑;而椭圆形的绿色节点,则对应了事件,它指明了执行节点之间的偏序关系。由此可见,LlamaIndex的Workflow这个词,与业界对Workflow的主流概念不同。它实际上是一套通用的基于图的编排框架,具备不同程度自主性的Agentic System也都可以基于这个Workflow框架来构建,只是官方文档的指引上[2]似乎有些误导读者。
简单总结一下:
- LlamaIndex对Agentic System的抽象可以概括为,上层将高度自主的Agent和精确控制+自定义的Workflow区分开来;但底层趋向于是一个统一的事件驱动的编排系统,每个执行节点称为一个step,而事件传递的方向指明了step节点之间的偏序关系(没有显式地定义「边」的概念)。
- LangGraph对Agentic System的抽象可以概括为,从设计之初就追求底层基于统一的编排系统,这个系统显式地定义了节点 (node) 和边 (edge) 的概念,节点负责执行,边则指明了执行节点之间的偏序关系。
根据这个总结,似乎LlamaIndex和LangGraph底层的编排系统大同小异,但实则不然。它们从概念抽象到实现细节,都差异很大。
LangGraph严格参考了谷歌的Pregel分布式图计算架构[7],它的整体驱动逻辑是这样的:节点之间可以发送消息,执行过程分成若干个的superstep。在每个superstep内,收到消息的所有节点完成执行,执行过程中可能发出新的消息,新的消息直到下一个superstep才能被接收节点可见。像这样,系统一个superstep一个superstep地运行,直到没有任何节点收到消息时,系统停止。
在Pregel的执行模式下,可能有时候会出现一点出人意料的执行结果,比如下面这个图:
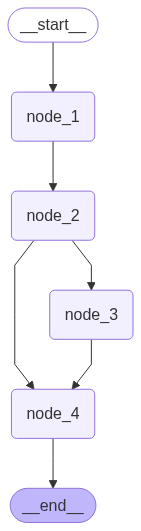
这个图的执行顺序是:
node_1 -> node_2 -> node_3 -> node_4 -> node_4
你会发现,node_4执行了两次。因此,这个图并不是一个简单的DAG (Directed Acyclic Graph) 。
如果你想让node_4等待node_2和node_3执行完才执行(只执行一次),那么你应该通过下列调用来显式地指明这个等待关系:
graph_builder.add_edge(["node_2", "node_3"], "node_4")
而LlamaIndex的编排系统,则是由事件来驱动的。一个事件会驱动一个step执行,而step执行时可能会发出新的事件,继而又驱动其他step执行。它没有显式地定义「边」的概念。
如果我们继续紧追不舍地去追问:为什么LangGraph和LlamaIndex都基本上能做到用一个统一的底层编排系统来支持各种自主程度不同的Agentic System?这个问题涉及到我们在上一篇聊到的一个根本问题,不同程度的自主性,本质意味着什么?按照之前的讨论,这个本质在于系统编排的执行路径是在何时决策的。静态编排的执行路径是完全提前确定好的,不具有太多自主性。自主性必然要求某种程度的动态编排特性才能支持。
再回过来看LangGraph和LlamaIndex的编排系统。他们都有一个重要特性:能够在执行过程中动态地改变节点偏序关系。在LangGraph中,这是通过节点在superstep末尾发送动态消息做到的,而在LlamaIndex中则是通过每个step节点动态地发送事件做到的。换句话说,它们都具有动态编排的特性。对比一下,类似Dify那样,在程序执行之前就可视化地编排出整个Workflow的系统,对于自主系统的支持则是非常有限的。
当深入到这个抽象层次上来看,LangGraph和LlamaIndex的编排系统,虽然它们暴露的编程接口、实现的完备程度、对于概念的抽象都完全不同,但最最底层的逻辑又是殊途同归的。
两个框架对于multi-agent的支持方式
当使用一个框架来实现某个具体的multi-agent系统的时候,需要把上层系统的概念同底层抽象概念有效对应起来。
使用LangGraph来支持multi-agent的方案,参见官方文档[8]。简单来讲就是下面这个图:
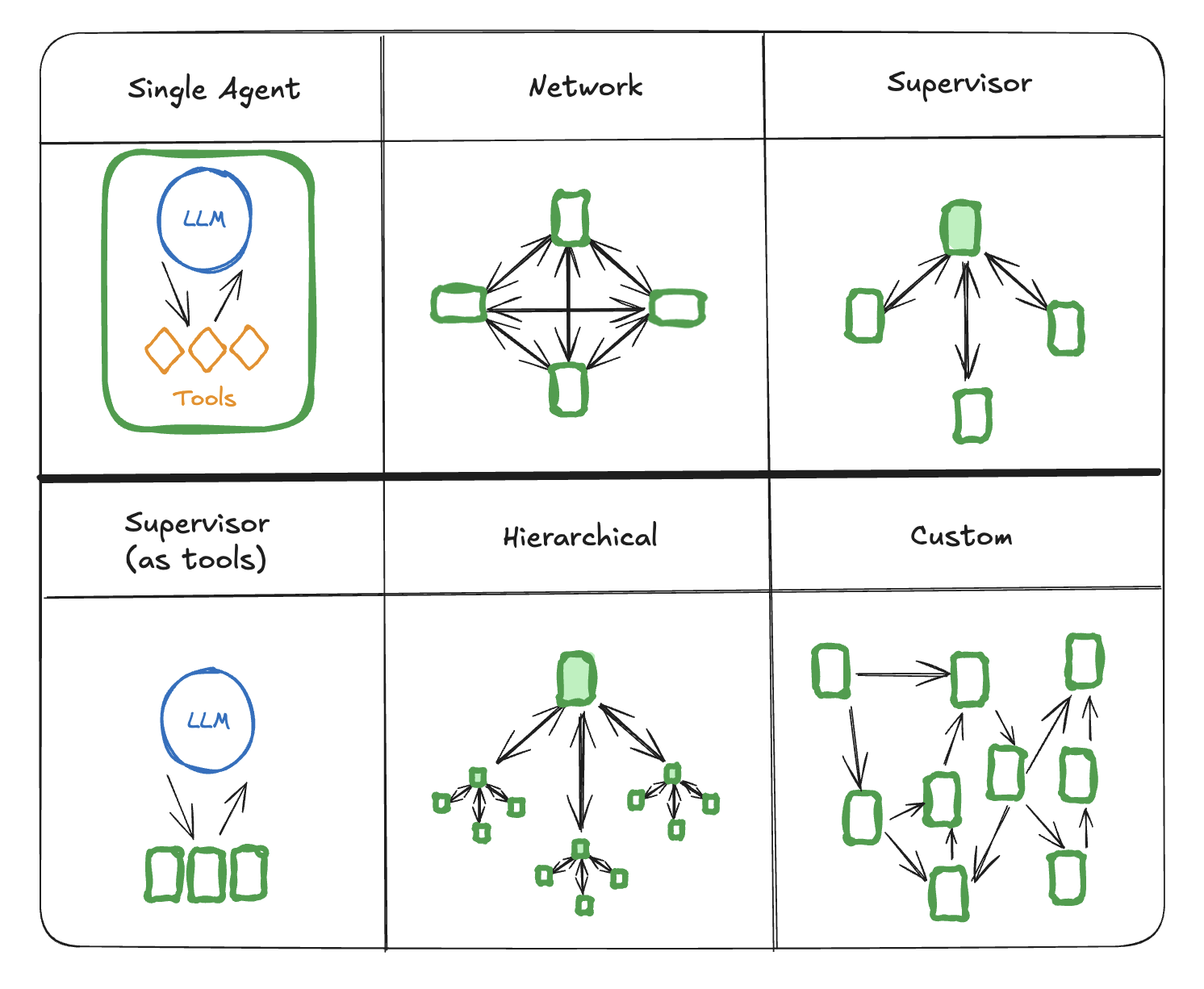
在这个图中,节点可以表示LLM,可以表示某个Tool,可以表示任意的一段程序执行逻辑,也可以表示一个完整的Agentic System子图(也就是可以嵌套子图)。
而使用LlamaIndex来支持multi-agent的方案,可以参见官方的一个repo[6]。这是一个使用LlamaIndex的Workflow系统来构建multi-agent的例子。虽然代码比较繁琐,但确实构建出来了。对应的可视化的step执行图,我们在前面已经见过了:
在这个图中,调用工具 (handle_tool_call) 、调用模型 (speak_with_sub_agent)、做路由分发 (orchestrator) ,等等这些逻辑,都使用一个step来实现(具体代码层面就是在方法上标注一个@step的decorator)。类似下面的代码片段:
class ConciergeAgent(Workflow):
@step
async def handle_tool_call(self, ctx: Context, ev: ToolCallEvent) -> ActiveSpeakerEvent:
...
对比两个框架的一些关键特性
(本小节涉及到一些编程细节,可按需阅读)
接口易用性
LlamaIndex的Workflow,只需要在方法上标注@step,就能创建出一个step,非常灵活易用。但是对于step之间的执行偏序关系没法直接指定,只能通过声明和匹配事件类型来隐式地指定,不是那么方便。
而LangGraph要求开发者显式地调用add_node、add_edge来构建执行图。这些用来构建图的代码,对于开发者的代码有一定的侵入,你需要去理解node、edge这些与你的业务逻辑无关的概念,并在代码中穿插调用它们。
另外,不管是LlamaIndex还是LangGraph,对于multi-agent的上层封装都不太够。
状态管理
LangGraph使用全局状态在节点之间共享数据;而LlamaIndex一方面使用event在step之间传递数据,一方面也支持通过全局状态来共享数据(以Context的形式)。这里的风险在于,对于复杂系统来说,全局状态通常易引发状态管理的混乱,开发者需要自己多加小心。
另外,LangGraph对于全局状态的更新,采取了一种基于reducer的通用方案。初学者往往不易理解。
并发
LangGraph和LlamaIndex的Workflow,都天然支持并发。因为它们都是异步驱动的,在每一个step或superstep执行期间,具备执行条件的多个节点天然是并发执行的。
而在多个节点并发执行结束后,同步 (sync) 等待执行结果的操作,LangGraph和LlamaIndex的Workflow采取了完全不同的方案。
在LangGraph中需要通过如下形式的调用,来指定框架内部的waiting_edge:
graph_builder.add_edge(["node_2", "node_3"], "node_4")
而在LlamaIndex的Workflow中,则需要使用Context来指明同时等待多个事件(Context同时承载了太多的逻辑)。代码示例如下:
data = ctx.collect_events(ev, [QueryEvent, RetrieveEvent])
对streaming的支持
LangGraph和LlamaIndex的Workflow,都允许通过async for的方式来深入到执行过程中去,这个能力被称为「streaming」。有一些常见的功能,比如汇报执行进度,就可以通过这种方式来实现。
在LangGraph中,可以通过async for逐步遍历各个superstep;而在LlamaIndex的Workflow中,则可以通过async for遍历各个事件。对streaming的支持,本质上是对于执行过程按照时间线性分步执行的一种追踪方式。这种在时间维度展开的线性遍历,在LangGraph中体现为superstep;在LlamaIndex的Workflow中则体现为每一步的驱动事件(称为streaming events)。
小结
LangGraph和LlamaIndex都是比较庞大的项目,今天我们只是讨论了它们各自的一小部分:关于agent开发的核心逻辑。而关于agent开发,值得讨论的话题还有很多很多,今天我们只是开了个头。
从某种程度上说,底层的设计哲学和世界观,基本定义了一个框架/项目/平台的边界。业界对于agent的认知,一直存在着两条主线:一个是充满理想的期待,希望AI能带来全方位的自我规划能力,充分释放AI的决策能力,彻底颠覆传统的软件生产方式;另一个则是务实的路线,把AI当成对传统Workflow升级换代的工具,让AI在监管和可控规则的框架下运转。
现在,随着AI向着产业落地的进程不断深入,两种路线正在以某种方式融合成一种新的东西。我们知道,理想是美好的,但同时也需要坚实的解决方案来支撑。当然了,以上都是一家之言,欢迎留言、转发。
(正文完)
参考文献:
- [1] How to think about agent frameworks.
- [2] Agents (LlamaIndex).
- [3] Agents (LlamaIndex).
- [4] Workflows (LlamaIndex).
- [5] Shunyu Yao, et al. 2022. ReAct: Synergizing Reasoning and Acting in Language Models.
- [6] An example of multi-agent orchestration with llama-index.
- [7] Grzegorz Malewicz, et al. 2010. Pregel: a system for large-scale graph processing.
- [8] Multi-agent systems (LangGraph).
其它精选文章:
- AI Agent的概念、自主程度和抽象层次
- 技术变迁中的变与不变:如何更快地生成token?
- DSPy下篇:兼论o1、Inference-time Compute和Reasoning
- 科普一下:拆解LLM背后的概率学原理
- 从GraphRAG看信息的重新组织
- 企业AI智能体、数字化与行业分工
- 三个字节的历险
- 分布式领域最重要的一篇论文,到底讲了什么?
- 漫谈分布式系统、拜占庭将军问题与区块链
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-ai-agent-langgraph-vs-llamaindex.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。
