浅谈DSPy和自动化提示词工程(上)
2024-11-30
隙中驹,石中火,梦中身。
周末不卷,忙里偷闲,写点技术。
如何与大模型有效地沟通,是一门艺术。
于是,摆在我们这个时代的人们面前的一个课题是:如何把这门艺术变成一个有迹可循的工程问题。今天,我们就一起聊聊自动提示词工程APE (Automated Prompt Engineering),并分析一个具体的开源实现DSPy[1],看看它到底是怎么“用魔法破除魔法”的。
由于篇幅比较长,所以我计划分成2~3篇文章来写。本篇我们先聊聊APE和DSPy中的基础概念,并通过一个具体程序的例子来解释DSPy的运行过程,借此获得一个直观的感受;在后面的文章中,我们再分析一下DSPy和APE的区别、类似的工程思路给我们带来的启示,以及可能存在的一些问题。
两大类提示词
对于不同角色的人来说,提示词 (Prompt) 这个概念的含义,可能还有些许的不同。为了讨论方便,我们可以把提示词粗略地分成两类:
- 普通聊天提示词。
- 系统开发提示词。
普通聊天提示词是针对普通用户来说的。一个用户通过聊天的方式与大模型产品交互,他需要用清晰的语言来描述他的问题,才能获得期望的答案。比如,你希望让大模型帮助写一篇中学生作文,这时候你就需要把作文的背景信息、你希望的立意、行文风格,甚至你希望描写的具体场景,以及其他一切写作要求,都完整清晰地表达出来。
也就是说,普通聊天提示词是用户自己写的,只要描述清楚当前特定任务的需求就可以了。
而系统开发提示词就不一样了,它是针对AI应用开发者(也就是工程师)来说的。工程师在编写程序、构建AI系统的过程中,将用户任务进行拆解,会在很多环节上需要与大模型进行交互,这就产生了提示词的编写工作。比如,对用户输入的query进行意图分类、实体提取、检索关键词扩展,等等,都是AI应用开发中常见的情形。
可见,系统开发提示词与普通聊天提示词有很大的不同,它是由工程师来写的,需要考虑某个场景中各种各样的用户可能的输入情况。因此,系统开发提示词需要更系统性地设计,需要考虑足够多的边界情况,需要提供稳定的准确率保障,其重要性与代码等同。
我们接下来要讨论的APE,显然是针对第二大类提示词——系统开发提示词来讲的。
APE和DSPy中的基础概念
在分析具体的DSPy程序之前,我们先来明确一下APE及DSPy中的一些基础概念。
什么是APE呢?简单来说,就是利用LLM来自动化地帮助我们生成提示词。
那么问题来了,我们怎么知道LLM生成的提示词好不好呢?它有没有满足我们的要求呢?因此,为了使用APE,我们必须要指定一个明确的metric。基于这个metric,我们能够自动化地评测当前所生成的提示词,它的性能表现达到什么程度了。当然,定义metric并不是一件容易的事,我们后面再讨论。
现在有了metric,那么它具体是在什么数据集上进行评测呢?为此,我们还需要提供一个标注好的数据集 (labelled dataset)。当然,在实际使用时,这个数据集会被划分为训练集、验证集、测试集。
APE是一个不断迭代的过程。每生成一个新版的prompt,它就会根据metric,在数据集上进行评测得到一个分数(score)。只要新版prompt比旧版本的prompt能够取得更高的分数,APE就可以不断重复这个过程,从而得到越来越好的prompt。
这个迭代过程颇有点「左脚踩右脚」的意味。而在迭代的开始,我们还需要提供一个初始的提示词 (initial prompt),作为优化迭代的起点。
另外,由于在APE中提示词是由LLM生成的,因此我们还需要一个为了生成新提示词而使用的提示词,称为meta-prompt。meta-prompt在APE中是一个非常重要的概念。
DSPy是一个开源框架,它包含了APE工程的大部分元素。但是,DSPy不仅仅是APE,这两者之间的区别我们在分析完DSPy的执行过程之后,在后面的文章中再讨论。
在进入DSPy的具体分析之前,我们先概要性地了解一下DSPy抽象出来的几个核心概念:
- Module:是一个DSPy程序的基本组成单元。一个Module具有明确的输入和输出定义,并且它调用LLM来实现从输入到输出的处理。一个DSPy程序本身就是一个Module,其内部又可以包含多个子Module;DSPy的优化器可以将同属一个DSPy程序内的多个Module放在一起进行优化迭代。这里的优化,其实一般就是指的对提示词进行优化,也就是前面说的APE。
- Signature:描述了一个Module的输入和输出,类似于函数的签名。Signature是DSPy中特有的一个概念。我们下面具体分析的时候再详细解释。
- Metric:我们前面提到过metric,在DSPy里,Metric被抽象为一个函数 (function) ,这个函数可以基于一个DSPy程序的输出和标注好的预期答案,计算出一个分数 (score) 。分数的计算方式,可以有很多种。
- Evaluate:在一个指定的数据集上逐个计算Metric,之后汇总计算出总体的评测分数。
- Optimizer:优化器。在DSPy中优化器的具体实现被称为Teleprompter。Teleprompter负责驱动整个DSPy程序进行迭代优化,它在每次迭代中参考来自各方面的信息(程序本身、数据集、旧版prompt及对应的评估分数等),运行某些优化策略为组成DSPy程序的每个Module生成新的prompt。
DSPy运行示例分析
在本节,我们来分析一个具体的DSPy程序的运行过程。这个程序来自DSPy的官方教程:https://dspy.ai/tutorials/rag/,它展示了一个典型的RAG程序如何使用DSPy框架进行优化。我们把这个RAG程序作为一个示例,逐步分析一下它主要的运行步骤和背后的原理。
程序的骨架代码如下:
# Part 1: 初始化LLM
lm = dspy.LM('openai/gpt-4o-mini')
dspy.configure(lm=lm)
# Part 2: 初始化数据集
with open('ragqa_arena_tech_500.json') as f:
data = ujson.load(f)
data = [dspy.Example(**d).with_inputs('question') for d in data]
random.shuffle(data)
trainset, valset, devset, testset = data[:50], data[50:150], data[150:300], data[300:500]
# Part 3: 初始化Metric和Evaluate
metric = SemanticF1()
evaluate = dspy.Evaluate(devset=testset, metric=metric, num_threads=8,
display_progress=True, display_table=2)
# Part 4: 初始化RAG module
# 检索的代码search,此处略去
class RAG(dspy.Module):
def __init__(self, num_docs=5):
self.num_docs = num_docs
self.respond = dspy.ChainOfThought('context, question -> response')
def forward(self, question):
context = search(question, k=self.num_docs)
return self.respond(context=context, question=question)
rag = RAG()
score_before_optimization = evaluate(rag)
# Part 5: 初始化Teleprompter并完成编译/优化
# dspy.MIPROv2是Teleprompter的子集
tp = dspy.MIPROv2(
metric=metric,
auto="light",
num_threads=8
)
optimized_rag = tp.compile(rag, trainset=trainset, valset=valset,
max_bootstrapped_demos=2, max_labeled_demos=2,
requires_permission_to_run=False)
score_after_optimization = evaluate(optimized_rag)
RAG程序骨架解析
以上RAG程序的骨架,大体由五部分组成。
第一部分,初始化LLM。在一个DSPy程序中(或者一个典型的APE程序中),用到LLM的地方一般来说有三个:
- (1)待优化的程序本身使用的LLM。也就是由Module来调用的LLM。当然,Module的各个子Module也都会调用LLM。
- (2)评测使用的LLM。也就是计算Metric时或由Evaluate来调用的LLM。
- (3)优化器使用的LLM。也就是由Teleprompter来调用的LLM。
这三处LLM在DSPy程序中可以分别指定。我们看到,以上示例代码只初始化了一个LLM实例,意味着这三个地方都使用同一个LLM实例。
至于DSPy支持的LLM模型类型,市面上常见的都能支持,包括OpenAI、Anthropic、Databricks各家公司的模型API,还有本地私有部署的LLM,以及OpenAI通过微软Azure提供的模型API。
第二部分,初始化数据集。可以看到,以上代码从文件ragqa_arena_tech_500.json中加载了一个数据集,并把数据集划分成了四部分:
- 训练集:trainset,包含50个example。DSPy的优化器会直接从训练集中进行学习。
- 验证集:valset,包含100个example。DSPy的优化器使用验证集来检查学习的进展。一般来说,trainset和valset是DSPy的Teleprompter优化器的两个重要的输入参数。
- 测试集:testset,包含200个example。用于对最终交付的程序进行整体性能上的评测。
- 开发集:devset,包含150个example。用于日常调试中对数据进行查看、分析。如果数据集资源有限,这个开发集应该也可以复用训练集的数据。但至少前面三个数据集是必需的。
DSPy程序的迭代优化,在对于数据集的使用上,与模型训练的过程非常类似。不过,深度学习模型的训练过程,一般要求训练集规模要大于验证集。但DSPy的prompt优化器要求相反。DSPy官方文档建议,在划分训练集和验证集时,划分比例可以按照20%和80%[2]。
对于数据集的具体规模,DSPy的官方文档也给出了一些具体建议[3]:
- 训练集和验证集最好各有30–300个example。
- 测试集和开发集最好各有30–1000个example。
为了更直观地感受数据集的情况,我们从devset中抽样查看一些example,如下:

可以看到,每个example有两个字段。一个是question,会作为程序的输入;另一个是response,表示期望的答案,相当于标注好的label。
第三部分,初始化Metric和Evaluate。我们前面提到了,定义metric并不是一件容易的事。DSPy框架为此提供了一些常见的metric。
在上面的代码中,我们使用了SemanticF1。它计算的是语义上的F1 score,也就是召回率 (recall) 和 准确率 (precision) 的调和平均数。
注意,这里的F1计算是针对单个example的。我们直观地验证一下,计算出某个example与它自身的F1 score(理论值是1),如下:

OK,这个分数非常接近1。
针对上面输入的devset[6]这个example,我们使用前面的RAG程序来预测一下输出(记为pred),然后再计算一下标注答案和预测输出之间的F1 score,如下:
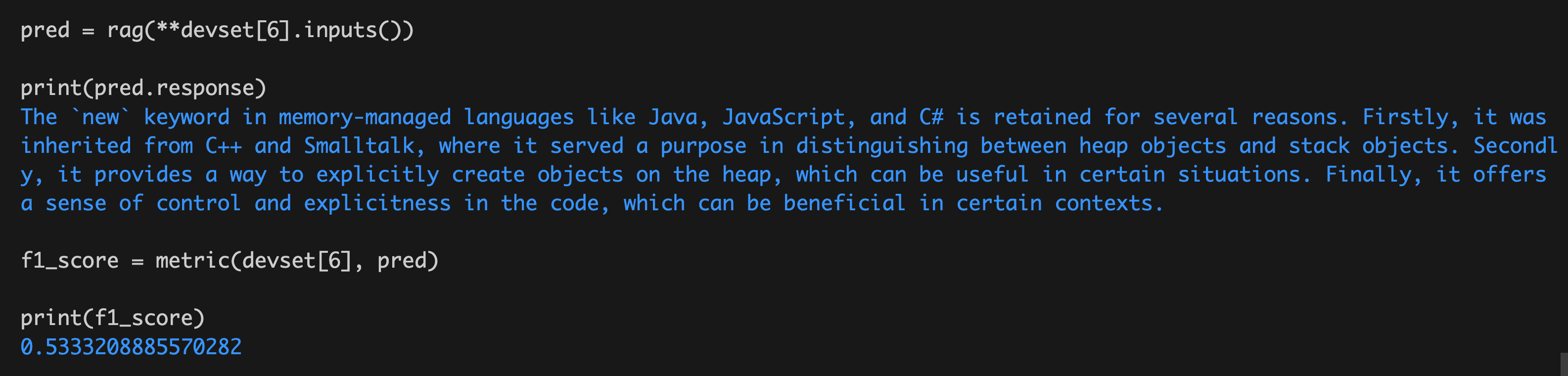
结果大概在0.53左右。
简单总结一下,以上metric计算了单个example中的期望答案和程序预测答案之间的F1 score;而Evaluate则用于针对测试集中每一条example分别计算F1 score,最后得出整体性能上的评测结果(平均值)。值得注意的是,在以上代码中,Evaluate初始化的时候,使用的测试集testset,与我们前面对数据集的用途描述相一致。
上面的F1 score是具体怎么计算出来的呢?如果我们翻看DSPy的代码会发现,SemanticF1的实现其实是调用了LLM来计算recall和precision的。还记得我们前面提到的“评测使用的LLM”吗?但是,在实际应用中,metric不一定非要用LLM来计算,你可以自定义自己的metric实现。
DSPy中也预定义了一系列常见的metric,比如:
from dspy.evaluate.metrics import answer_exact_match
from dspy.evaluate.metrics import answer_passage_match
from dspy.evaluate import SemanticF1
from dspy.evaluate import AnswerCorrectness
from dspy.evaluate import AnswerFaithfulness
你可以通过名字猜测一下各个metric的含义。但总体来说,DSPy目前对于这部分的封装算不上太好,它们与DSPy内的各个Teleprompter的兼容性也不好。在实际中你大概率需要实现自己的Metric,这里需要多加注意。
第四部分,初始化RAG module。以上代码定义了一个名字叫RAG的新module,这就是我们计划进行迭代优化的RAG程序。RAG这个module内部包含了一个子module,名字是respond,它使用CoT的方式调用LLM获得response。
DSPy的Module借鉴了pytorch中的nn.Module的概念抽象,在初始化的时候可以通过给属性赋值的方式来初始化子Module,而且一个Module实例可以被当做函数一样来调用。
第五部分,初始化Teleprompter并完成编译/优化。
这一部分是DSPy的核心。DSPy提供了多个优化器,MIPROv2是其中比较重要的一个。MIPROv2的具体算法实现出自论文[4]。它的实现分为三个大的执行步骤:
- Step 1: 通过Bootstrap的方式,生成或选出few-shot例子的候选集。
- Step 2: 生成prompt中的instruction的候选集。
- Step 3: 从候选集中选出最佳的few-shot和instruction组合。
这些步骤的具体实现过程比较复杂,我们放在下一篇介绍。
这里的代码有一点需要注意的是,调用tp.compile时传入的两个数据集,一个是trainset,一个是valset。这里使用了compile一词,实际上这个「编译」的过程,与模型训练的过程有很大的相似之处。
下一步
对于上面的代码,细心的读者可能还会产生一个疑问:为什么看不到调用LLM的prompt呢?而且,我们前面提到的那个非常重要的meta-prompt,为什么也没有在代码中看到呢?这实际上与DSPy的Signature机制的设计有关。
由于篇幅的关系,今天这篇先写到这里。在下一篇,我们将继续讨论两个遗留问题:
- 从Signature到Prompt的过程。
- MIPROv2的具体实现(三大步骤)。
(正文完)
参考文献:
- [1] DSPy: The framework for programming—not prompting—foundation models.
- [2] Optimization in DSPy.
- [3] Tutorial: Retrieval-Augmented Generation (RAG).
- [4] Krista Opsahl-Ong, Michael J Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, Omar Khattab. 2024. Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs.
其它精选文章:
- 技术变迁中的变与不变:如何更快地生成token?
- 科普一下:拆解LLM背后的概率学原理
- 用统计学的观点看世界:从找不到东西说起
- 从GraphRAG看信息的重新组织
- 企业AI智能体、数字化与行业分工
- 三个字节的历险
- 分布式领域最重要的一篇论文,到底讲了什么?
- 内卷、汉明问题与认知迭代
- 漫谈分布式系统、拜占庭将军问题与区块链
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-dspy-internals-1.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。

最新文章
- 为什么agent和workflow可以融合在同一个架构里?
- 万字长文!两栖模式构建Agent,与OpenClaw/Hermes不一样的解法——开源AmphiLoop
- Claude Managed Agents意味着什么?
- 【开源】专为「探路+编码」范式设计的全新浏览器工具集+Skills
- 不用手写一行代码,10分钟立等可取,爬取twitter和github动态
- 使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
- 过年了,聊聊AI和人文
- 使用Bridgic长程自主模块+MCP,控制你的浏览器
- AI智能体纪元或将从2026开始归零
- 从Python异步编程的剖析中体会智能体并发编程模式