AI Agent时代的软件开发范式
2025-07-19
大概一个多月之前,我们曾经深入讨论了AI Agent自主性的本质是什么。今天,我们沿着这个话题更进一步,去探究一下AI Agent的自主性这一本质特性,可能会对新时代的软件开发工作带来什么样的影响。
本文集中精力展开讨论三件事:
- AI Agent的自主性给传统软件开发带来了哪些新的期待和可能性?
- 范式的转变:从面向step到面向goal。
- 如何穿越「中间地带」?
再谈AI Agent的自主性
现在我们从软件开发的视角(也就是编程的视角)来重新思考一下「自主性」这个问题。
让我们短暂地忘掉LLM和AI Agent,暂时回到传统软件编程的世界。一个软件系统,一般来说底层是由很多模块 (module) 组装而成的。然后程序会把这些模块编排起来 (orchestrate) ,按照某种顺序来执行。也就是说,粗略来看,一个软件系统由两部分元素组成:
- 模块 (Module)。
- 编排 (Orchestration)。
先说一下编排。有开发经验的工程师都会知道,很多业务系统都存在一个「编排层」,这一层负责把众多模块「串」起来。工程师的很大一部分工作量,实际上都是在根据业务需求修改编排层的实现。正是这个编排层确定了程序的执行路径,并为系统引入了某种动态特性。
如果执行路径上的每一步 (step) 都是提前能确定好的,那么就属于静态编排;如果引入了分支逻辑 (if/else/switch) 和循环逻辑 (while或递归调用) ,那么程序就能够根据输入数据在运行时动态地确定执行路径,那么就属于动态编排。
可见,传统的软件编程方式天然就已经可以提供某种动态特性。那么,AI Agent带来了哪些新的能力,是传统的软件编程所不具备的呢?
表面上看,LLM输入一段文本,输出一段文本,封装后似乎跟传统的软件模块没有什么差别。但由于LLM的reasoning能力,它的输出一旦被解释成与执行决策有关的信息,就为AI Agent系统带来了某种「自主性」。这种自主性超越了传统软件编程所能够提供的动态特性,是一种巨大的差异。我们分两个方面细分来讨论:
- 一个是关于模块间编排的自主性。可能称为planning的自主性更形象一些。
- 第二个是关于模块内的自主性。
先说planning的自主性。我们借用博主Dex Horthy的一张图(出自[1])来说明:
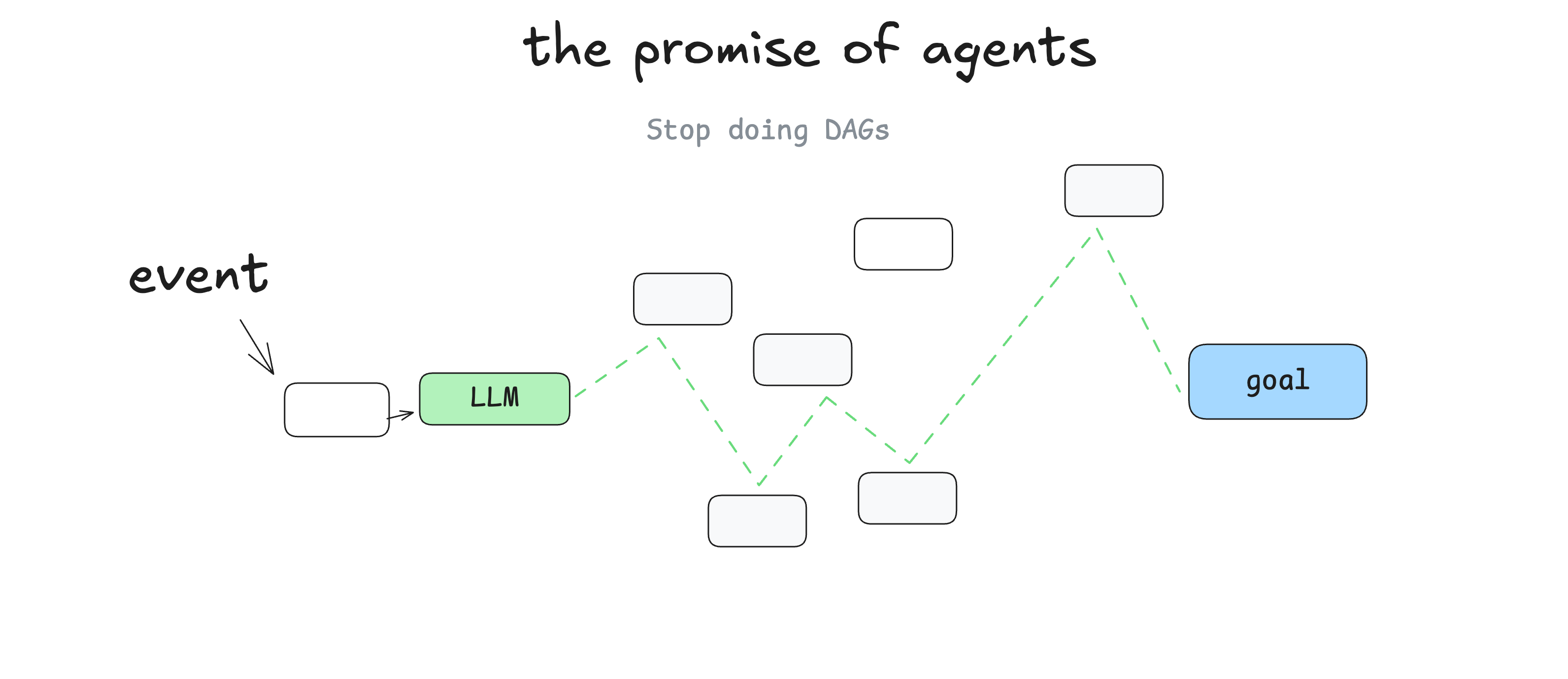
前面说的传统软件开发,不管是静态编排,还是动态编排,都需要工程师在编写代码的那一刻(也就是程序执行前)确定所有可能的执行路径。而这张图表明,在AI Agent时代,我们预期LLM的reasoning能力能够在众多的模块间动态地规划出一条执行路径。我们只需要提供一系列候选的可执行模块,而不再需要人工去编排路径。也就是说,工程师在编码的那一刻不需要考虑清楚可能的执行路径,执行路径可以在程序执行过程中根据执行动态现场确定。这种自主性程度显然超越了我们前面提到的动态编排了。实际上,编排的英文单词是orchestration,而这种高度自主的编排,称为planning可能更合适一些(典型的planning方案包括ReAct[2]、LLMCompiler[3])。
再审视一下模块内的情况。
如果把LLM调用封装成一个模块,而LLM的输出仅仅是作为一段待处理的数据交给后续模块来处理(比如生成了一段总结,或者一段文学描写),那么这样的模块和传统的软件模块并没有本质区别(区别仅在于准确率方面)。但是,如前所述,LLM的输出一旦被解释成与执行决策有关的信息,情况就不同了。至少有两种典型的编程模式,LLM的输出会影响到后续的执行决策:
- 一种是动态任务拆分。
在传统软件开发中,把一个复杂的任务拆分成多个简单的子任务来完成,也是一种很常见的策略。但是,以前工程师需要在编码时就明确任务如何拆分,比如拆分成几个子任务,每个子任务是什么,然后把每个子任务写代码实现出来。而LLM带来了「动态」的任务拆分,它可以基于输入数据现场拆分任务,并把拆分出来的子任务交给后续的LLM来继续执行。你在编码的那一刻无法预测任务拆分的细节,既不知道拆分后的子任务数量,也不知道每个子任务具体是什么。
在Anthropic的“Building effective agents”这篇blog[4]中提到的「Orchestrator-workers」这种Agent设计模式,就属于动态任务拆分。在各种Deep Research产品中以及类似Cursor、Devin的编程Agent中,就广泛地在使用这种设计模式。
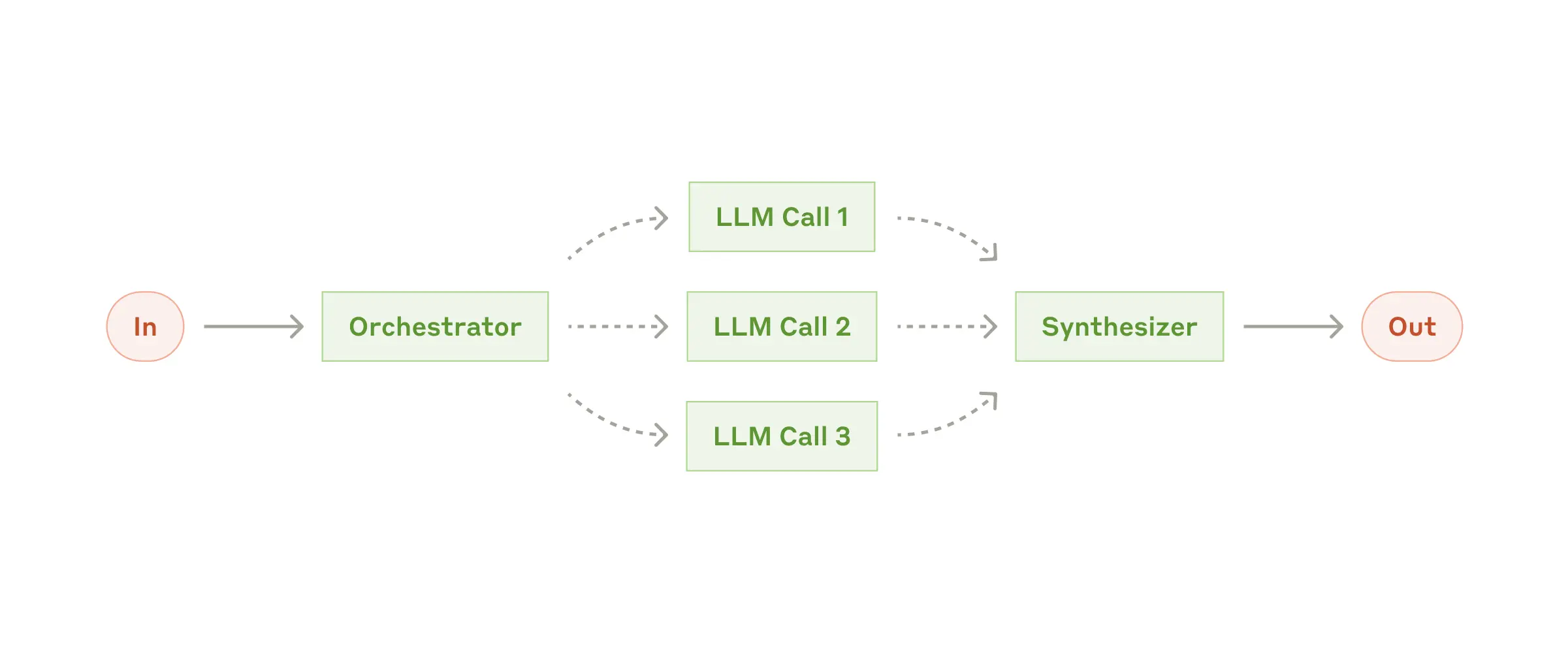
就像我们前面所说的,这时候LLM输出的信息(也就是关于子任务拆分的信息),不仅仅是作为程序加工处理的材料,它还影响了程序的执行决策,对程序后续的执行路径产生了影响。总之,动态任务拆分是一种典型的带来自主性的编程模式。
- 另一种是AI现场编码。
当没有现成的软件模块可供调用的时候,LLM根据程序输入数据,现场编写脚本代码(比如数据分析脚本、自动化测试脚本),并在沙箱中运行。LLM这种解决问题的方式,具备高度的定制化和自主性。
从更细粒度来说,AI编写的代码,内部也包含了对于执行路径的编排或planning。所以说,AI现场编码在planning的自主性和模块内的自主性两个方面,肯定都有一些体现。但是,对于工程师来说,由于AI编码模块更像一个黑盒,内部很难通过用人工编程的手段来控制了,所以我们暂且还是把它当做是模块内的自主性来看待。我们能做的是,小心地定义好它的自主性编程的边界。
讨论完planning的自主性和模块内的自主性之后,你可能会问:LLM带来的自主性给软件开发带来了什么好处呢?这就涉及到软件的开发成本问题。在传统的软件开发模式中,所有预设的逻辑都必须由人类工程师编码完成。大型的软件开发,最后就变成了一个堆人力的事情。在AI Agent时代,新的技术为我们描绘了一个更美好的未来:以前的预设逻辑(需要人力编程的逻辑),都已经内化到了模型中,现在我们只需要把它们诱发出来,去动态执行。具备高度自主性的AI Agent,它们或者基于现有的软件模块,组装出更复杂的软件系统(基于planning的自主性);或者基于用户需求现场生成高度定制化的代码。
把AI Agent类比成人类行为,把模块看成工具,想象存在这样的一种高度自主性的智能体,它不仅仅懂得利用工具,而且在需要的时候还能自己制造一个新工具出来,然后再解决问题。假设这种愿景成为现实,显然会极大地降低软件开发成本。而且不仅如此,还会为用户带来真正长尾的且低成本的定制化软件。
从面向step到面向goal
程序语言所描述的,本质上是个DAG (Directed Acyclic Graph) 或DG (Directed Graph) 。当有循环逻辑的时候,就是DG;没有循环的时候,就是DAG。
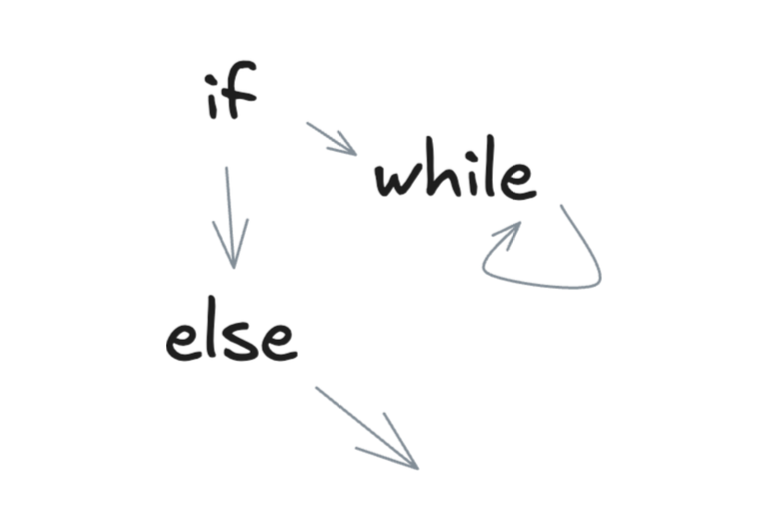
把程序看成一个DAG或DG来进行编排,不管是可视化编排,还是通过代码进行编排,在LLM出现之前其实早就存在了。同时,现在大多数Agent/Workflow框架(比如LangGraph、Dify、LlamaIndex等),也都是在基于DG/DAG解决编排问题。
所有这些方案的底层架构,是基于或至少「类似于」Pregel的 (谷歌总结出来的一种分布式图计算架构[5]) 。如果不考虑分布式计算的部分,Pregel在编排逻辑上跟手写代码的if/else、while本质上是一回事,因为工程师需要手工编码程序执行的每一个step。我们在上一篇文章《开发AI Agent到底用什么框架——LangGraph VS. LlamaIndex》中曾经讨论过,Pregel通过在每一个superstep末尾发送动态消息,让它具备了动态编排的特性。当然,所有可能的执行逻辑和可能的执行路径,是提前预设好的(在程序执行前确定好的)。
以上所有这些基于DG/DAG的编排方案,可以统称为Graph Orchestration(基于图的编排)。
我们现在的问题是,AI Agent的自主性(包括上一节提及的planning的自主性和模块内的自主性)对于软件开发有什么新的要求呢?或者换句话说,为了把AI Agent的自主性更好地发挥出来,我们是采用传统的Graph Orchestration就够了?还是说需要一个全新的编程范式?
我们再重温一下之前的文章中得到的一个重要结论:各种不同的Agentic System,它们所呈现出来的不同程度的自主性,本质在于系统编排的执行路径是在何时决策的。总共分成三种编排时机:
- 静态编排:执行路径的每一步都是提前确定好的。
- 程序动态编排:具体执行时的路径只能根据输入数据动态确定,但所有可能的执行路径都是提前确定好的。
- 自主编排(或者叫自主planning):没法提前设想所有的可能情况,执行路径也需要根据执行动态现场确定。
对比一下就会发现,这里的程序动态编排,就处于等同于Graph Orchestration的动态性水平层次上。而LLM带来的planning的自主性,是AI Agent时代软件开发中「新」的特性。
这种新的特性,呼吁一种编程范式的转变:从面向step到面向goal。这就好比,当你交给某个人一件任务,如果这个人能力比较弱,你就需要把具体每一步怎么干都明确告诉他;但如果这个人精明强干,那么你只需要把任务目标告诉他,具体怎么干你就完全不用管了。我们可以认为LLM具有某种程度的「智能」,所以跟它交流更自然的方式是告诉它目标 (goal) ,然后让它来编排具体的执行路径从而把任务完成。
有人可能会问,一个面向goal来描述的任务,难道不能使用Graph Orchestration实现出来吗?这个问题可能不存在「非黑即白」的答案。从一定程度上看,也许可以,但是你很可能需要在一个节点中塞进更多的逻辑(也就是把更多的动态逻辑代码放到节点内部去实现),也可能需要额外做一些很复杂的转换才行。这样做的结果,还会让工作在Graph Orchestration层面的编程框架真正起到的作用明显变弱。总之,我们在未来可能需要一种面向goal的编程范式,这样才符合第一性的表达。
AI Agent时代的很多任务其实本质上是面向goal来描述的。当我们意识到这一点的时候,也意味着一些编程方面的特殊要求。传统的面向step的任务,只要把每一步执行完,就算目标达成了。但是,面向goal的任务,即使我们能够把任务拆解成多步,这时候把每一步都执行完也仍然不能够说明目标达成了。成功执行完每一步,只能保证会输出某个结果,但并不能保证输出的效果一定是符合目标的。因此,面向goal的编程通常需要我们提供一个评估模块。
同时,面向goal的编程模式也可能带来一些潜在的好处。比如针对同一个目标,系统可能会发现多条执行路径,从而提供更多选择性;或者执行过程中出现错误的时候,系统也许可以动态找到其他执行路径,从而把错误绕过去。
中间地带
我们无疑正处于一个从传统技术向着AGI不断前进的历史进程当中。从确定性到自主性,从面向step到面向goal,这个历史进程可能会经历相当长的历史时期。所以说,我们大概率不是一下子到达高度自主性的AGI时代,而是长期处于一种「中间地带」。
承认我们处于「中间地带」,是一种务实的观点。反之,一味地宣称传统的软件开发模式完全被LLM技术颠覆了,拿极端的情况来概括全部,这种做法可能是吸引眼球的,却容易使人误入歧途。实际上,「中间地带」反而是最难应付的。当前,学术界、大型实验室,抛出的方案几乎都是偏向一个极端的。而留下了最难的部分,反而依靠企业一线交付人员去苦苦探索。这里就需要一些工程师的独特眼光,来帮助我们穿越「广大的」中间地带。
如何把面向step和面向goal的两种模式无缝地mix起来,对外提供出不同程度的自主性,就成为一个非常重要的问题。我们很难在这里给出完美的答案,但有些思路可供参考。我们可以把那些期望使用AI技术解决的问题分成两大类:
- 一类是具备发散性、启发性的任务。比如创作类、信息获取类的场景,包括问答、写作、Deep Research等等。对于这类任务,人们可以降低对于确定性的期望,根据实际需要来控制自主性的「度」。
- 另一类是具有确定性要求的任务。特别是一些需要在企业内部环境运行的to B任务,最终还是要提供确定性的控制。
对于后一类任务,又有两种解决思路(可以相互结合使用)。
第一个思路是限定范围。一个典型的例子是Dex Horthy提到的micro agents的概念[1]。如下图:
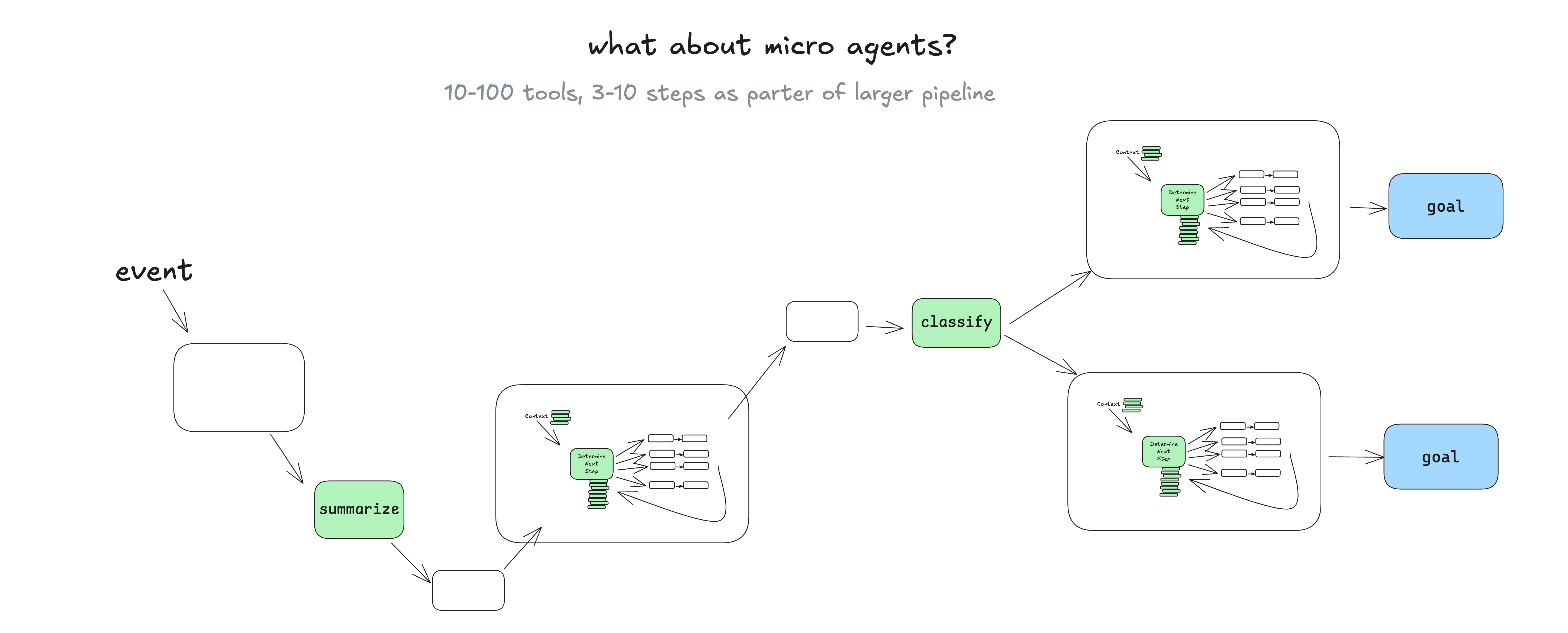
上图中有三个自主性的Agent loop,称为micro agents,被嵌入到了一个更大的DAG当中。通过限定micro agents发挥自主性的范围,将它们执行的确定性提升到一个可以接受的水平。
第二个思路则是human-in-the-loop机制。对于一些敏感的操作,Agent可以选择在获取人类的核准后再执行。相当于引入人工确认,来消除自主性带来的不确定性。沿着这个思路,未来的自主Agent可能会演变成一种Outer Loop[6]模式。它的意思是,这些Agent不再需要由人类来启动,它们可能是默默地随时运行在背后。想象一下,某个Agent始终在运行,它随时在监测客户邮件,或者随时监控财务数据。一旦它发现某种特殊事件发生,它就自动通过各种渠道(IM、短信、邮件等)去获取人类管理员的核准确认或者反馈。在这个human-in-the-loop的交互中,人类是被动牵涉其中的,人类被看做是Agent为了完成自主操作的其中一环。这个大的、把人类也牵涉其中的交互loop,就被称为Outer Loop。
(正文完)
参考文献:
- [1] Dex Horthy. How We Got Here: A Brief History of Software.
- [2] Shunyu Yao, et al. ReAct: Synergizing Reasoning and Acting in Language Models.
- [3] Sehoon Kim, et al. An LLM Compiler for Parallel Function Calling.
- [4] Building effective agents.
- [5] Grzegorz Malewicz, et al. 2010. Pregel: a system for large-scale graph processing.
- [6] HumanLayer GitHub Repo.
其它精选文章:
- 从Prompt Engineering到Context Engineering
- 开发AI Agent到底用什么框架——LangGraph VS. LlamaIndex
- AI Agent的概念、自主程度和抽象层次
- 技术变迁中的变与不变:如何更快地生成token?
- DSPy下篇:兼论o1、Inference-time Compute和Reasoning
- 科普一下:拆解LLM背后的概率学原理
- 从GraphRAG看信息的重新组织
- 企业AI智能体、数字化与行业分工
- 分布式领域最重要的一篇论文,到底讲了什么?
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-ai-agent-engineering-paradigm.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。
