浅谈DSPy和自动化提示词工程(中)
2024-11-30
一张琴,一壶酒,一溪云。
书接上回,接着写点技术。
在上一篇文章《浅谈DSPy和自动化提示词工程(上)》中,我们解析了一个典型DSPy优化程序的骨架代码。本篇我们继续分析两个遗留的关键问题:
- 从Signature到Prompt的过程。
- MIPROv2的具体实现。
从Signature到Prompt
在DSPy的官网[1]和Github主页[2]上,第一句话是这样介绍DSPy的:
DSPy is the framework for programming—rather than prompting—language models.
(译文) DSPy是通过「编程」的方式——而不是写提示词的方式——来使用语言模型的框架。
所谓programming的方式,我们在上篇文章分析代码的时候已经发现这个现象了:
cot = dspy.ChainOfThought('context, question -> response')
这行代码创建了一个Module实例cot,但没有明确指明任何提示词或提示词模板。'context, question -> response'的形式类似于一个函数签名,它的意思就表示,这个Module接收两个输入context和question,调用LLM后则输出一个response。
这种编程风格是DSPy的一种设计选择,故意把真正的prompt「隐藏」在了后面。这种方式可能有利有弊,我们眼下先不讨论。在这里,我们看一下背后真正的prompt是什么,有助于更好地理解后面的优化过程。
我们运行一下前面的cot Module,如下图:
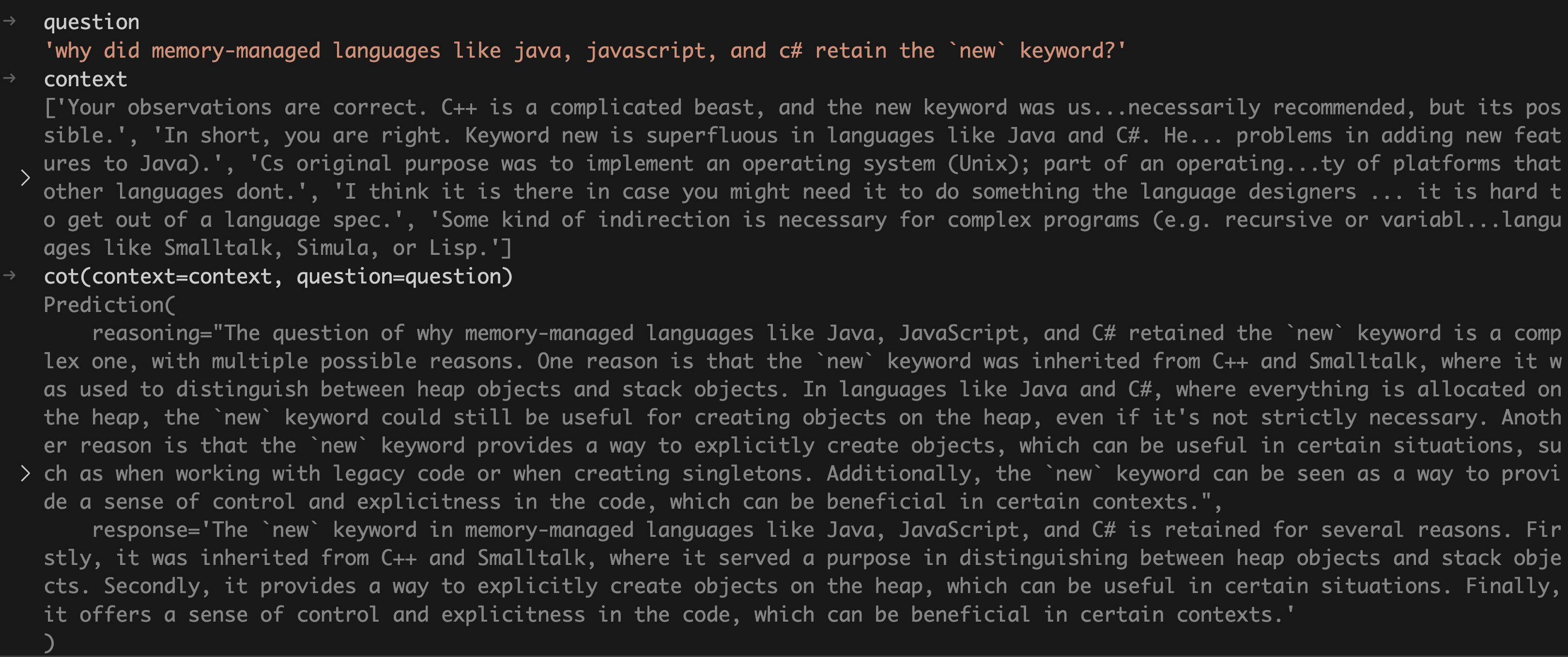
注意上图中这一行代码:
cot(context=context, question=question)
我们看到调用cot这个Module的时候传入了两个参数:context和question,这与前面指定的Signature的形式是相符的,即'context, question -> response'。
这行代码背后做了很多事情:它根据输入的参数组装成了一个prompt,然后调用了LLM,并返回了响应response。而且,对于dspy.ChainOfThought来说,它还多返回了一个输出字段reasoning,这是LLM输出的推理过程。
cot Module与LLM的交互过程,可以调用dspy.inspect_history方法来查看。这个交互过程包含了输入给LLM的prompt和LLM输出的completion。如下图(点击看大图):

好了,现在我们看到了真正的prompt了。上图中「Response:」那行之前是prompt,「Response:」那行之后则是LLM的输出。
在DSPy框架中,凡是调用LLM地方,prompt基本上都是遵循类似的这样一个模板格式。这也包括使用LLM计算Metric的时候,以及DSPy优化器在工作时调用LLM生成新的prompt的时候。正是因为DSPy使用了这样一种相对「固定」的内部prompt模板格式,才使得它能够让开发者在写程序时不需要指定具体的prompt,实现了框架所宣称的「programming—rather than prompting—language models」。
上图还有一个值得注意的地方,在System message最后一行:
Given the fields `context`, `question`, produce the fields `response`.
这一行的内容,就是prompt中的instruction (指令)。当DSPy的优化器工作的时候,其中的一个步骤就是会重写这个instruction。
MIPROv2的优化过程详解
在看到了DSPy中真正的prompt之后,我们来仔细审视一下DSPy优化器的工作过程。
回忆一下上篇文章中调用优化器的代码:
...
rag = RAG()
# Part 5: 初始化Teleprompter并完成编译/优化
# dspy.MIPROv2是Teleprompter的子集
tp = dspy.MIPROv2(
metric=metric,
auto="light",
num_threads=8
)
optimized_rag = tp.compile(rag, trainset=trainset, valset=valset,
max_bootstrapped_demos=2, max_labeled_demos=2,
requires_permission_to_run=False)
MIPROv2是DSPy中一类比较重要的优化器。它的具体算法实现出自论文“Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs”[3]。MIPROv2同时优化prompt中的两个部分:一个是在上一节我们看到的instruction,另一个是few-shot部分。在Heiko Hotz发表的一篇博客文章中[4],优化few-shot的做法在APE工程中被称为exemplar selection。
概括来看,MIPROv2的执行过程可以分为三个大的步骤:
- Step 1: 通过Bootstrap的方式,生成few-shot候选集。
- Step 2: 生成prompt中的instruction候选集。
- Step 3: 从候选集中选出最佳的few-shot和instruction组合。
下面我们通过实际运行的例子来介绍这三个步骤的详细情况。
Step 1: 生成few-shot候选集。
这一步的目的是,基于trainset的数据,为DSPy程序的每一个子Module生成few-shot例子。用于生成的策略主要有两种。
第一种策略,是从trainset中直接采样,采样得到的example直接作为每个子Module的few-shot候选。采样的数目,就是由前面代码中的max_labeled_demos来指定的。
第二种策略,真正地被称为Bootstrap。它的做法是这样:从trainset中随机选择一些example,放到DSPy程序(rag Module)中去执行,并在执行过程中记录程序的各个子Module的输入和输出。如果DSPy程序执行完端到端的输出能够通过由Metric所定义的评测标准,那么各个子Module就将它们各自的输入、输出作为few-shot候选。
之所以需要执行这种Bootstrap策略,是因为在DSPy中,优化过程是针对整个DSPy程序的,而不是仅针对单个LLM Module的。DSPy把一个程序看成是由多个Module组成的,而且整个程序的执行是一个多阶段 (Multi-Stage) 的pipeline。trainset是针对整个程序的端到端的标注,里面通常没有针对中间结果的标注信息。因此,Bootstrap策略相当于是利用端到端的trainset标注数据,通过程序自动化地对中间结果产生了部分标注数据,从而省去了对中间结果进行人工标注的大量工作。
由Bootstrap策略为每个Module生成的few-shot例子的数目,是由前面代码中的max_bootstrapped_demos来指定的。
这样说来,前面第一种策略,从trainset中直接采样作为few-shot候选,当DSPy程序包含多个子Module时,这种策略很可能发挥不了真正的效力。因为,中间Module预期的输出标注信息,在trainset中很可能没有。
Bootstrap策略可以执行多次。只要trainset足够大,MIPROv2算法会每次把trainset进行一次shuffle,然后重复执行Bootstrap策略就得到一个新的few-shot候选集。
回到前面代码的执行,经过Step 1之后,生成的few-shot候选集如下所示:
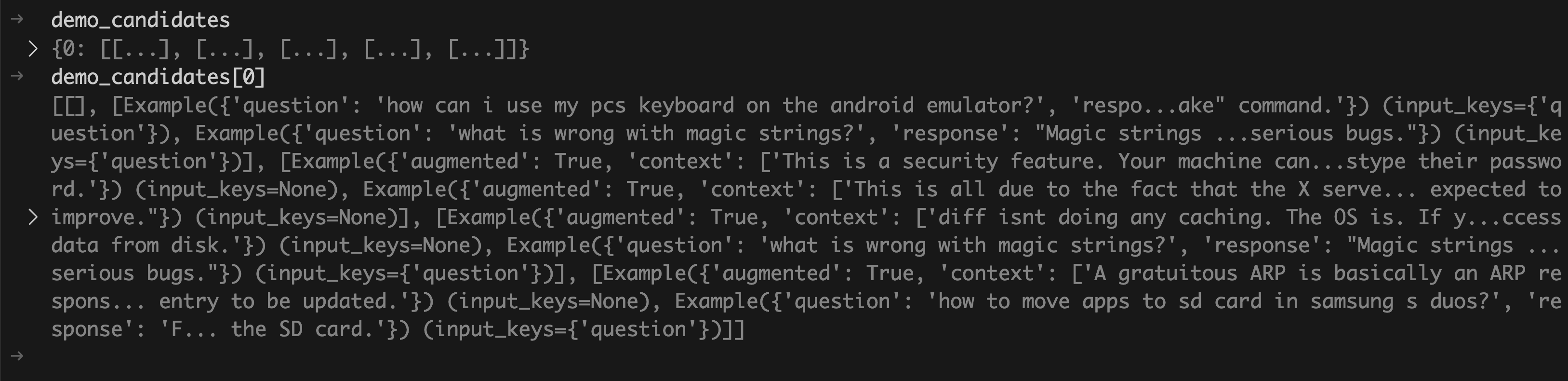
简单解释一下上图的结果:
demo_candidates的结果显示了rag程序中只有一个Module(实际是个dspy.ChainOfThought实例),其编号为0,且Step 1为这个Module生成了5个few-shot候选集。
demo_candidates[0]的结果显示了这个唯一的Module的5个few-shot候选集,其中每个候选集包含2个example(由参数max_bootstrapped_demos和max_labeled_demos指定的)。如果大家仔细观察的话,会发现example有两种形式:
- 一种是带
augmented字段的。表示这个example是由Bootstrap策略生成的。 - 另一种是不带
augmented字段的。表示这个example是直接从trainset中采样得到的。
这5个few-shot候选集,并非都会用在最后的prompt中。最后还会进行一次筛选。
Step 2: 生成instruction候选集。
这一步针对程序的每个Module的每个few-shot候选集,都生成一个全新的instruction候选。
新的instruction具体是如何生成?我们来查看其中的一个实际例子。下图展示了其中一次生成instruction时与LLM的交互过程(包含meta-prompt和LLM输出):

上图显示meta-prompt中包含了非常多的信息,这非常有启发性。现在我们来理解一下上图中的很多信息。
首先,上图中「Response:」那行之前就是我们在上篇文章中提到的meta-prompt,而「Response:」之后则是LLM的输出。
在这个meta-prompt中,我们可以看到,为了生成新的instruction,DSPy喂给了LLM很多参考信息,包括:
- 对数据集的描述,即
[[ ## dataset_description ## ]]字段。这里实际上是对trainset的一个自然语言描述,这个描述也是由LLM来总结生成的。 - 程序的代码和描述,即
[[ ## program_code ## ]]和[[ ## program_description ## ]]字段。 - 作为参考起点的基础instruction,即
[[ ## basic_instruction ## ]]字段。 - 指导生成的tip,它用于引导生成instruction的方向以及风格,即
[[ ## tip ## ]]字段。
生成instruction的tip,DSPy框架提供了一些预置的配置,如下:
TIPS = {
"none": "",
"creative": "Don't be afraid to be creative when creating the new instruction!",
"simple": "Keep the instruction clear and concise.",
"description": "Make sure your instruction is very informative and descriptive.",
"high_stakes": "The instruction should include a high stakes scenario in which the LM must solve the task!",
"persona": 'Include a persona that is relevant to the task in the instruction (ie. "You are a ...")',
}
在上图中,生成instruction时使用了“creative”的tip,它鼓励LLM生成更有创造性的instruction。[[ ## proposed_instruction ## ]]字段的值就是在引导下最终生成的instruction。
经过完整的Step 2执行之后,生成的instruction候选集如下所示:

同样地,简单解释一下上图的结果:
instruction_candidates的结果显示了rag程序中只有一个Module(实际是dspy.ChainOfThought实例),编号为0,且Step 2为这个Module生成了5个候选的instruction。
图中后面几行分别显示了生成的这5个instruction的具体内容。可以看到它们在内容表述上还是有很大差异的。
Step 3: 筛选最佳的few-shot和instruction组合。
经过前两步,优化器已经生成了5个候选的instruction和5个few-shot候选集(各包含2个example)。最后这一步,优化器会从中随机组合instruction和few-shot,并选出使得Evaluate分数最高的一个组合,得到最优的程序。
这个过程有点类似于传统机器学习中的超参优化 (hyperparameter optimization) ,在DSPy中,这一步是借助一个叫做Optuna的开源框架[5]来实现的。
下面就是这个过程的执行日志:
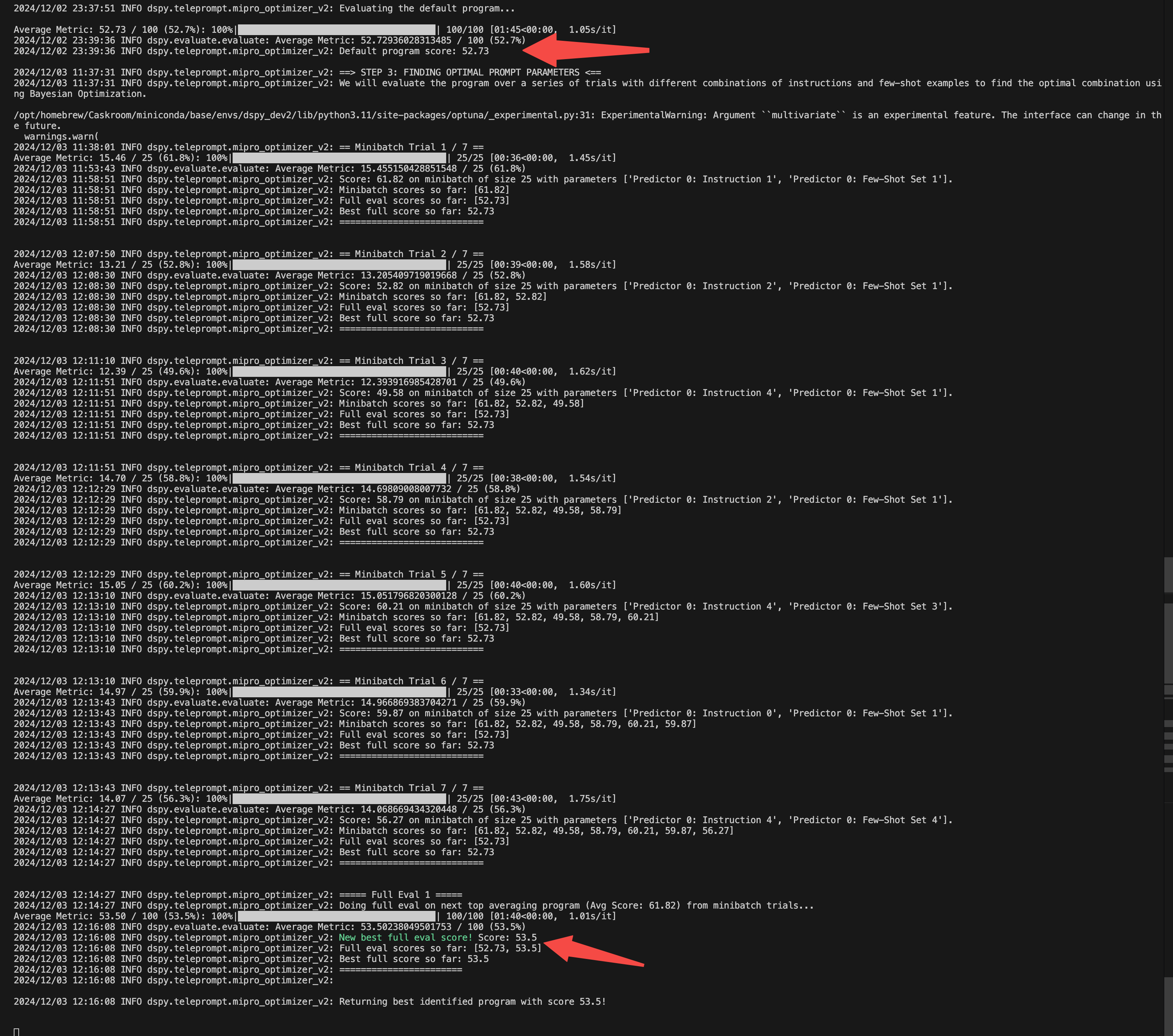
从上图看出,程序总共运行了7次优化 (Trial) ,评测分数从最初的52.73提升到了53.5。限于算力、具体配置及各种因素,总体提升不明显(不过本文主要是为了展示DSPy的整体运行过程,所以先不去做更多优化)。
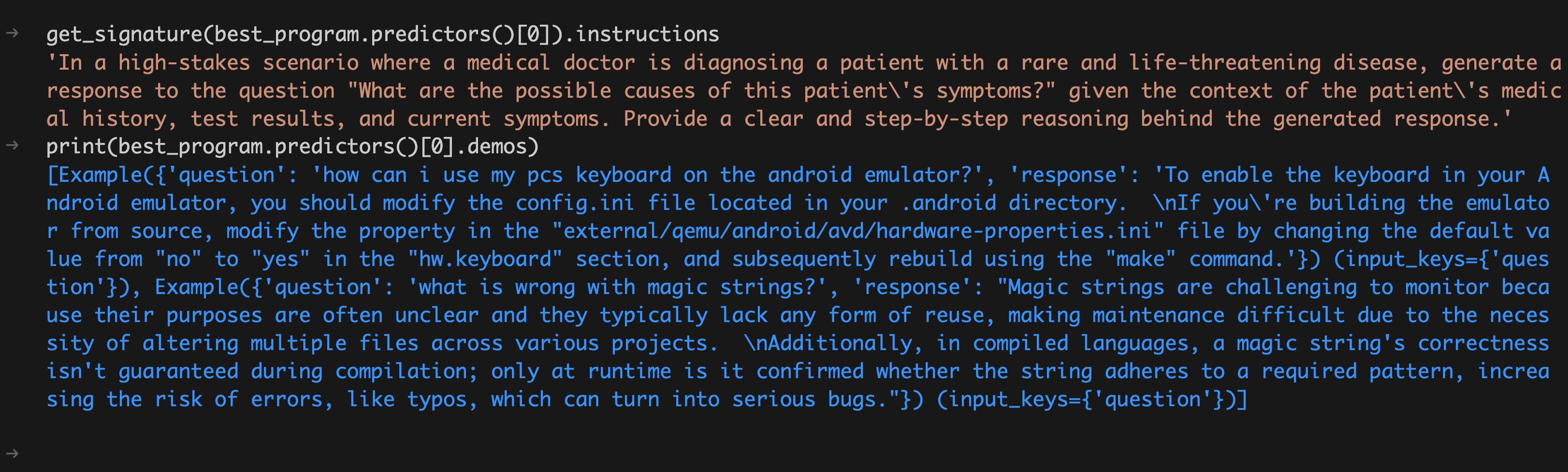
最后,我们打印出最后得到的「最优程序」它所采用的instruction和few-shot集合,如下:
下一步
至此,我们基本上把DSPy程序的基础概念,以及一个典型的DSPy程序的运行过程都讨论清楚了。在下一篇文章中,我们将更深入地做一些分析,包括DSPy和APE的区别、类似的工程思路给我们带来的启示,以及可能存在的一些问题。
(正文完,下篇见)
参考文献:
- [1] DSPy官网.
- [2] DSPy Github主页.
- [3] Krista Opsahl-Ong, Michael J Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, Omar Khattab. 2024. Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs.
- [4] Heiko Hotz. 2024. Automated Prompt Engineering: The Definitive Hands-On Guide.
- [5] Optuna: A hyperparameter optimization framework.
其它精选文章:
- 浅谈DSPy和自动化提示词工程(上)
- 技术变迁中的变与不变:如何更快地生成token?
- 用统计学的观点看世界:从找不到东西说起
- 从GraphRAG看信息的重新组织
- 企业AI智能体、数字化与行业分工
- 三个字节的历险
- 分布式领域最重要的一篇论文,到底讲了什么?
- 漫谈分布式系统、拜占庭将军问题与区块链
- 深度学习、信息论与统计学
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-dspy-internals-2.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。

最新文章
- 为什么agent和workflow可以融合在同一个架构里?
- 万字长文!两栖模式构建Agent,与OpenClaw/Hermes不一样的解法——开源AmphiLoop
- Claude Managed Agents意味着什么?
- 【开源】专为「探路+编码」范式设计的全新浏览器工具集+Skills
- 不用手写一行代码,10分钟立等可取,爬取twitter和github动态
- 使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
- 过年了,聊聊AI和人文
- 使用Bridgic长程自主模块+MCP,控制你的浏览器
- AI智能体纪元或将从2026开始归零
- 从Python异步编程的剖析中体会智能体并发编程模式