Redis内部数据结构详解(5)——quicklist
2016-07-22
本文是《Redis内部数据结构详解》系列的第五篇。在本文中,我们介绍一个Redis内部数据结构——quicklist。Redis对外暴露的list数据类型,它底层实现所依赖的内部数据结构就是quicklist。
我们在讨论中还会涉及到两个Redis配置(在redis.conf中的ADVANCED CONFIG部分):
list-max-ziplist-size -2
list-compress-depth 0
我们在讨论中会详细解释这两个配置的含义。
注:本文讨论的quicklist实现基于Redis源码的3.2分支。
quicklist概述
Redis对外暴露的上层list数据类型,经常被用作队列使用。比如它支持的如下一些操作:
lpush: 在左侧(即列表头部)插入数据。rpop: 在右侧(即列表尾部)删除数据。rpush: 在右侧(即列表尾部)插入数据。lpop: 在左侧(即列表头部)删除数据。
这些操作都是O(1)时间复杂度的。
当然,list也支持在任意中间位置的存取操作,比如lindex和linsert,但它们都需要对list进行遍历,所以时间复杂度较高,为O(N)。
概况起来,list具有这样的一些特点:它是一个能维持数据项先后顺序的列表(各个数据项的先后顺序由插入位置决定),便于在表的两端追加和删除数据,而对于中间位置的存取具有O(N)的时间复杂度。这不正是一个双向链表所具有的特点吗?
list的内部实现quicklist正是一个双向链表。在quicklist.c的文件头部注释中,是这样描述quicklist的:
A doubly linked list of ziplists
它确实是一个双向链表,而且是一个ziplist的双向链表。
这是什么意思呢?
我们知道,双向链表是由多个节点(Node)组成的。这个描述的意思是:quicklist的每个节点都是一个ziplist。ziplist我们已经在上一篇介绍过。
ziplist本身也是一个能维持数据项先后顺序的列表(按插入位置),而且是一个内存紧缩的列表(各个数据项在内存上前后相邻)。比如,一个包含3个节点的quicklist,如果每个节点的ziplist又包含4个数据项,那么对外表现上,这个list就总共包含12个数据项。
quicklist的结构为什么这样设计呢?总结起来,大概又是一个空间和时间的折中:
- 双向链表便于在表的两端进行push和pop操作,但是它的内存开销比较大。首先,它在每个节点上除了要保存数据之外,还要额外保存两个指针;其次,双向链表的各个节点是单独的内存块,地址不连续,节点多了容易产生内存碎片。
- ziplist由于是一整块连续内存,所以存储效率很高。但是,它不利于修改操作,每次数据变动都会引发一次内存的realloc。特别是当ziplist长度很长的时候,一次realloc可能会导致大批量的数据拷贝,进一步降低性能。
于是,结合了双向链表和ziplist的优点,quicklist就应运而生了。
不过,这也带来了一个新问题:到底一个quicklist节点包含多长的ziplist合适呢?比如,同样是存储12个数据项,既可以是一个quicklist包含3个节点,而每个节点的ziplist又包含4个数据项,也可以是一个quicklist包含6个节点,而每个节点的ziplist又包含2个数据项。
这又是一个需要找平衡点的难题。我们只从存储效率上分析一下:
- 每个quicklist节点上的ziplist越短,则内存碎片越多。内存碎片多了,有可能在内存中产生很多无法被利用的小碎片,从而降低存储效率。这种情况的极端是每个quicklist节点上的ziplist只包含一个数据项,这就蜕化成一个普通的双向链表了。
- 每个quicklist节点上的ziplist越长,则为ziplist分配大块连续内存空间的难度就越大。有可能出现内存里有很多小块的空闲空间(它们加起来很多),但却找不到一块足够大的空闲空间分配给ziplist的情况。这同样会降低存储效率。这种情况的极端是整个quicklist只有一个节点,所有的数据项都分配在这仅有的一个节点的ziplist里面。这其实蜕化成一个ziplist了。
可见,一个quicklist节点上的ziplist要保持一个合理的长度。那到底多长合理呢?这可能取决于具体应用场景。实际上,Redis提供了一个配置参数list-max-ziplist-size,就是为了让使用者可以来根据自己的情况进行调整。
list-max-ziplist-size -2
我们来详细解释一下这个参数的含义。它可以取正值,也可以取负值。
当取正值的时候,表示按照数据项个数来限定每个quicklist节点上的ziplist长度。比如,当这个参数配置成5的时候,表示每个quicklist节点的ziplist最多包含5个数据项。
当取负值的时候,表示按照占用字节数来限定每个quicklist节点上的ziplist长度。这时,它只能取-1到-5这五个值,每个值含义如下:
- -5: 每个quicklist节点上的ziplist大小不能超过64 Kb。(注:1kb => 1024 bytes)
- -4: 每个quicklist节点上的ziplist大小不能超过32 Kb。
- -3: 每个quicklist节点上的ziplist大小不能超过16 Kb。
- -2: 每个quicklist节点上的ziplist大小不能超过8 Kb。(-2是Redis给出的默认值)
- -1: 每个quicklist节点上的ziplist大小不能超过4 Kb。
另外,list的设计目标是能够用来存储很长的数据列表的。比如,Redis官网给出的这个教程:Writing a simple Twitter clone with PHP and Redis,就是使用list来存储类似Twitter的timeline数据。
当列表很长的时候,最容易被访问的很可能是两端的数据,中间的数据被访问的频率比较低(访问起来性能也很低)。如果应用场景符合这个特点,那么list还提供了一个选项,能够把中间的数据节点进行压缩,从而进一步节省内存空间。Redis的配置参数list-compress-depth就是用来完成这个设置的。
list-compress-depth 0
这个参数表示一个quicklist两端不被压缩的节点个数。注:这里的节点个数是指quicklist双向链表的节点个数,而不是指ziplist里面的数据项个数。实际上,一个quicklist节点上的ziplist,如果被压缩,就是整体被压缩的。
参数list-compress-depth的取值含义如下:
- 0: 是个特殊值,表示都不压缩。这是Redis的默认值。
- 1: 表示quicklist两端各有1个节点不压缩,中间的节点压缩。
- 2: 表示quicklist两端各有2个节点不压缩,中间的节点压缩。
- 3: 表示quicklist两端各有3个节点不压缩,中间的节点压缩。
- 依此类推…
由于0是个特殊值,很容易看出quicklist的头节点和尾节点总是不被压缩的,以便于在表的两端进行快速存取。
Redis对于quicklist内部节点的压缩算法,采用的LZF——一种无损压缩算法。
quicklist的数据结构定义
quicklist相关的数据结构定义可以在quicklist.h中找到:
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
typedef struct quicklistLZF {
unsigned int sz; /* LZF size in bytes*/
char compressed[];
} quicklistLZF;
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned int len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
quicklistNode结构代表quicklist的一个节点,其中各个字段的含义如下:
- prev: 指向链表前一个节点的指针。
- next: 指向链表后一个节点的指针。
- zl: 数据指针。如果当前节点的数据没有压缩,那么它指向一个ziplist结构;否则,它指向一个quicklistLZF结构。
- sz: 表示zl指向的ziplist的总大小(包括
zlbytes,zltail,zllen,zlend和各个数据项)。需要注意的是:如果ziplist被压缩了,那么这个sz的值仍然是压缩前的ziplist大小。 - count: 表示ziplist里面包含的数据项个数。这个字段只有16bit。稍后我们会一起计算一下这16bit是否够用。
- encoding: 表示ziplist是否压缩了(以及用了哪个压缩算法)。目前只有两种取值:2表示被压缩了(而且用的是LZF压缩算法),1表示没有压缩。
- container: 是一个预留字段。本来设计是用来表明一个quicklist节点下面是直接存数据,还是使用ziplist存数据,或者用其它的结构来存数据(用作一个数据容器,所以叫container)。但是,在目前的实现中,这个值是一个固定的值2,表示使用ziplist作为数据容器。
- recompress: 当我们使用类似lindex这样的命令查看了某一项本来压缩的数据时,需要把数据暂时解压,这时就设置recompress=1做一个标记,等有机会再把数据重新压缩。
- attempted_compress: 这个值只对Redis的自动化测试程序有用。我们不用管它。
- extra: 其它扩展字段。目前Redis的实现里也没用上。
quicklistLZF结构表示一个被压缩过的ziplist。其中:
- sz: 表示压缩后的ziplist大小。
- compressed: 是个柔性数组(flexible array member),存放压缩后的ziplist字节数组。
真正表示quicklist的数据结构是同名的quicklist这个struct:
- head: 指向头节点(左侧第一个节点)的指针。
- tail: 指向尾节点(右侧第一个节点)的指针。
- count: 所有ziplist数据项的个数总和。
- len: quicklist节点的个数。
- fill: 16bit,ziplist大小设置,存放
list-max-ziplist-size参数的值。 - compress: 16bit,节点压缩深度设置,存放
list-compress-depth参数的值。
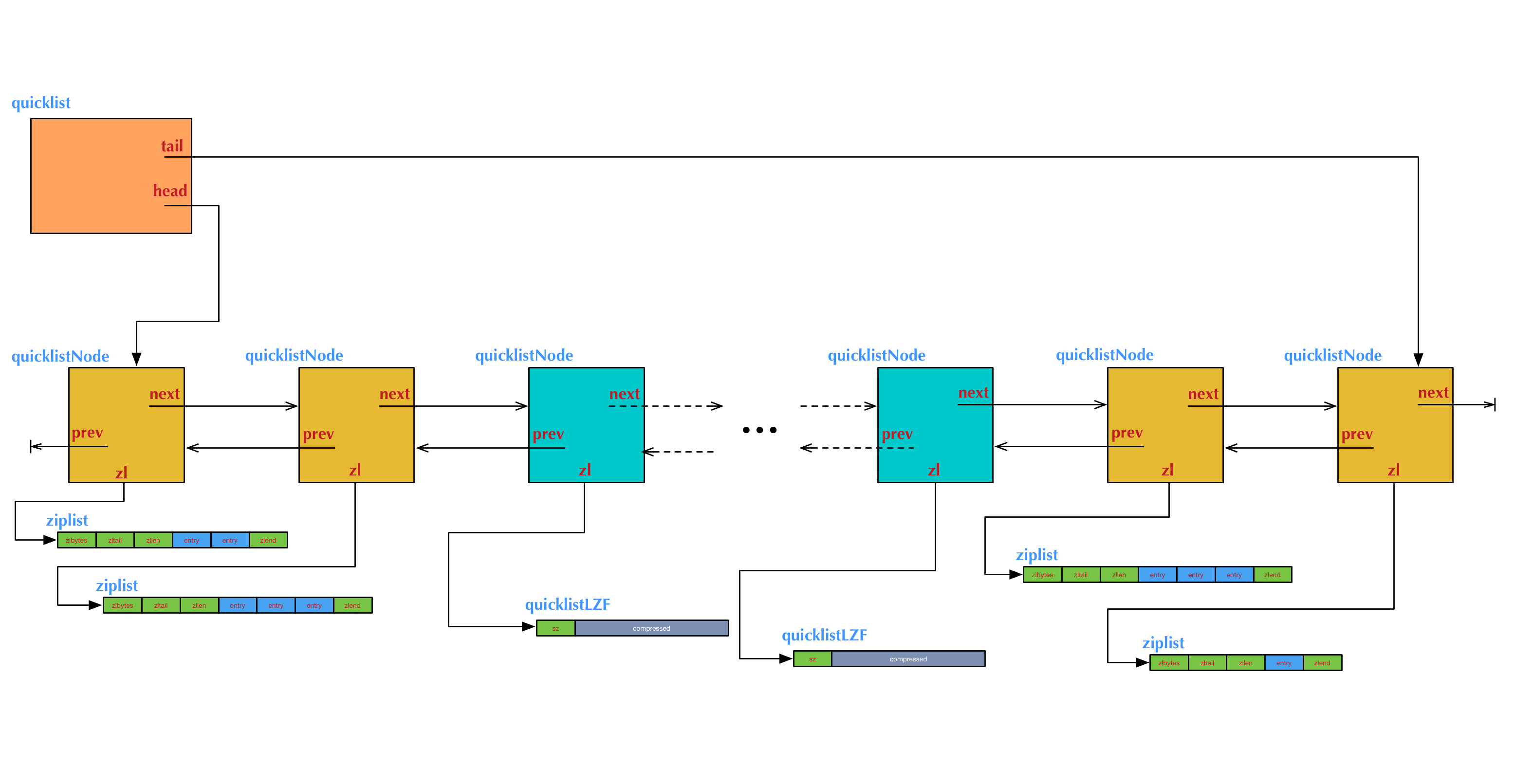
上图是一个quicklist的结构图举例。图中例子对应的ziplist大小配置和节点压缩深度配置,如下:
list-max-ziplist-size 3
list-compress-depth 2
这个例子中我们需要注意的几点是:
- 两端各有2个橙黄色的节点,是没有被压缩的。它们的数据指针zl指向真正的ziplist。中间的其它节点是被压缩过的,它们的数据指针zl指向被压缩后的ziplist结构,即一个quicklistLZF结构。
- 左侧头节点上的ziplist里有2项数据,右侧尾节点上的ziplist里有1项数据,中间其它节点上的ziplist里都有3项数据(包括压缩的节点内部)。这表示在表的两端执行过多次
push和pop操作后的一个状态。
现在我们来大概计算一下quicklistNode结构中的count字段这16bit是否够用。
我们已经知道,ziplist大小受到list-max-ziplist-size参数的限制。按照正值和负值有两种情况:
- 当这个参数取正值的时候,就是恰好表示一个quicklistNode结构中zl所指向的ziplist所包含的数据项的最大值。
list-max-ziplist-size参数是由quicklist结构的fill字段来存储的,而fill字段是16bit,所以它所能表达的值能够用16bit来表示。 - 当这个参数取负值的时候,能够表示的ziplist最大长度是64 Kb。而ziplist中每一个数据项,最少需要2个字节来表示:1个字节的
prevrawlen,1个字节的data(len字段和data合二为一;详见上一篇)。所以,ziplist中数据项的个数不会超过32 K,用16bit来表达足够了。
实际上,在目前的quicklist的实现中,ziplist的大小还会受到另外的限制,根本不会达到这里所分析的最大值。
下面进入代码分析阶段。
quicklist的创建
当我们使用lpush或rpush命令第一次向一个不存在的list里面插入数据的时候,Redis会首先调用quicklistCreate接口创建一个空的quicklist。
quicklist *quicklistCreate(void) {
struct quicklist *quicklist;
quicklist = zmalloc(sizeof(*quicklist));
quicklist->head = quicklist->tail = NULL;
quicklist->len = 0;
quicklist->count = 0;
quicklist->compress = 0;
quicklist->fill = -2;
return quicklist;
}
在很多介绍数据结构的书上,实现双向链表的时候经常会多增加一个空余的头节点,主要是为了插入和删除操作的方便。从上面quicklistCreate的代码可以看出,quicklist是一个不包含空余头节点的双向链表(head和tail都初始化为NULL)。
quicklist的push操作
quicklist的push操作是调用quicklistPush来实现的。
void quicklistPush(quicklist *quicklist, void *value, const size_t sz,
int where) {
if (where == QUICKLIST_HEAD) {
quicklistPushHead(quicklist, value, sz);
} else if (where == QUICKLIST_TAIL) {
quicklistPushTail(quicklist, value, sz);
}
}
/* Add new entry to head node of quicklist.
*
* Returns 0 if used existing head.
* Returns 1 if new head created. */
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head;
if (likely(
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
quicklist->head->zl =
ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(quicklist->head);
} else {
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(node);
_quicklistInsertNodeBefore(quicklist, quicklist->head, node);
}
quicklist->count++;
quicklist->head->count++;
return (orig_head != quicklist->head);
}
/* Add new entry to tail node of quicklist.
*
* Returns 0 if used existing tail.
* Returns 1 if new tail created. */
int quicklistPushTail(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_tail = quicklist->tail;
if (likely(
_quicklistNodeAllowInsert(quicklist->tail, quicklist->fill, sz))) {
quicklist->tail->zl =
ziplistPush(quicklist->tail->zl, value, sz, ZIPLIST_TAIL);
quicklistNodeUpdateSz(quicklist->tail);
} else {
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_TAIL);
quicklistNodeUpdateSz(node);
_quicklistInsertNodeAfter(quicklist, quicklist->tail, node);
}
quicklist->count++;
quicklist->tail->count++;
return (orig_tail != quicklist->tail);
}
不管是在头部还是尾部插入数据,都包含两种情况:
- 如果头节点(或尾节点)上ziplist大小没有超过限制(即
_quicklistNodeAllowInsert返回1),那么新数据被直接插入到ziplist中(调用ziplistPush)。 - 如果头节点(或尾节点)上ziplist太大了,那么新创建一个quicklistNode节点(对应地也会新创建一个ziplist),然后把这个新创建的节点插入到quicklist双向链表中(调用
_quicklistInsertNodeAfter)。
在_quicklistInsertNodeAfter的实现中,还会根据list-compress-depth的配置将里面的节点进行压缩。它的实现比较繁琐,我们这里就不展开讨论了。
quicklist的其它操作
quicklist的操作较多,且实现细节都比较繁杂,这里就不一一分析源码了,我们简单介绍一些比较重要的操作。
quicklist的pop操作是调用quicklistPopCustom来实现的。quicklistPopCustom的实现过程基本上跟quicklistPush相反,先从头部或尾部节点的ziplist中把对应的数据项删除,如果在删除后ziplist为空了,那么对应的头部或尾部节点也要删除。删除后还可能涉及到里面节点的解压缩问题。
quicklist不仅实现了从头部或尾部插入,也实现了从任意指定的位置插入。quicklistInsertAfter和quicklistInsertBefore就是分别在指定位置后面和前面插入数据项。这种在任意指定位置插入数据的操作,情况比较复杂,有众多的逻辑分支。
- 当插入位置所在的ziplist大小没有超过限制时,直接插入到ziplist中就好了;
- 当插入位置所在的ziplist大小超过了限制,但插入的位置位于ziplist两端,并且相邻的quicklist链表节点的ziplist大小没有超过限制,那么就转而插入到相邻的那个quicklist链表节点的ziplist中;
- 当插入位置所在的ziplist大小超过了限制,但插入的位置位于ziplist两端,并且相邻的quicklist链表节点的ziplist大小也超过限制,这时需要新创建一个quicklist链表节点插入。
- 对于插入位置所在的ziplist大小超过了限制的其它情况(主要对应于在ziplist中间插入数据的情况),则需要把当前ziplist分裂为两个节点,然后再其中一个节点上插入数据。
quicklistSetOptions用于设置ziplist大小配置参数(list-max-ziplist-size)和节点压缩深度配置参数(list-compress-depth)。代码比较简单,就是将相应的值分别设置给quicklist结构的fill字段和compress字段。
下一篇我们将介绍skiplist和它所支撑的Redis数据类型sorted set,敬请期待。
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-redis-quicklist.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。

最新文章
- 为什么agent和workflow可以融合在同一个架构里?
- 万字长文!两栖模式构建Agent,与OpenClaw/Hermes不一样的解法——开源AmphiLoop
- Claude Managed Agents意味着什么?
- 【开源】专为「探路+编码」范式设计的全新浏览器工具集+Skills
- 不用手写一行代码,10分钟立等可取,爬取twitter和github动态
- 使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
- 过年了,聊聊AI和人文
- 使用Bridgic长程自主模块+MCP,控制你的浏览器
- AI智能体纪元或将从2026开始归零
- 从Python异步编程的剖析中体会智能体并发编程模式