小白的数据进阶之路(上)——从Shell脚本到MapReduce
2016-10-30
那一年,小白刚从学校毕业,学的是计算机专业。最开始他也不清楚自己想要一份怎样的工作,只知道自己先找个互联网公司干干技术再说。
有一天,小白来到一家刚成立不久的小创业公司参见面试。公司虽小,但团队却是华丽丽的。两位创始人都是MIT的MBA,Co-CEO。他们号称,公司的运营、财务、市场以及销售人员,都是从大公司高薪挖过来的。此外,他们还告诉小白,公司另有一位政府背景深厚但不愿透露姓名的神秘股东加盟。
我们手头有百万美金的风险投资,团队也基本到位。现在万事俱备,就差一位程序员了。
小白平常在学校里就很喜欢阅读那些创业成功的励志故事,对于能拿到风险投资的人特别崇拜。
你们要做的是什么产品?小白问道。
这个涉及到我们的创意,暂时保密。但可以告诉你的是,我们要做一款伟大的产品,它将颠覆整个互联网行业。两位CEO神秘地回答。
随后,他们又补充道,
我们计划在两年内上市。
小白听完不禁心潮澎湃,随后就入职了这家公司。
公司已经有了一个能运行的网站系统,小白每天的工作就是维护这个网站。工作并不忙,平常只是读读代码,改改bug。
突然有一天,其中一位CEO让小白统计一下网站的数据,比如日活跃(Dayliy Active Users)、周活跃(Weekly Active Users)、月活跃(Monthly Active Users),说是要给投资人看。
小白想了想,他手头现有的一份基础数据,就是访问日志(Access Log)。访问日志是每天一个文件,每个文件里面每一行的数据格式如下:
[时间] [用户ID] [操作名称] [其它参数...]
比方说要统计日活跃,就要把一个文件(对应一天)里出现同样用户ID的行进行去重,去重后的文件行数就是日活跃数据了。周活跃和月活跃与此类似,只是要分别在一周和一个月内进行去重。
小白那时只会写Java程序,所以他写了个Java程序来进行统计:
逐行读取一个文件的内容,同时内存里维护一个HashSet用于做去重判断。每读一行,解析出用户ID,判断它在HashSet里是否存在。如果不存在,就把这个用户ID插入HashSet;如果存在,则忽略这一行,继续读下一行。一个文件处理完之后,HashSet里面存放的数据个数就是那一天对应的日活跃数据。
同样,统计周活跃和月活跃只需要让这个程序分别读取7天和30天的文件进行处理。
从此以后,两位CEO时不时地来找小白统计各种数据。小白知道,他们最近频繁地出入于投资圈的各种会议和聚会,大概是想给公司进行第二轮融资。
每次看到数据之后,他们都一脸难以置信的表情。没有统计错误吧?我们就这么点儿用户吗?
小白竟无言以对。
转眼间一年时间过去了。小白发现,他们与上市目标的距离跟一年前同样遥远。更糟糕的是,公司之前融到的钱已经花得差不多了,而第二轮融资又迟迟没有结果,小白上个月的工资也被拖欠着没发。于是,他果断辞职。
截止到小白辞职的那一天,公司的日活跃数据也没有超过四位数。
小白的第二份工作,是一家做手机App的公司。
这家公司的技术总监,自称老王。在面试的时候,老王听说小白做过数据统计,二话没说把他招了进来。
小白进了公司才知道,CEO以前是做财务出身,非常重视数据,每天他自己提出的各种大大小小的数据统计需求就不下十几项。
小白每天忙着写各种统计程序,处理各种数据格式,经常加班到晚上十一二点。而且,更令他沮丧的是,很多统计需求都是一次性的,他写的统计程序大部分也是只运行过一次,以后就扔到一边再也用不到了。
有一天,他正在加班统计数据。老王走过来,发现他用的是Java语言,感到很惊讶。老王跟小白一起分析后指出,大部分数据需求呢,其实都可以从访问日志统计出来。而处理文本文件的日志数据,用Shell脚本会比较方便。
于是,小白猛学了一阵Shell编程。他发现,用一些Shell命令来统计一些数据,比如日活跃,变得非常简单。以某一天的访问日志文件”access.log”为例,它每行的格式如下:
[时间] [用户ID] [操作名称] [其它参数...]
只用一行命令就统计出了日活跃:
cat access.log | awk '{print $2}' | sort | uniq | wc -l
这行命令,使用awk把access.log中的第二列(也就是用户ID)过滤出来,然后进行排序,这样就使得相同的用户ID挨在了一起。再经过uniq命令处理,对相邻行进行去重,就得到了独立用户ID。最后用wc命令算出一共有多少行,就是日活跃。
写了一些Shell脚本之后,小白慢慢发现,使用一些简单的命令就可以很快速地对文件数据集合进行并、交、差运算。
假设a和b是两个文件,里面每一行看作一个数据元素,且每一行都各不相同。
那么,计算a和b的数据并集,使用下面的命令:
cat a b | sort | uniq > a_b.union
交集:
cat a b | sort | uniq -d > a_b.intersect
这里uniq命令的-d参数表示:只打印相邻重复的行。
计算a和b的差集稍微复杂一点:
cat a_b.union b | sort | uniq -u > a_b.diff
这里利用了a和b的并集结果a_b.union,将它与b一起进行排序之后,利用uniq的-u参数把相邻没有重复的行打印出来,就得到了a和b的差集。
小白发现,很多数据统计都可以用集合的并、交、差运算来完成。
首先,把每天的访问日志加工一下,就得到了一个由独立用户ID组成的集合文件(每行一个用户ID,不重复):
cat access.log | awk '{print $2}' | sort | uniq > access.log.uniq
比如,要计算周活跃,就先收集7天的独立用户集合:
- access.log.uniq.1
- access.log.uniq.2
- ……
- access.log.uniq.7
把7个集合求并集就得到周活跃:
cat access.log.uniq.[1-7] | sort | uniq | wc -l
同样,要计算月活跃就对30天的独立用户集合求并集。
再比如,计算用户留存率(Retention),则需要用到交集。先从某一天的日志文件中把新注册的用户集合分离出来,以它为基础:
- 计算这个新用户集合和1天之后的独立活跃用户集合的交集,这个交集与原来新用户集合的大小的比值,就是该天的1日留存率。
- 计算这个新用户集合和2天之后的独立活跃用户集合的交集,这个交集与原来新用户集合的大小的比值,就是该天的2日留存率。
- ……
- 以此类推,可以计算出N日留存率。
再比如,类似这样的统计需求:“在过去某段时间内执行过某个操作的用户,他们N天之后又执行了另外某个操作的比率”,或者计算用户深入到某个层级的页面留存率,基本都可以通过并集和交集来计算。而类似“使用了某个业务但没有使用另外某个业务的用户”的统计,则涉及到差集的计算。
在掌握了Shell脚本处理数据的一些技巧之后,小白又深入学习了awk编程,从此他做起数据统计的任务来,越发地轻松自如。而公司的CEO和产品团队,每天仔细分析这些数据之后,有针对性地对产品进行调整,也取得了不错的成绩。
随着用户的增多和业务的发展,访问日志越来越大,从几百MB到1个GB,再到几十个GB,上百GB。统计脚本执行的时间也越来越长,很多统计要跑几个小时,甚至以天来计。以前那种灵活的数据统计需求,再也做不到“立等可取”了。而且,更糟糕的是,单台机器的内存已经捉襟见肘。机器虽然内存已经配置到了很大,但还是经常出现严重的swap,以前的脚本眼看就要“跑不动”了。
为了加快统计脚本执行速度,小白打算找到一个办法能够让数据统计脚本在多台机器上并行执行,并使用较小的内存就能运行。他冥思苦想,终于想到了一个朴素但有效的办法。
还是以计算日活跃为例。他先把某一天的日志文件从头至尾顺序扫描一遍,得到10个用户ID文件。对于日志文件中出现的每个用户ID,他通过计算用户ID的哈希值,来决定把这个用户ID写入这10个文件中的哪一个。由于是顺序处理,这一步执行所需要的内存并不大,而且速度也比较快。
然后,他把得到的10个文件拷贝到不同的机器上,分别进行排序、去重,并计算各自的独立用户数。由于10个文件中的用户ID相互之间没有交集,所以最后把计算出来的10个独立用户数直接加起来,就得到了这一天的日活跃数据。
依靠这种方法,小白把需要处理的数据规模降低到了原来的1/10。他发现,不管原始数据文件多么大,他只要在第一步扫描处理文件的时候选择拆分的文件数多一些,总能把统计问题解决掉。但是,他也看到了这种方法的一些缺点:
- 第一步扫描处理文件的过程仍然是顺序的,虽然内存占用不多,但速度上不去。
- 拆分后的文件要全部拷贝到别的机器上,跨机器的网络传输也很耗时。
- 最重要的一个问题,这全部的过程相当繁琐,极易出错,且不够通用。
特别是最后这个问题,让小白很是苦恼。看起来每次统计过程类似,似乎都在重复劳动,但每次又都有些不一样的地方。比如,是根据什么规则进行文件拆分?拆分到多少份?拆分后的数据文件又是怎么处理?哪些机器空闲能够执行这些处理?都要根据具体的统计需求和计算过程来定。
整个过程没法自动化。小白虽然手下招了两个实习生来分担他的工作,但涉及到这种较大数据量的统计问题时,他还是不放心交给他们来做。
于是,小白在思考,如何才能设计出一套通用的数据计算框架,让每个会写脚本的人都能分布式地运行他们的脚本呢?
这一思考就是三年。在这期间,他无数次地感觉到自己已经非常接近于那个问题背后的本质了,但每次都无法达到融会贯通的那个突破点。
而与此同时,公司的业务发展也进入了瓶颈期。小白逐渐认识到,在原有的业务基础上进行精耕细作的微小改进,固然能带来一定程度的提升,但终究无法造就巨大的价值突破。这犹如他正在思考的问题,他需要换一个视野来重新审视。
正在这时,另一家处于高速增长期的互联网公司要挖他过去。再三考虑之后,他选择了一个恰当的时机提交了辞职信,告别了他的第二份工作。
小白在新公司入职以后,被分配到数据架构组。他的任务正是他一直想实现的那个目标:设计一套通用的分布式的数据计算框架。这一次,他面临的是动辄几个T的大数据。
小白做了无数次调研,自学了很多知识,最后,他从Lisp以及其它一些函数式语言的map和reduce原语中获得了灵感。他重新设计了整个数据处理过程,如下图:
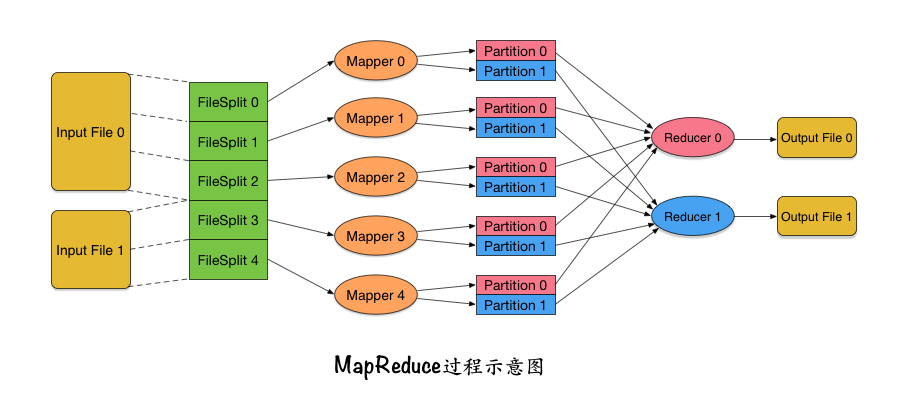
- (1) 输入多个文件。很多数据统计都需要输入多个文件,比如统计周活跃就需要同时输入7个日志文件。
- (2) 把每个文件进行逻辑分块,分成指定大小的数据块,每个数据块称为InputSplit。
- 由于要处理很大的文件,所以首先必须要进行分块,这样接下来才便于数据块的处理和传输。
- 而且,这里的文件分块是与业务无关的,这与小白在上家公司根据计算某个哈希值来进行文件拆分是不同的。之前根据哈希值进行的文件拆分,需要编程人员根据具体统计需求来确定如何进行哈希,比如根据什么字段进行哈希,以及哈希成多少份。而现在的文件分块,只用考虑分块大小就可以了。分块过程与业务无关,意味着这个过程可以写进框架,而无需使用者操心了。
- 另外,还需要注意的一点是,这里的分块只是逻辑上的,并没有真正地把文件切成很多个小文件。实际上那样做是成本很高的。所谓逻辑上的分块,就是说每个InputSplit只需要指明当前分块是对应哪一个文件、起始字节位置以及分块长度就可以了。
- (3) 为每一个InputSplit分配一个Mapper任务,它允许调度到不同机器上并行执行。这个Mapper定义了一个高度抽象的map操作,它的输入是一对key-value,而输出则是key-value的列表。这里可能产生的疑问点有下面几个:
- 输入的InputSplit每次传多少数据给Mapper呢?这些数据又是怎么变成key-value的格式的呢?实际上,InputSplit的数据确实要经过一定的变换,一部分一部分地变换成key-value的格式传进Mapper。这个转换过程使用者自己可以指定。而对于一般的文本输入文件来说(比如访问日志),数据是一行一行传给Mapper的,其中value=当前行,key=当前行在输入文件中的位置。
- Mapper里需要对输入的key-value执行什么处理呢?这其实正是需要使用者来实现的部分。一般来说呢,需要对输入的一行数据进行解析,得到关键的字段。以统计日活跃为例,这里至少应该从输入的一行数据中解析出“用户ID”字段。
- Mapper输出的key和value怎么确定呢?这里输出的key很关键。整个系统保证,从Mapper输出的相同的key,不管这些key是从同一个Mapper输出的,还是从不同Mapper输出的,它们后续都会归类到同一个Reducer过程中去处理。比如要统计日活跃,那么这里就希望相同的用户ID最终要送到一个地方去处理(计数),所以输出的key就应该是用户ID。对于输出日活跃的例子,输出的value是什么并不重要。
- (4) Mapper输出的key-value列表,根据key的值哈希到不同的数据分块中,这里的数据块被称为Partition。后面有多少个Reducer,每个Mapper的输出就对应多少个Partition。最终,一个Mapper的输出,会根据(PartitionId, key)来排序。这样,Mapper输出到同一个Partition中的key-value就是有序的了。这里的过程其实有点类似于小白在前一家公司根据哈希值来进行文件拆分的做法,但那里是对全部数据进行拆分,这里只是对当前InputSplit的部分数据进行划分,数据规模已经减小了。
- (5) 从各个Mapper收集对应的Partition数据,并进行归并排序,然后将每个key和它所对应的所有value传给Reducer处理。Reducer也可以调度到不同机器上并行执行。
- 由于数据在传给Reducer处理之前进行了排序,所以前面所有Mapper输出的同一个Partition内部相同key的数据都已经挨在了一起,因此可以把这些挨着的数据一次性传给Reducer。如果相同key的数据特别多,那么也没有关系,因为这里传给Reducer的value列表是以Iterator的形式传递的,并不是全部在内存里的列表。
- Reducer在处理后再输出自己的key-value,存储到输出文件中。每个Reducer对应一个输出文件。
上面的数据处理过程,一般情况下使用者只需要关心Map(3)和Reduce(5)两个过程,即重写Mapper和Reducer。因此,小白把这个数据处理系统称为MapReduce。
还是以统计日活跃为例,使用者需要重写的Mapper和Reducer代码如下:
public class MyMapper
extends Mapper<Object, Text, Text, Text> {
private final static Text empty = new Text("");
private Text userId = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
//value格式: [时间] [用户ID] [操作名称] [其它参数...]
StringTokenizer itr = new StringTokenizer(value.toString());
//先跳过第一个字段
if (itr.hasMoreTokens()) itr.nextToken();
if (itr.hasMoreTokens()) {
//找到用户ID字段
userId.set(itr.nextToken());
//输出用户ID
context.write(userId, empty);
}
}
}
public class MyReducer
extends Reducer<Text,Text,Text,Text> {
private final static Text empty = new Text("");
public void reduce(Text key, Iterable<Text> values,
Context context
) throws IOException, InterruptedException {
//key就是用户ID
//重复的用户ID只输出一个, 去重
context.write(key, empty);
}
}
假设配置了r个Reducer,那么经过上面的代码执行完毕之后,会得到r个输出文件。其中每个文件由不重复的用户ID组成,且不同文件之间不存在交集。因此,这些输出文件就记录了所有日活跃用户,它们的行数累加,就得到了日活跃数。
设计出MapReduce的概念之后,小白发现,这是一个很有效的抽象。它不仅能完成平常的数据统计任务,它还有更广泛的一些用途,下面是几个例子:
- 分布式的Grep操作。
- 反转网页引用关系。这在搜索引擎中会用到。输入数据是网页source到网页target的引用关系,现在要把这些引用关系倒过来。让Mapper输出(target, source),在Reducer中把同一个target页面对应的所有source页面归到一起,输出:(target, list(source))。
- 分布式排序。本来每个Reducer的输出文件内部数据是有序的,但不同Reducer的输出文件之间不是有序的。为了能做到全局有序,这里需要在Mapper完成后生成Partition的时候定制一下划分规则,保证Partition之间是有序的即可。
故事之外的说明:
首先,本文出现的故事情节纯属虚构,但里面出现的技术和思考是真实的。本文在尝试用一个前后贯穿的故事主线来说明数据统计以及MapReduce的设计思路,重点在于思维的前后连贯,而不在于细节的面面俱到。因此,有很多重要的技术细节是本文没有涵盖的,但读者们可能需要注意。比如:
- 本文假设数据都在访问日志中能够取到。实际中要复杂得多,数据有很多来源,格式也会比较复杂。在数据统计之前会有一个很重要的ETL过程(Extract-Transform-Load)。
- 本文在介绍MapReduce的时候,是仿照Hadoop里的相关实现来进行的,而Hadoop是受谷歌的Jeffrey Dean在2004年发表的一篇论文所启发的。那篇论文叫做《MapReduce: Simplified Data Processing on Large Clusters》,下载地址:http://research.google.com/archive/mapreduce.html。
- 本文没有对Hadoop集群的资源管理和任务调度监控系统进行介绍,在Hadoop里这一部分叫做YARN。它非常重要。
- 为了让Mapper和Reducer在不同的机器上都能对文件进行读写,实际上还需要一个分布式文件系统来支撑。在Hadoop里这部分是HDFS。
- Hadoop和HDFS的一个重要设计思想是,移动计算本身比移动数据成本更低。因此,Mapper的执行会尽量就近执行。这部分本文没有涉及。
- 关于输入的InputSplit的边界问题。原始输入文件进行逻辑分块的时候,边界可能在任意的字节位置。但对于文本输入文件来说,Mapper接收到的数据都是整行的数据,这是为什么呢?这是因为对一个InputSplit进行输入处理的时候,在边界附近也经过了特殊处理。具体做法是:在InputSplit结尾的地方越过边界多读一行,而在InputSplit开始的时候跳过第一行数据。
- 在每个Mapper结束的时候,还可以执行一个Combiner,对数据进行局部的合并,以减小从Mapper到Reducer的数据传输。但是要知道,从Mapper执行,到排序(Sort and Spill),再到Combiner执行,再到Partition的生成,这一部分相当复杂,在实际应用的时候还需深入理解、多加小心。
- Hadoop官网的文档不是很给力。这里推荐一个介绍Hadoop运行原理的非常不错的网站:http://ercoppa.github.io/HadoopInternals/。
(完)
其它精选文章:
- Redis内部数据结构详解(6)——skiplist
- 你需要了解深度学习和神经网络这项技术吗?
- 论人生之转折
- 技术的正宗与野路子
- 程序员的那些反模式
- 程序员的宇宙时间线
- Android端外推送到底有多烦?
- Android和iOS开发中的异步处理(四)——异步任务和队列
- 用树型模型管理App数字和红点提示
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-hadoop-mapred.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。

最新文章
- 为什么agent和workflow可以融合在同一个架构里?
- 万字长文!两栖模式构建Agent,与OpenClaw/Hermes不一样的解法——开源AmphiLoop
- Claude Managed Agents意味着什么?
- 【开源】专为「探路+编码」范式设计的全新浏览器工具集+Skills
- 不用手写一行代码,10分钟立等可取,爬取twitter和github动态
- 使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
- 过年了,聊聊AI和人文
- 使用Bridgic长程自主模块+MCP,控制你的浏览器
- AI智能体纪元或将从2026开始归零
- 从Python异步编程的剖析中体会智能体并发编程模式