技术变迁中的变与不变:如何更快地生成token?
2024-06-02
未来何时到来,取决于我们能以多快的速度生成 token。
随着GenAI的发展,我们迎来了一个崭新的技术时代。然而,由于LLM庞大的参数规模,在现代的AI系统中,LLM的推理 (inference) 性能就成为一个格外重要的技术问题。提升LLM推理的性能,更快地生成token,同时也意味着运营成本的降低。
在本文中,围绕LLM推理服务的性能问题,我们将从以下几个方面展开讨论:
- 首先,从系统外部的视角,应该如何对系统进行度量?我们应该关心哪些性能指标?跟传统的系统相比,又有什么异同?问题的答案决定了系统设计目标,也决定了我们进一步思考的方向。
- 从性能的角度出发,如何理解系统的本质?我们追求fundamental的东西——那些不随着技术变迁而变化的原则。这要求我们透过系统表层的千变万化,从底层逻辑的层面对系统进行建模。
- 从理论回到现实,以vLLM为例,我们讨论一下,真实的推理系统是做了哪些重要的优化以提升性能的。在这部分,我们也会涉及到影响推理性能的一些参数配置细节。
- 最后,我们结合前面分析的过程,展开描述一下工程设计中的系统化思维。这是比具体的知识更重要的东西。
对系统如何度量?
我们应该关心哪些性能指标?这是系统设计中一个非常重要的问题。而且,这不是一个新问题。想想跑在互联网上的那些应用系统,诸如搜索引擎、Feeds流、电商交易系统,我们当时是怎么描述系统的性能的?
很多人会想到QPS (queries per second) 或 TPS (transactions per second)。没错,它们表达了系统的一个重要的性能指标,称为吞吐量 (Throughput)。QPS或TPS都是系统吞吐量的度量单位,表达了单位时间内系统所能处理的请求数。也可以用requests per second(每秒请求数)来表示吞吐量。
吞吐量为什么重要?因为它表达了系统整体的处理能力。吞吐量越高,系统就可以用更少的资源来处理同样的请求,也就意味着更低的单位成本。
然而,我们只考虑吞吐量够用吗?答案是否定的。现代的系统很多都是在线系统 (online serving),不仅要求单位时间内尽量服务尽可能多的请求(用户),也要求单个请求的响应时间 (Response Time) 越短越好。于是,我们得到另外一个性能指标——响应时间。
通常来说,一个系统在满负载的情况下,它的吞吐量越高,请求的平均响应时间也越短。你可能会问:两者是不是倒数的关系?比如,1秒钟处理了10个请求,也就是说吞吐量是10 requests/s,那么平均每个请求的响应时间是不是1/10 = 0.1s呢?
不完全是。如果系统完全是串行执行的,前一个请求处理完才能处理下一个请求,那么响应时间确实是0.1s。但是,现代系统都有一定的并行执行能力,这就让情况不同了。假设一个系统内部有10个并行的、独立的、同构的 (parallel, independent, homogeneous) 的服务通道 (service channel),那么10个请求可以并行执行,每个请求都执行1s,也可以在1s内将10个请求都执行完。这样算下来的话,系统的吞吐量是10 requests/s,而平均响应时间则是1s。这也是Cary Millsap在十几年前的一篇经典blog[1]中举的一个例子。因此,从吞吐量不能推导出响应时间。
在接下来的讨论中,我们会看到,服务通道是其中一个重要的内部变量。不过现在,我们暂时先把关注点放在系统外部。通常来说,鉴于系统的复杂性,我们需要同时使用吞吐量和响应时间来度量一个系统。大体上可以这样理解:
- 吞吐量关注系统整体性能,与系统的成本有关。
- 响应时间关注单个请求,跟用户的体验有关。
现在,我们就来看看现代的LLM推理系统,情况有没有变化。当然,有些东西没有变。我们仍然应该关注吞吐量和响应时间,它们对于系统性能的描述能力,跟什么类型的系统无关,跟技术的新旧也无关。
但是,毕竟LLM推理系统也有一些不一样的地方。最大的一个不同在于,LLM生成的是一个长的sequence,一个token一个token的流式输出。这是由Decoder-Only的语言模型架构所决定的,它自回归式的 (auto-regressive) 生成方式正是如此。这也意味着,LLM推理系统对于请求的响应,存在一个显著的持续时间(若干秒、十几秒,甚至几十秒)。
在我们前面的分析中,那些互联网时代的「旧系统」,请求的响应时间通常是非常短的,以毫秒计。因此我们以request作为吞吐量和响应时间的基本计量单位。切换到LLM推理系统,一个请求本身包含很多token,同时也会生成很多token。我们仍然可以以 requests/s 来表示吞吐量,但业界通常换算到更细的粒度,也就是token的粒度,就得到了大家常说的 tokens/s。
那么,响应时间怎么表示呢?仍然是换算成token粒度,且业界常用的词汇是延迟 (Latency)。比如,在PagedAttention的论文中[2],作者使用了 Normalized Latency这个度量,它定义为:每个请求的端到端的延迟(也就是系统从收到一个请求直到最后一个token生成完毕的持续时间)除以生成的token数,再对于所有请求计算平均值。它的度量单位是s/token。
前面我们说过,响应时间跟用户体验有关。因此,判断响应时间的度量单位是否合理,也应该从用户体验的角度来考虑。对于一个典型的LLM应用来说,通常第一个token的生成延迟(系统从收到一个请求直到第一个token生成完毕的持续时间)会比较高,远大于相邻token之间的生成延迟。而第一个token何时生成,是一个比较重要的用户体验。所以呢,我建议把首token的生成延迟也作为系统响应时间的另外一个度量。
总结一下,对于LLM的推理系统来说,我们需要使用至少三个性能指标来对它进行度量:
- 每秒生成的token数 (tokens/s),作为吞吐量的度量。
- 首token的生成延迟,作为响应时间的一个度量。
- Normalized Latency,作为响应时间的另一个度量。
对系统如何建模?
前面我们讨论了性能指标。这相当于是说,我们从外部观察系统,可以得到一些度量的数值。然后我们用这些数值来描述系统的性能表现。
这非常有用。这些性能指标可以揭示系统的现状和问题。但是,如果我们想进一步分析问题根源,找出优化的方向,则需要对系统运行的内部机制进行建模 (modeling) 。「建模」是一个由具体到抽象、由现实到理论的过程,需要从逻辑层面对事物的运行机制进行描述。这里可以参见我之前的一篇文章《谈谈业务开发中的抽象思维》,其中谈到的抽象思维的第二个阶段,就是一个「建模」的过程。
理想情况下,我们可以借助排队论 (Queueing Theory) 中的「M/M/m」队列[3]来表示一个在线系统。如下图:
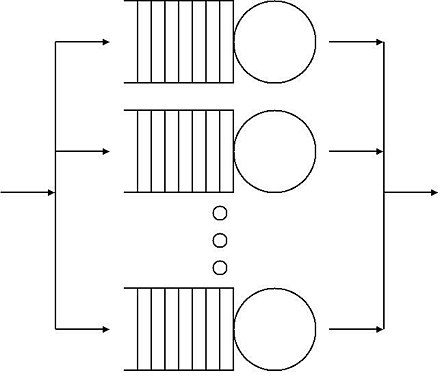
显然,这是一个「理论模型」,对实际的系统进行了抽象和简化。它有严格的计算公式,大写的M表示马尔科夫过程 (Markov) ,小写的m表示m个服务通道。但我不打算在这里讨论数学上的细节,而是举个生活中的例子来做类比说明。
假设我们去银行营业厅办理业务,银行开设了多个服务窗口来服务客户。我们可以把这些银行窗口的整个服务过程近似看作一个「M/M/m」系统:
- 营业厅中不断有新的客户到来。客户到达的速率越快,表示工作负载越大。一旦超过银行窗口的服务能力,客户就不得不排队等待。
- 每个窗口是一个单独的服务通道。
- 如果想增加整体营业厅接待客户的服务能力,有两个途径。一个是增加更多服务窗口,另一个是提升每个窗口营业员的处理速度,从而降低服务时间。
- 每位客户总共需要在银行营业厅逗留的时间,包括两部分:一个是排队等待的时间,一个是窗口的服务时间。
现在重新回到计算机系统,我们来做一个对比:
- 首先,每位客户的逗留时间,就对应了系统的响应时间。目前来看,它由两部分组成:服务时间 (service time) + 排队延迟 (queueing delay)。
- 单个银行窗口的服务时间,对应单个计算单元的计算能力。计算能力强,服务时间就短。对应到LLM的推理系统上,主要是由GPU的算力决定的,每秒能处理多少次浮点运算 (FLOPS)。算力总会有一个上限,所以服务时间不可能降低到零。
- 银行的多个服务窗口,对应了多个服务通道,表达了系统的并行执行能力。在LLM推理系统上,相当于batching的能力。一次计算不是只处理一个请求,而是把多个请求一起打包,可以批量计算。
- 排队延迟有多大,很大程度上取决于工作负载 (workload) 是否超过了系统容量。对应到银行营业厅的例子中,到达的客户多,表示工作负载就大。客户很少的时候,每个人都不用排队,排队延迟就是零;相反,客户非常多的时候,超过了银行的接待能力,每位客户就需要花更多的时间来等待服务窗口可用,排队延迟就变得很大。
- 最后,从吞吐量的角度来简单地总结一下。银行营业厅每小时能接待多少位客户,就对应了系统的吞吐量。当到达的客户足够多的时候,吞吐量主要取决于营业厅的接待能力(系统容量)。可以分成两个方面:单个窗口的服务时间越短,并且开设的服务窗口数量越多,整体吞吐量越高。用计算机系统的语言来重新描述:算力越强,并行的服务通道越多,系统整体的吞吐量就越高。
在以上的描述中,我们反复提到了一些概念,比如吞吐量、响应时间、工作负载、算力、服务通道、系统容量、服务时间、排队延迟,等等。这些概念之间是什么关系呢?它们是否是同一个逻辑层面的概念?我们把这些概念画在一个图中:
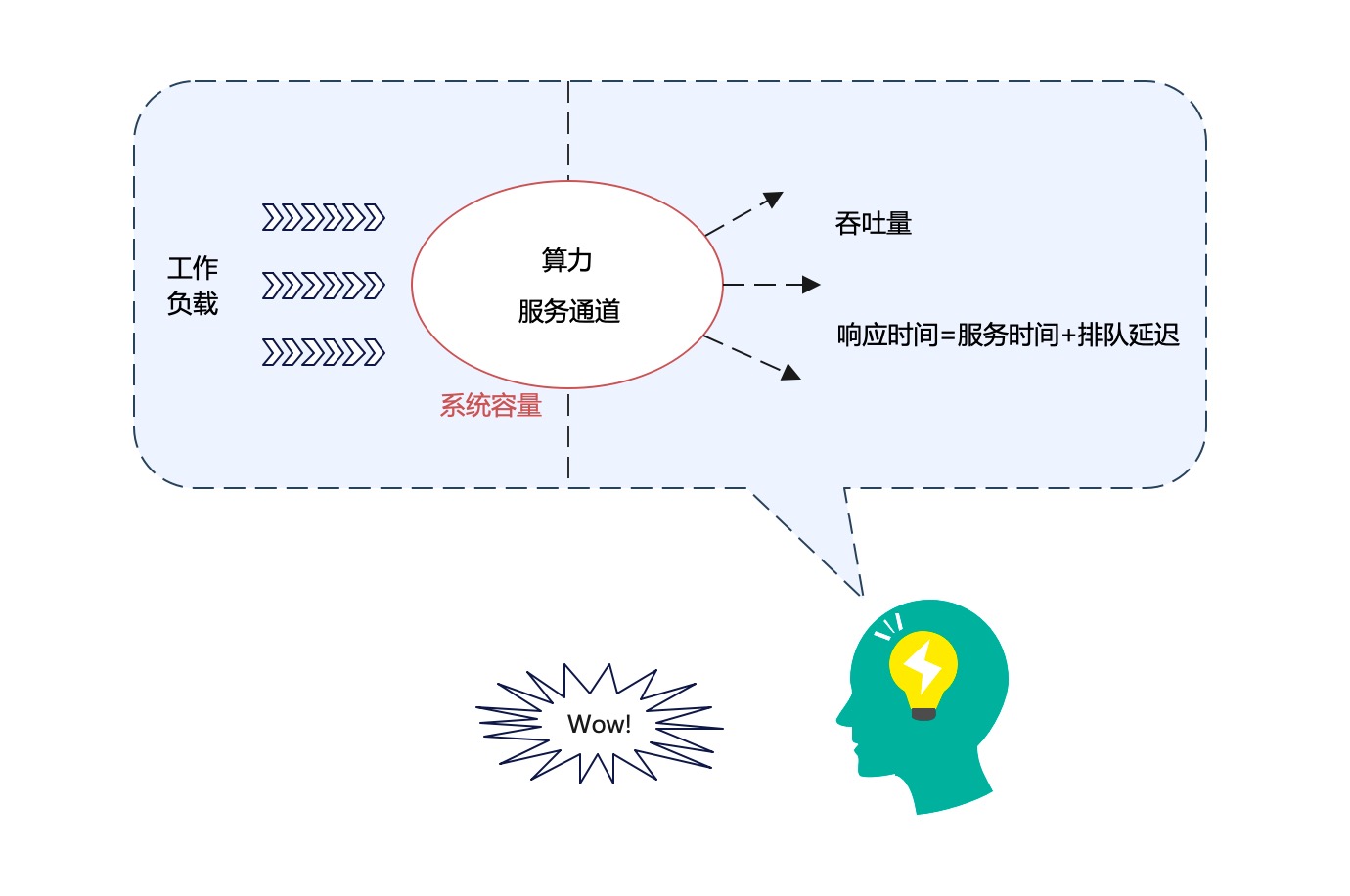
我们来解释一下上图:
- 首先,分清系统固有的属性和外在的因素,对于理清概念之间的逻辑关系,很重要。
- 系统容量 (system capacity),是系统固有的属性。决定系统容量大小的核心因素,包括算力和服务通道(但不是全部因素)。
- 其他概念都属于系统的外在因素。不过,分清因果关系仍很重要。
- 工作负载施加在系统上,系统就表现出一定的性能指标,也就是吞吐量和响应时间。大体上说,前者是因,后者是果。
再着重补充说明一下工作负载的概念。对于固定的某个系统来说,它的吞吐量和响应时间,随着工作负载的高低变化而变化。由于系统有一个固有的系统容量,所以根据工作负载的高低,我们在对系统性能进行度量时,经常需要区分两种情况:
- 轻负载的情况:工作负载小于系统容量。
- 满负载的情况:工作负载超过了系统容量。
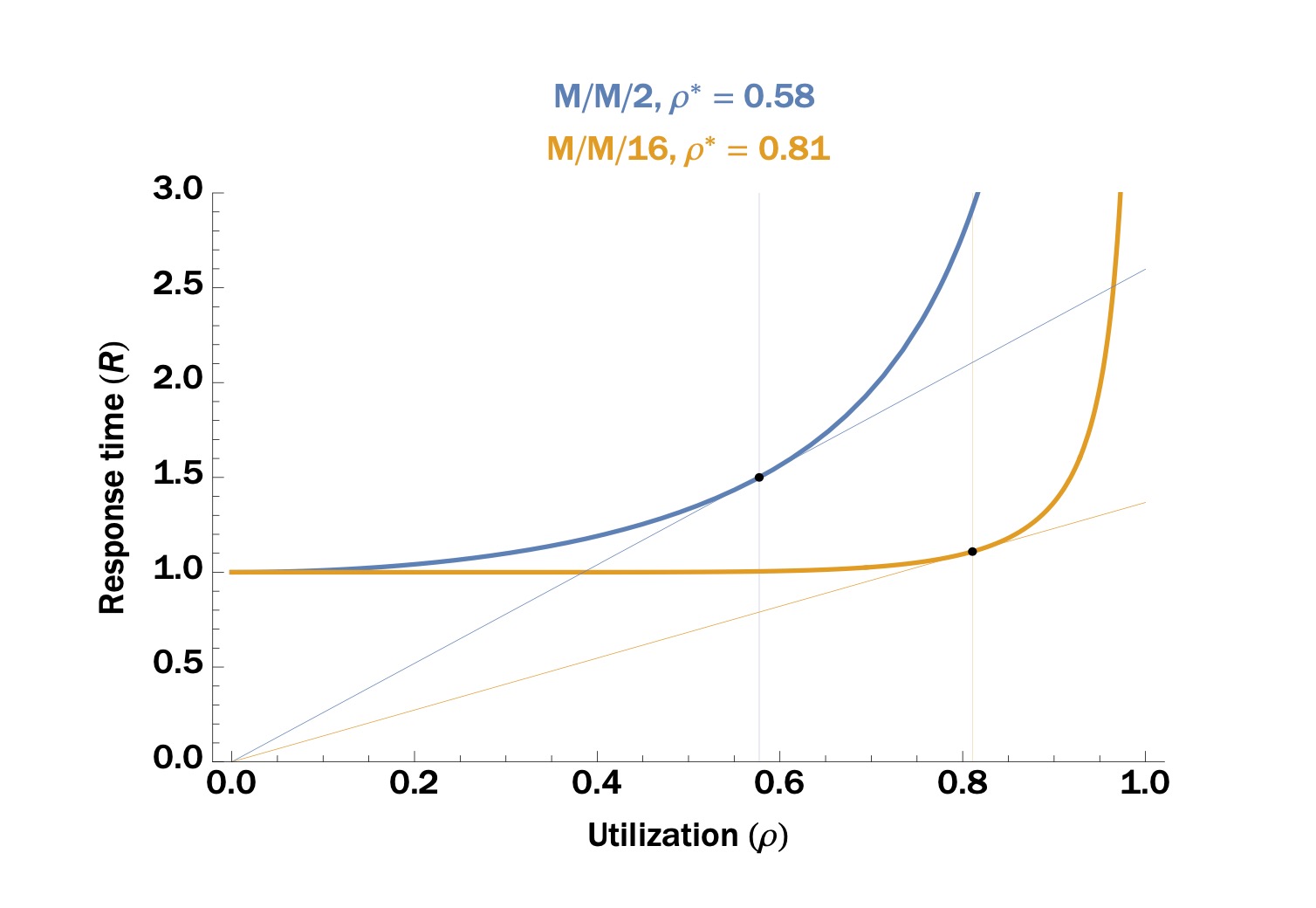
上图出自blog[1],表达了一个「M/M/m」系统的响应时间随工作负载的变化曲线。在这个图中,x轴的资源利用率 (utilization) 是工作负载的一种度量方式。可以看出,这个曲线也明显呈现出了两个阶段:
- 轻负载阶段:响应时间随工作负载的增大,仅有轻微的增加。
- 满负载阶段:响应时间随工作负载的增大而迅速增加。主要原因在于,排队延迟急剧增加。
两个阶段的交界点,就是系统的拐点 (knee),也就是图中ρ*的位置。
对于任何并发在线系统来说,这个曲线画出来,形状也都是类似的。比如,在PagedAttention的论文中[2],推理系统的响应时间随工作负载的变化曲线如下:
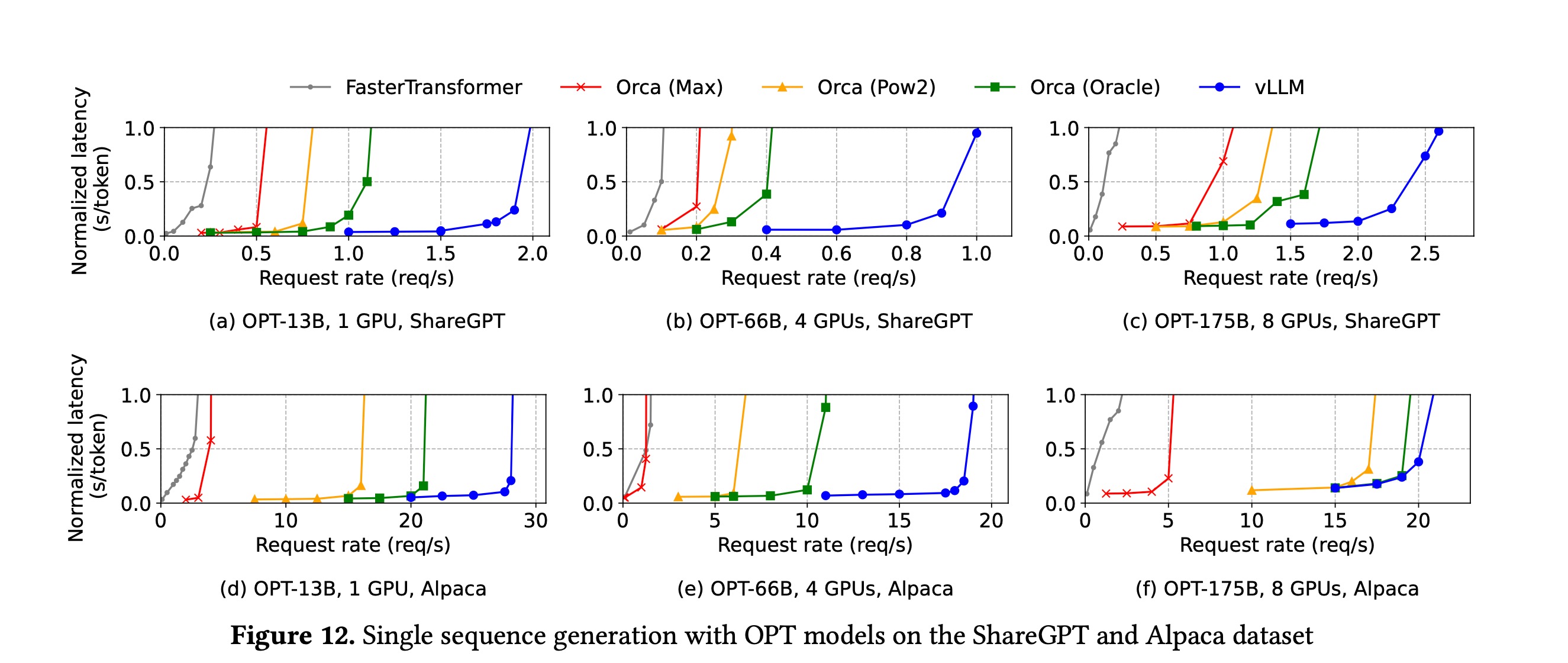
注意在这个图中,x轴用req/s (每秒请求数) 来表示工作负载;y轴的Normalized Latency是响应时间的一个度量方式。
当然,我们也可以画出系统的吞吐量随工作负载的变化曲线。容易想象出曲线的形状:
- 在拐点之前,吞吐量随着工作负载增加而升高。
- 在拐点之后,吞吐量不再随工作负载增加而有显著变化,而是保持相对平稳的值(只要系统没有宕机)。
到现在为止,从性能表征的角度对系统的运行机制进行建模,这个任务就基本完成了。哪些是系统的固有属性,哪些是外在因素,外在因素和固有属性之间的相互作用关系如何,也都基本清楚了。不过,如果我们把关注点放在系统内部的细节上,会发现,还有一个关键的因素被遗漏了。这个关键因素被称为相关性 (Coherency) [1]。
在理想的「M/M/m」系统中,多个服务通道之间是完全独立的。但在真实的系统中,服务通道之间不可能独立,它们肯定是有相关性的。相关性通常表达了不同请求之间对于共享资源的竞争关系。比如,在传统的互联网应用系统中,不同的请求经常会访问同样的一份数据,对于共享资源的访问会导致额外的相关性延迟 (coherency delay)。这是分布式系统设计的核心挑战之一。特别是当工作负载越过系统拐点之后,相关性延迟通常会非常显著地表现出来。
考虑到相关性和拐点这两个重要概念之后,前面的概念图在修改之后就变成了:
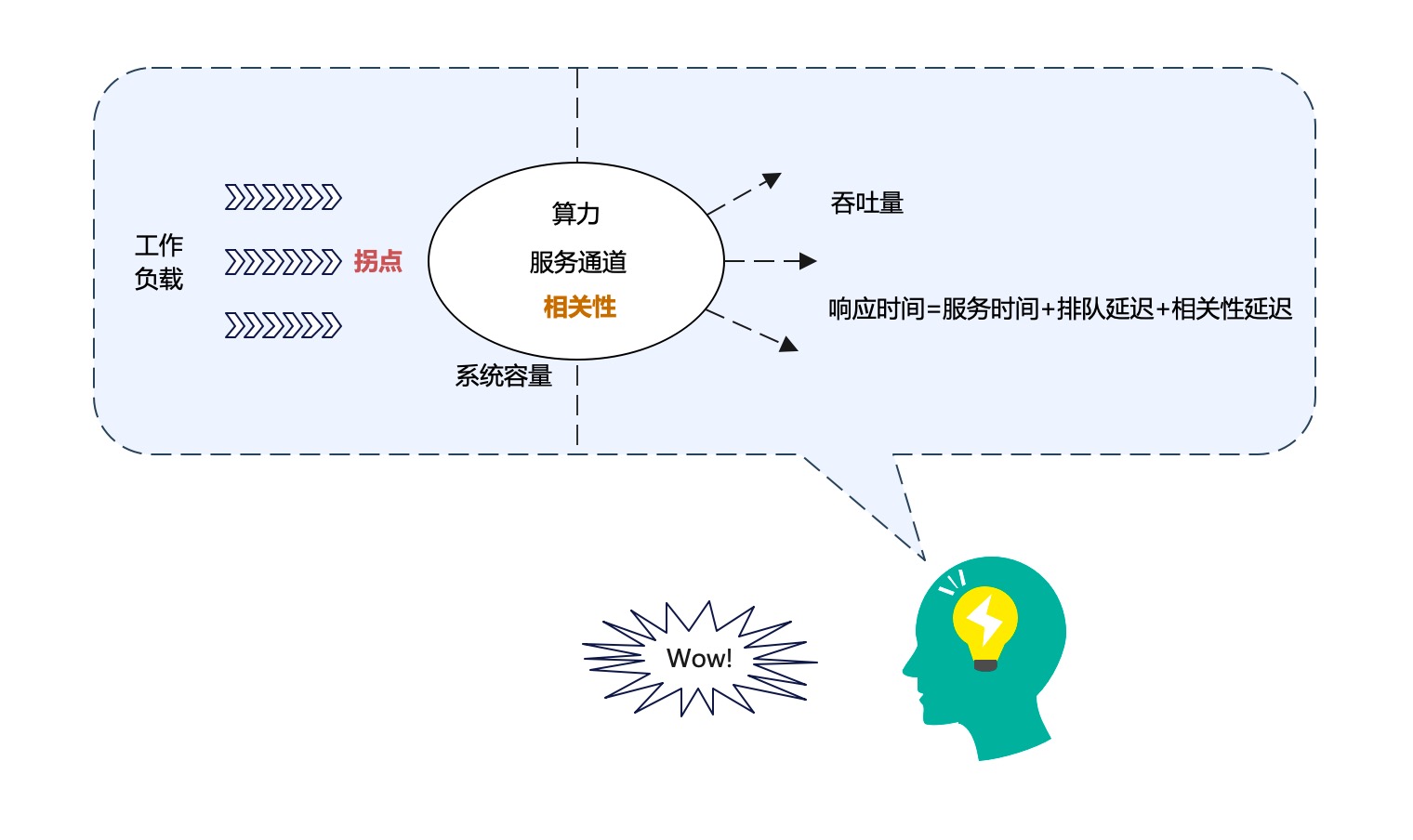
我们基本上已经得到了对于系统性能进行分析的逻辑框架(建模的结果)。我们重新概括总结一下:
- 算力、服务通道、相关性几个因素,都属于系统的固有属性,它们共同决定了系统容量。
- 在系统上施加一定的工作负载,系统就对外表现出相应的性能指标。必须同时使用吞吐量和响应时间来度量一个在线系统。
- 在拐点前后,工作负载对于系统性能指标的影响,具有显著的不同。
- 响应时间由三部分组成:服务时间+排队延迟+相关性延迟。
分析一下vLLM
以上逻辑框架是抽象的。之所以总结这样一个逻辑框架,其实有三个目标:
- 【度量】指导我们全面地度量一个系统的性能。
- 【使用】指导我们如何使用系统。对于一个已有的系统,施加多少工作负载是合适的?
- 【优化】指导我们如何改变系统的固有属性,从而优化系统在固定工作负载下的性能指标。
本节我们以vLLM[4](一个高性能的大模型推理引擎)为例来具体分析这三个目标。
首先来看度量的问题。
我们已经在第一小节得到了针对LLM推理系统的三个性能指标:吞吐量(每秒生成的token数)、首token的生成延迟、Normalized Latency。考虑到工作负载(每秒请求数)对于系统性能的影响,为了全面刻画系统的性能表现,我们可以画出三类性能曲线:
- 每秒生成的token数随工作负载的变化曲线。
- 首token的生成延迟随工作负载的变化曲线。
- Normalized Latency随工作负载的变化曲线。
再来看使用的问题。
我们希望系统承载尽可能多的工作负载,这样才能达到最低的单位成本。但是,工作负载增加到一定程度,延迟就会大幅增加。那么,给系统施加多少工作负载才是最优的呢?答案是,让工作负载处于接近拐点的位置。这时候,系统的吞吐量接近最高值,而延迟也还没有大幅增加。
当流量增加,导致工作负载越过了拐点,就应该进行系统扩容了。通过增加更多的计算节点,来让单个节点的工作负载降下来,直到降低到拐点以下。
最后,以vLLM为例,来说说优化的问题。这个问题稍微复杂一些。
vLLM采用PagedAttention算法[2],对推理性能做了很多优化。根据上一小节的逻辑框架,我们应该从算力、服务通道、相关性这三个维度去理解。
概括起来,vLLM对于推理性能的优化,主要可以归结在两个方面:
- 第一,从提升服务通道数目的角度。
- 第二,从降低相关性的角度。
具体来看,提升服务通道的数目,是如何做到的呢?
- 一方面,它做了batching,把临近到达的多个请求放在一起,批量去做生成的计算。这样做可以更好地利用GPU的并行计算能力,相当于提升了服务通道的数目。。
- 另一方面,PagedAttention算法通过对显存进行分块 (block) ,并进行了逻辑块和物理块两级管理,提高了显存利用率。因此,同样大小的显存资源,就可以容纳更多请求的KV cache。于是,这就允许在一个batch中放入更多的请求,进一步提升了服务通道的数目。
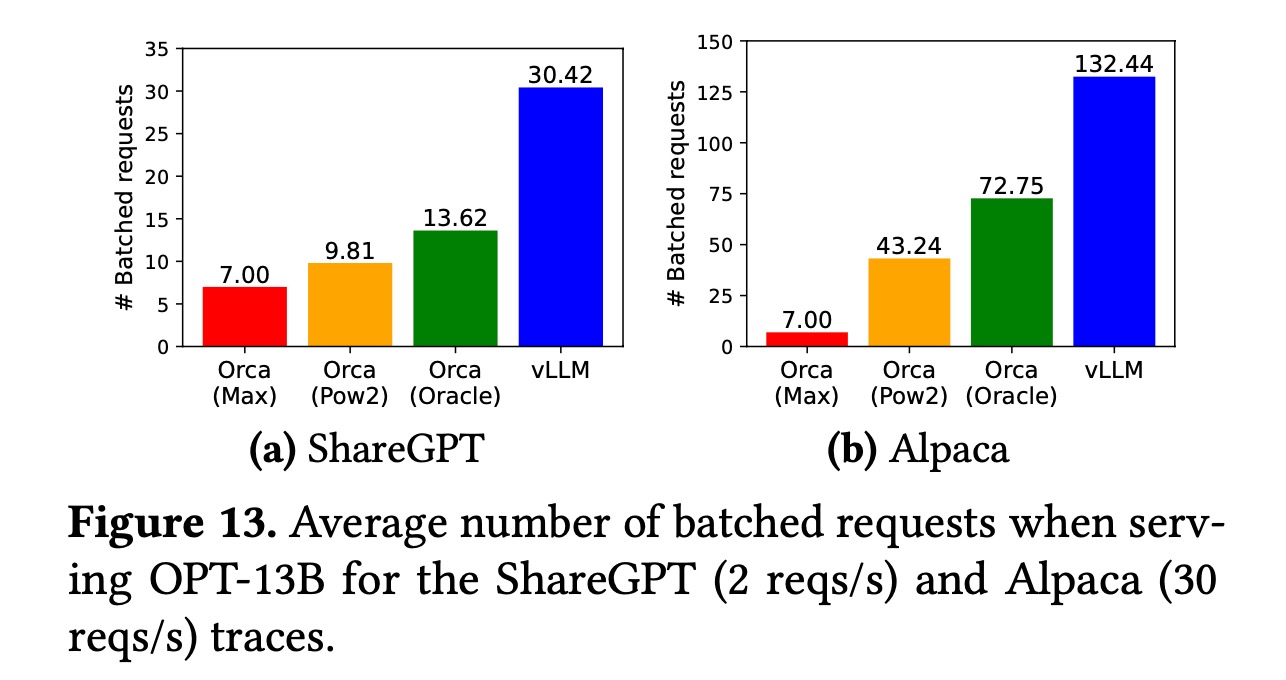
上图出自PagedAttention论文[2],y轴的「# Batched requests」就表示在一个batch中放入的平均请求数,相当于服务通道的数目。
这里我们着重分析一下提高显存利用率的具体做法。为什么vLLM很大程度上是在做显存管理?据PagedAttention的论文[2]所述,GPU计算能力的增长速度,快于显存容量的增长速度。这导致计算能力和显存容量之间的gap越来越大,显存容量逐渐成为了系统瓶颈。因此,vLLM借鉴了操作系统的虚拟内存分页机制,设计了非常精细的显存管理方案,使得整个sequence不必存储于连续的显存空间内。这种方案,加上合适的block大小设置,完全杜绝了外部碎片 (external fragmentation) ,并极大降低了内部碎片 (internal fragmentation) 。最终带来的结果就是,降低了显存浪费,提高了显存利用率。
再看一下另外一个方面,vLLM是如何降低相关性的呢?
依据LLM推理场景工作负载的流量特征,本来是存在一些不利因素,它们是倾向于使相关性增加的:
- 其中一个不利因素,在于请求的超大颗粒度 (granularity) 。每个请求都可能生成一个很长的sequence,每个sequence都会占用非常大的显存资源(多达几个GB)。这就导致不同的请求很容易竞争同一份资源,相关性增加。解决的思路是,降低系统调度的粒度,从sequence level降低到iteration level。
- 另外一个不利因素,来源于batch操作本身。将多个请求放在一个batch中,原本不相关的请求就产生了相关性。短sequence可能受长sequence的拖累,要等到一个batch中所有sequence都生成完毕,才能最终从batch中退出,从而极大增加了生成延迟。解决的思路是blog[5]中称之为「continuous batching」的技术。
基于iteration level的调度,将一个sequence的生成,切分成多次iteration来完成。iteration又分为两种计算类型:prefill和decode。prefill的计算粒度可能仍然较大,它一般要求整个prompt的所有token都要在一个iteration中计算完毕。为了缓解这个问题,vLLM还提供了Chunked Prefill模式,允许将大的prefill操作分解成小的chunk。vLLM启动时,可以传入--enable-chunked-prefill参数来打开这种更细粒度的调度模式。
continuous batching技术,是一种高度动态的batch操作。它允许一个sequence在生成完毕后立即可以退出当前batch,从而释放资源,并能够调度新的sequence进入当前batch。这一操作,本质上是让同一个batch内的不同请求不再需要互相等待,从而消除了batch操作带来的相关性延迟。
至此,我们基本上把影响vLLM推理性能的关键因素都分析清楚了。最后,还有两个跟性能高度相关的参数,我们简单看一下:
- 一个是--max-num-seqs参数。该参数指定了每次iteration操作最多可以放入一个batch的sequence数量。相当于是系统对于服务通道数目的一个软限制。
- 另一个是--max-num-batched-tokens参数。该参数指定了每次iteration操作最多可以放入一个batch的token数量。相当于是系统对于单次计算能力(也就是算力)的一个软限制。
不变的东西
熟悉我的读者朋友们应该知道,本公众号的目标不仅仅是简单地讨论具体的技术,而是更关注认知层面的总结。因此在文章最后啰嗦几句,算是个小结。
在本文中,我们在抽象层面总结了一个逻辑框架,并结合vLLM的实例进行了具体的分析。通常来讲,具体的知识或具体的技术,在短期内是重要的,在长期看则没有那么重要。技术更新换代的速度正在加快,但总有些fundamental的东西,那些涉及到逻辑层面的本质的东西,是不随着技术变迁而变化的。因此,把相关概念的逻辑关系理清楚,是本文最重要的贡献;具体到vLLM/PagedAttention的分析以及对于三类性能曲线的定义,则是次要的结论。
在技术快速变化的环境中,面对新的框架,新的算法,新的技术变革,只要我们保持工程师的系统化思维,就总是能够从容面对。系统化思维,需要我们在更大范围内做整合,把原来看似不相关的表层概念进行抽象,才能在更高的抽象层面发现相似之处,达到融会贯通。人类知识的联想、迁移,可能性便来源于此。
我之前写过的一些跟认知有关的文章,列出几篇,供感兴趣的读者阅读:
在文本的分析中,我们提到了银行营业厅的例子。它是一个分析并发在线系统的绝佳类比。有时候,世界的本质,就隐藏在看似普通的日常现象之中。在前面的文章《卓越的人和普通的人到底区别在哪?》一文中,我还提到了一个例子,图灵奖得主Lamport当年就是从观察面包店如何服务顾客的现象中,获得了他的顿悟,从而得窥分布式系统的本质,发明了划时代意义的「面包店算法」。
你是不是已经发现了:不同的事物之间,总有那么几分相似呢?
(正文完)
参考文献:
- [1] Cary Millsap. 2010. Thinking Clearly About Performance.
- [2] Woosuk Kwon, et al. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention.
- [3] M/M/c queue
- [4] vLLM官网
- [5] Cade Daniel, et al. 2023. How continuous batching enables 23x throughput in LLM inference while reducing p50 latency.
其它精选文章:
- 企业AI智能体、数字化与行业分工
- 三个字节的历险
- 用统计学的观点看世界:从找不到东西说起
- 分布式领域最重要的一篇论文,到底讲了什么?
- 看得见的机器学习:零基础看懂神经网络
- 白话科普:Transformer和注意力机制
- 内卷、汉明问题与认知迭代
- 在技术和业务中保持平衡
- 漫谈分布式系统、拜占庭将军问题与区块链
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-vllm-perf-model.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。

最新文章
- 为什么agent和workflow可以融合在同一个架构里?
- 万字长文!两栖模式构建Agent,与OpenClaw/Hermes不一样的解法——开源AmphiLoop
- Claude Managed Agents意味着什么?
- 【开源】专为「探路+编码」范式设计的全新浏览器工具集+Skills
- 不用手写一行代码,10分钟立等可取,爬取twitter和github动态
- 使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
- 过年了,聊聊AI和人文
- 使用Bridgic长程自主模块+MCP,控制你的浏览器
- AI智能体纪元或将从2026开始归零
- 从Python异步编程的剖析中体会智能体并发编程模式