从GraphRAG看信息的重新组织
2024-08-31
GraphRAG俨然已经成为了一种新的技术路线;虽然类似的技术还有很多不成熟的地方。前几天发现,学术界已经有关于GraphRAG的综述出现了[1],链接在文末,供大家参考。
不过今天我们要讨论的重点不是这个。我想跟大家聊一聊:沿着GraphRAG的思路,在LLM的时代,信息可能以什么样的方式被重新组织?
数据的两种类型及处理路径
在一个数字化的世界里,数据有两种:一种是给人看的,一种是给机器看的。
给人看的数据,比如新闻、网页、论文、专利文本。这些数据是由人生产的,生产出来的目的也是给人看的,用于传递信息或知识。所以,它们天然就是无结构的free text。在LLM出现之前,计算机系统对这些信息进行直接处理,是很困难的。
至于另一种给机器看的数据,指的是传统计算机程序可以直接处理的结构化数据,比如xml、json、关系表格,等等。它们在计算机程序之间传递信息或指令,支撑整个系统的运转。这些数据通常有严格的schema的约束,大部分由机器产生,也由机器消费。
现在,我们把关注点放在前一类数据上。由于这部分数据是为了给人看的,所以如果涉及到对信息进行处理,就需要大量的人力参与其中。
具体需要做什么处理呢?对于一个严肃的信息获取场景来说,抽象来看,人们通常需要对数据进行三个阶段的处理:
- 检索;
- 提取;
- 整合。
举个例子,假设你的主管布置了一项任务,要求你针对某项技术调研一下业界方案。第一步,你肯定会去互联网上检索各种相关资料,查阅业界各大公司的官网、技术博客,查阅相关论文,以及检索行业会议的信息。第二步,从这些资料中提取当前关注的技术方案在各个维度的关键信息,比如各个方案的技术原理、适用范围、核心难点、优势、局限性,等等。第三步,对所有这些关键信息进行整合,得到最终结论。这个「最终结论」,一般来说是简短的、高度概括的,而且是自然语言的,给人看了用于进一步决策的。
以前的信息系统,只能辅助完成第一步的检索工作。后面的提取、整合,仍然主要是人的工作。但是LLM出现之后,后面这两步也有希望由计算机程序来处理了。
信息的组织形式
为了对海量的信息进行检索和处理,信息系统需要对数据做某种形式的提前组织。
搜索引擎算是一种传统的技术,它出于检索的目的,基于关键词将文本数据组织成倒排索引的形式。这种数据组织形式,简单可解释。
但是,这种关键词索引的数据组织形式,只能支撑粗粒度的「检索」任务。数据的存储单元,是一个完整的document。比如,一个网页是一个document,一篇新闻报道是一个document,一篇论文是一个document。我们可以根据关键词,定位到若干个document。但有两个遗留问题没有解决:
- 一个是广度的问题。在严肃的信息获取场景下,我们对于信息的完整性有比较高的要求。也就是说,用关键词检索出「某些」资料是不够的,还希望查到的资料要全。把散落到各处的信息,按照要求收集到一起,仅依靠关键词索引很难覆盖到。
- 另一个是深度的问题。通过关键词索引可以定位到document级别,但这些document内部更细粒度的信息,就需要人来提取、整合。
于是,有些人尝试从document中预先把有用的信息提取出来,做成结构化的数据。一般有两种形式:一种是知识图谱,按照实体和实体关系来组织信息,类似企查查、天眼查组织企业数据的形式;另一种是表格形式,常见的例子是金融领域的一些应用,把各个公司的历史财务信息(营业额、利润、资产负债、现金流量等)、分红派息行为、机构持股变动等信息,汇总成表格呈现给投资者。
不管是知识图谱,还是表格数据,它们都属于「给人看」的结构化数据。把这些数据生产出来,需要耗费大量的人力(机器可以辅助一部分),因此,这种人工组织信息的方式,只能在商业价值高的一些领域内小范围使用。
LLM的出现,改变了这一切。它把整个互联网上公开可访问的文本信息,压缩进了模型当中。可以想象一下,LLM把信息重新组织、重新打散,按照某种难以理解的方式,存储在了数十亿甚至数百亿个参数中。它组织信息的粒度更细。前面讲的倒排索引,组织信息的粒度是document;知识图谱和表格,组织信息的粒度是人能够理解的实体概念和实体关系;而LLM组织信息的粒度,则是一个个的token。
已经有不少研究人员在研究LLM内部的数据表示了,而且取得了一些进展。比如,Anthropic的一个研究表明,他们从Claude 3 Sonnet模型中,提取出了数百万个特征[2]。但是,LLM内部对于信息的组织形式,整体上看仍然是个黑盒。
GraphRAG带来的启示
本来人们对LLM的期望是很高的,认为它可能会颠覆知识产业。从逻辑上讲,这么想是有些道理的。既然LLM已经吃进去了互联网上所有的公开数据,将信息在内部做了重新组织,相当于学到了数据里面所表示的知识,自然可以解答信息或知识层面的「任何」问题。我们前面提到的检索、提取、整合,这三个阶段的信息处理过程,理论上LLM似乎是能端到端地做掉的。
但是,LLM在能力上目前还有两个关键的不足:一个是推理能力 (reasoning) 还达不到真实业务场景的要求;另一个是幻觉问题,这是一个顽疾。这些不足让LLM难以单独成为端到端的解决方案。
微软提出的GraphRAG方案[3],提供了一个新的思路。GraphRAG整个系统可以分成两个大的模块:Indexer和Query。Indexer负责从非结构化的文本中提取实体和实体关系,形成结构化的图谱,并支持层次化建图;Query模块则负责利用建好的图谱执行问答任务。
这里隐含着一些思路的转变。
GraphRAG仍然是按照实体和实体关系对世界进行建模的,但它按照这种图的模型对信息进行重新组织的时候,是充分利用了LLM学到的知识的。这相当于找到了一种实现路径,把关注的重点从LLM内部转移到了LLM外部。LLM内部是个黑盒,但它却有一个「人格化」的界面,输入和输出都是自然语言的。因此,利用LLM做信息的重新组织,LLM内部的知识就「外化」到了建图的过程中了,而且变成了人可以理解的形式。
这里有两个关键点需要注意:
- GraphRAG更充分利用了LLM的知识。至少是比传统的RAG更多地利用了模型的知识。在传统的RAG中,LLM主要发挥作用的地方是最后一步。它在训练阶段所学到的——对于这个世界的理解——很可能并没有充分发挥出来。而在GraphRAG中,LLM对世界的理解,体现在了对实体和实体关系的识别过程中。
- 在LLM外部对信息进行重组,意味着更加可控,也意味着人可以理解和参与这个控制工程。
可以畅想一下,如果做得足够好的话,我们可能能够得到一种新型的知识库的组织形式。它以自然语言为界面来提供对信息的查询;内部则以一种全新的方式来组织数据。这种对数据的组织,不是基于关键词的浅层的关联,而是包含了语义上的关联,包含了LLM对于世界的理解。
GraphRAG的一些实现细节
GraphRAG整个系统可以分成两个大的模块:Indexer和Query。我们这里着重对Indexer进行介绍。这个介绍包含一些技术细节,非技术同学可以跳过。
GraphRAG的Indexer模块需要对原始输入文本文件进行一系列的处理变换,形成了多个数据处理的pipeline。这些pipeline在实现中使用了DataShaper[4]的Workflow系统来完成:
- 每个数据处理pipeline使用一个Workflow来表达。比如,create_base_text_units、create_base_extracted_entities等(截止到2024.08的GraphRAG代码,共包含14个workflow)。
- 在Workflow之间,有一定的依赖关系,形成一个有向无环图DAG。这决定了Workflow哪些先执行,哪些后执行。
- 每个Workflow内部,又细分为若干个step,每个step被称为一个verb。
这个DAG如果画出来,如下图所示(点击看大图):
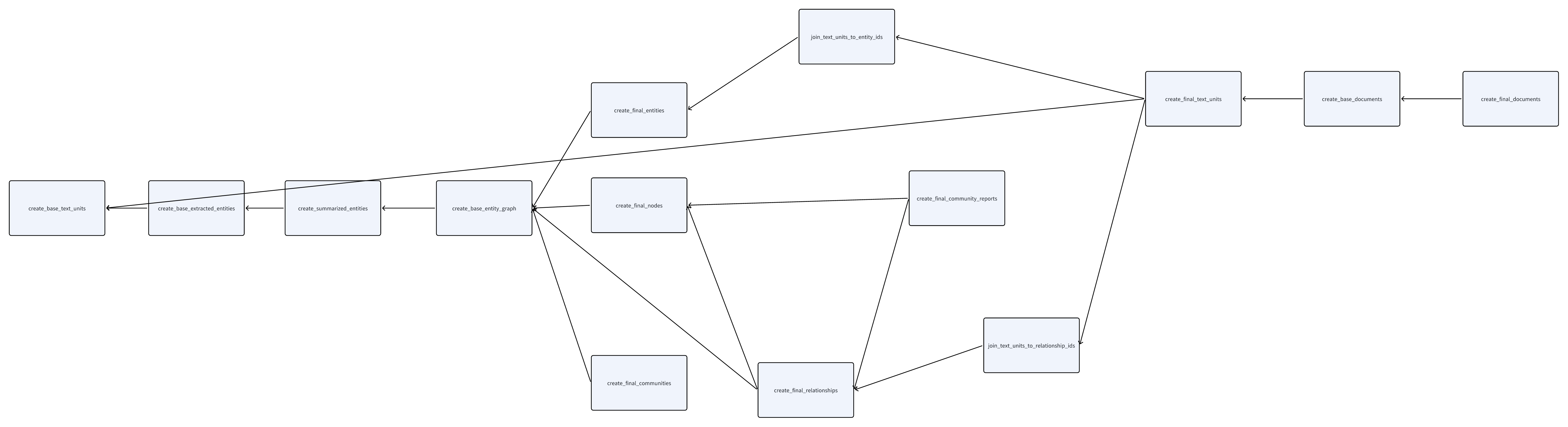
上图中每个节点表示一个Workflow。从Workflow的名字可以大体猜出来它具体执行的工作,这里就不一一介绍了。其中有个Workflow叫create_base_entity_graph,功能有点特殊,这里简单介绍两句。它实际上在执行社区检测算法(一个称为leiden的算法[5]),把关联相近的实体分割到一个子图里面。这个划分子图的过程可以递归进行,在子图中继续划分子图,从而把图建成层次化的。
不足和展望
GraphRAG提供了非常好的一种思路。但这种技术目前仍不成熟。有一些关键问题值得未来去仔细思考:
- 建模的合理性。GraphRAG的本质,还是在于应该如何对信息进行建模。它目前采取了图的方式,但不代表图这种方式就能对现实世界的信息进行全面的建模。比如历史数据、时间序列数据,如何融合到图当中?
- 图谱的规模。GraphRAG到底能支持多大规模的数据,还是未经验证的问题。它能应用到开放域,还是只能够用于特定领域?另一方面,如果数据规模很大,建图的成本也非常高。
- 如何在人为可控的方式下建图?只基于LLM来建图,会引入非常多的噪声。如何在充分利用LLM知识的基础上,把领域专家的经验也引入进来,也是非常重要的一个问题。
(正文完)
参考文献:
- [1] Boci Peng, et al. 2024. Graph Retrieval-Augmented Generation: A Survey.
- [2] Adly Templeton, et al. 2024. Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet.
- [3] Darren Edge, et al. 2024. From Local to Global: A Graph RAG Approach to Query-Focused Summarization.
- [4] DataShaper GitHub Page.
- [5] Wikipedia:leiden.
其它精选文章:
- 技术变迁中的变与不变:如何更快地生成token?
- 企业AI智能体、数字化与行业分工
- 白话科普:Transformer和注意力机制
- 三个字节的历险
- 用统计学的观点看世界:从找不到东西说起
- 分布式领域最重要的一篇论文,到底讲了什么?
- 看得见的机器学习:零基础看懂神经网络
- 内卷、汉明问题与认知迭代
- 漫谈分布式系统、拜占庭将军问题与区块链
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-graph-rag-information_org.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。

最新文章
- 为什么agent和workflow可以融合在同一个架构里?
- 万字长文!两栖模式构建Agent,与OpenClaw/Hermes不一样的解法——开源AmphiLoop
- Claude Managed Agents意味着什么?
- 【开源】专为「探路+编码」范式设计的全新浏览器工具集+Skills
- 不用手写一行代码,10分钟立等可取,爬取twitter和github动态
- 使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
- 过年了,聊聊AI和人文
- 使用Bridgic长程自主模块+MCP,控制你的浏览器
- AI智能体纪元或将从2026开始归零
- 从Python异步编程的剖析中体会智能体并发编程模式