白话科普:Transformer和注意力机制
2024-03-16
Transformer[1]是一个划时代的发明。可以说,它奠定了现代大语言模型 (LLM) 的基础。要想深入一点理解当代AI的发展,Transformer是绕不过去的一个概念。因此,本文试图做一个深入浅出的科普,希望任何一名软件工程师都能够看懂。
虽然网上已经有很多解析Transformer的文章了,但事实证明,用简单的语言讲清楚如此复杂的一个东西,这不是一个简单的任务。所以本文力求做到两点:
- 把很多相关的信息串起来。
- 在整体上尽量宏观描述,而在局部描述上又不失具体。
一些背景知识
很多人应该都见过下面这张图:
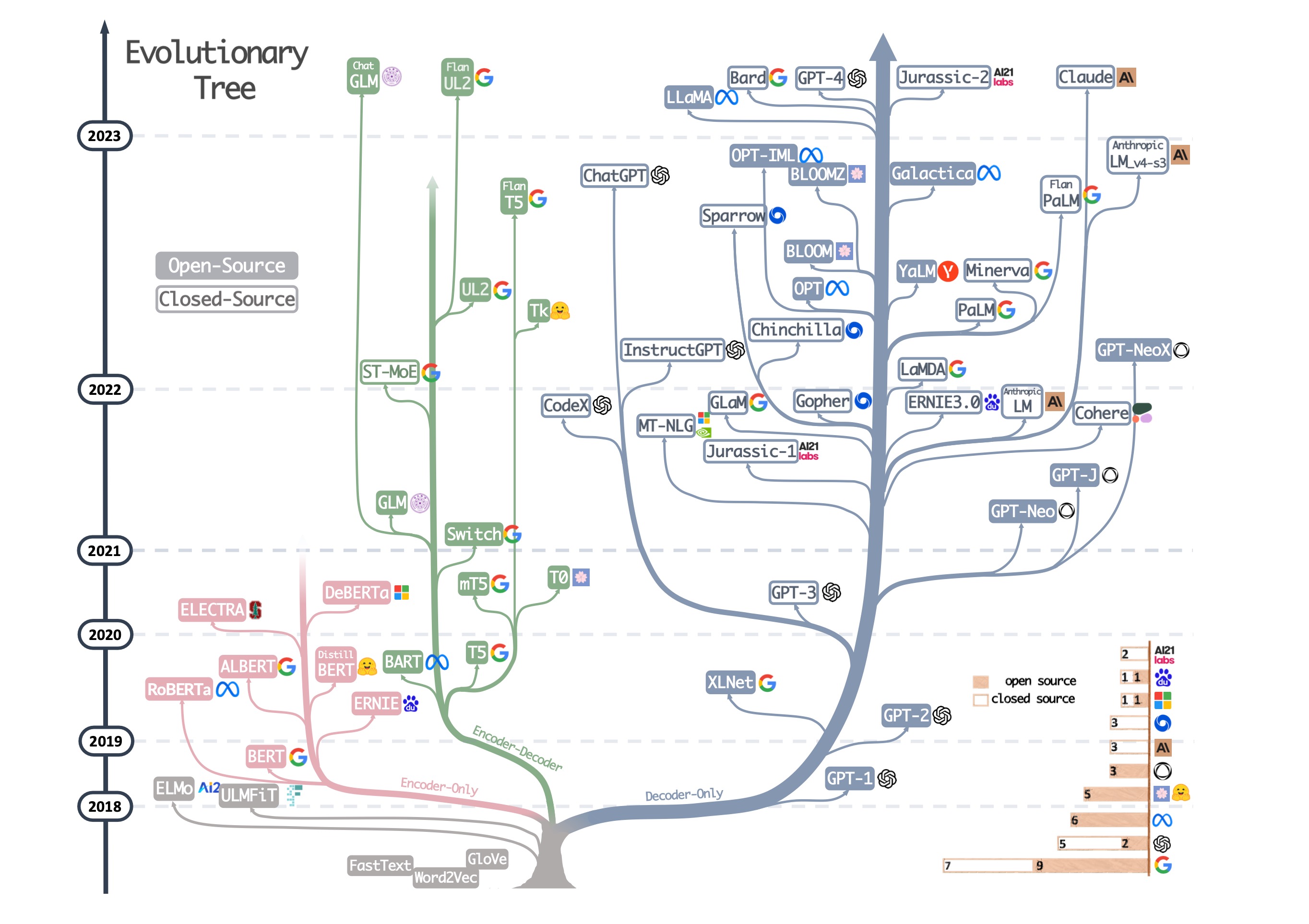
这张图出自去年的一篇综述论文[2],展现了近几年LLM技术的进化树。从图中可以看出,根据LLM的模型架构不同,大体可以分成三个大的技术分支:
- Encoder-Only;
- Encoder-Decoder;
- Decoder-Only (以OpenAI的GPT系列为典型代表)。
实际上,在上面这张图中,除了最左下角“灰色”的那个小分支之外,所有的模型都是基于Transformer架构发展出来的。
Transformer出现于2017年,它的主要组成部分就是一个Encoder和一个Decoder。不管是Encoder,还是Decoder,它们内部又都是由多个包含注意力 (Attention) 模块的网络层组成的。
我们看一下Transformer的模型架构图(出自Transformer原始论文[1]),如下:
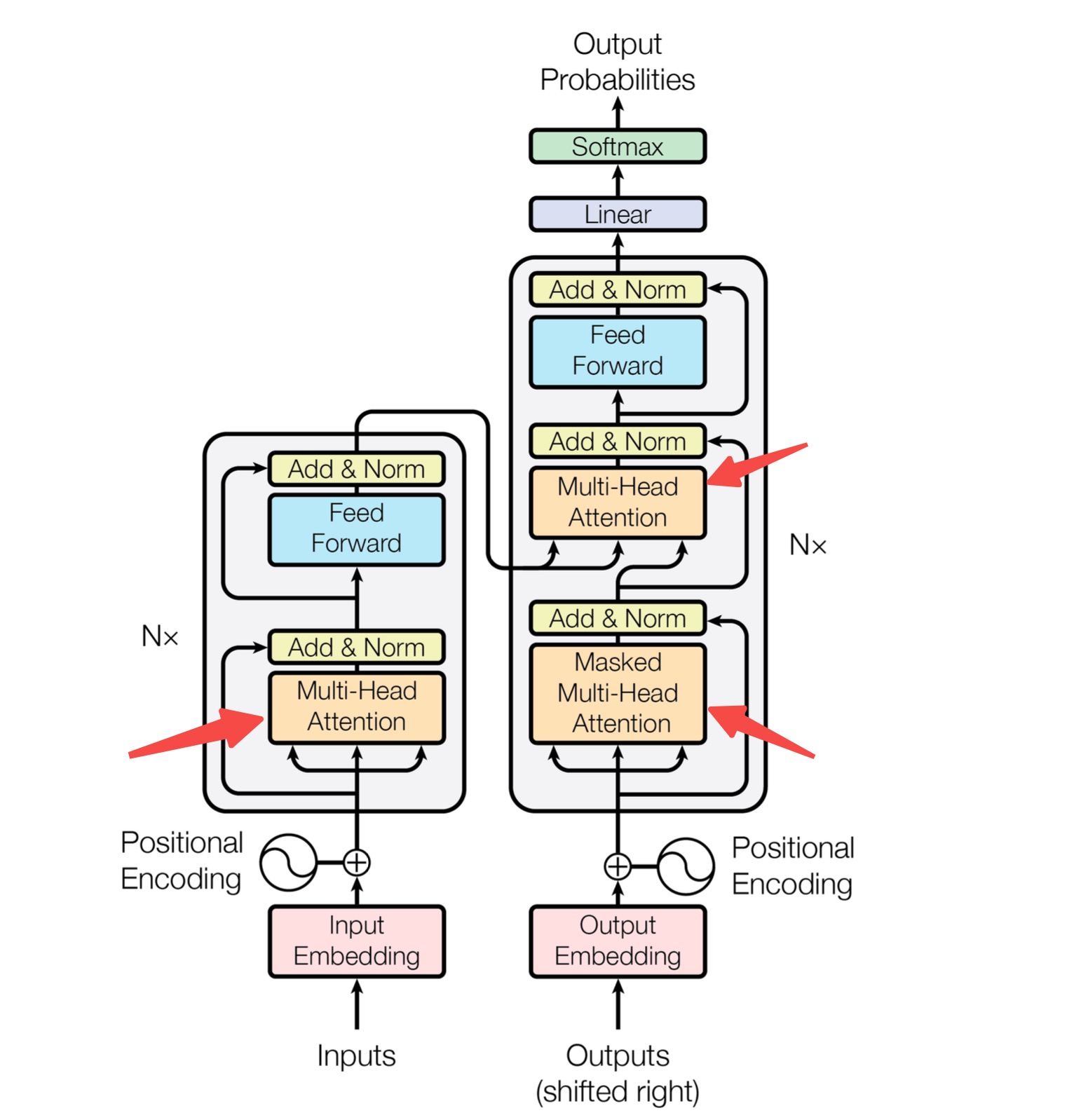
在这个图中,左侧是Encoder,右侧是Decoder。三个红色箭头指向的,便是Transformer架构中最为核心的注意力机制。
Transformer概览
Transformer是一种对序列数据进行建模的机器学习模型。我们先从使用者的角度,来看一下Transformer能做什么,以及怎么使用。
Transformer的一个典型应用是「翻译」任务。假设我们要把英文句子翻译成德文句子,以下是一个例子:
(英文) A little girl is looking at a black dog.
(德文) Ein kleines Mädchen schaut einen schwarzen Hund an.
我们最开始先把Transformer想象成一个黑盒,如下:
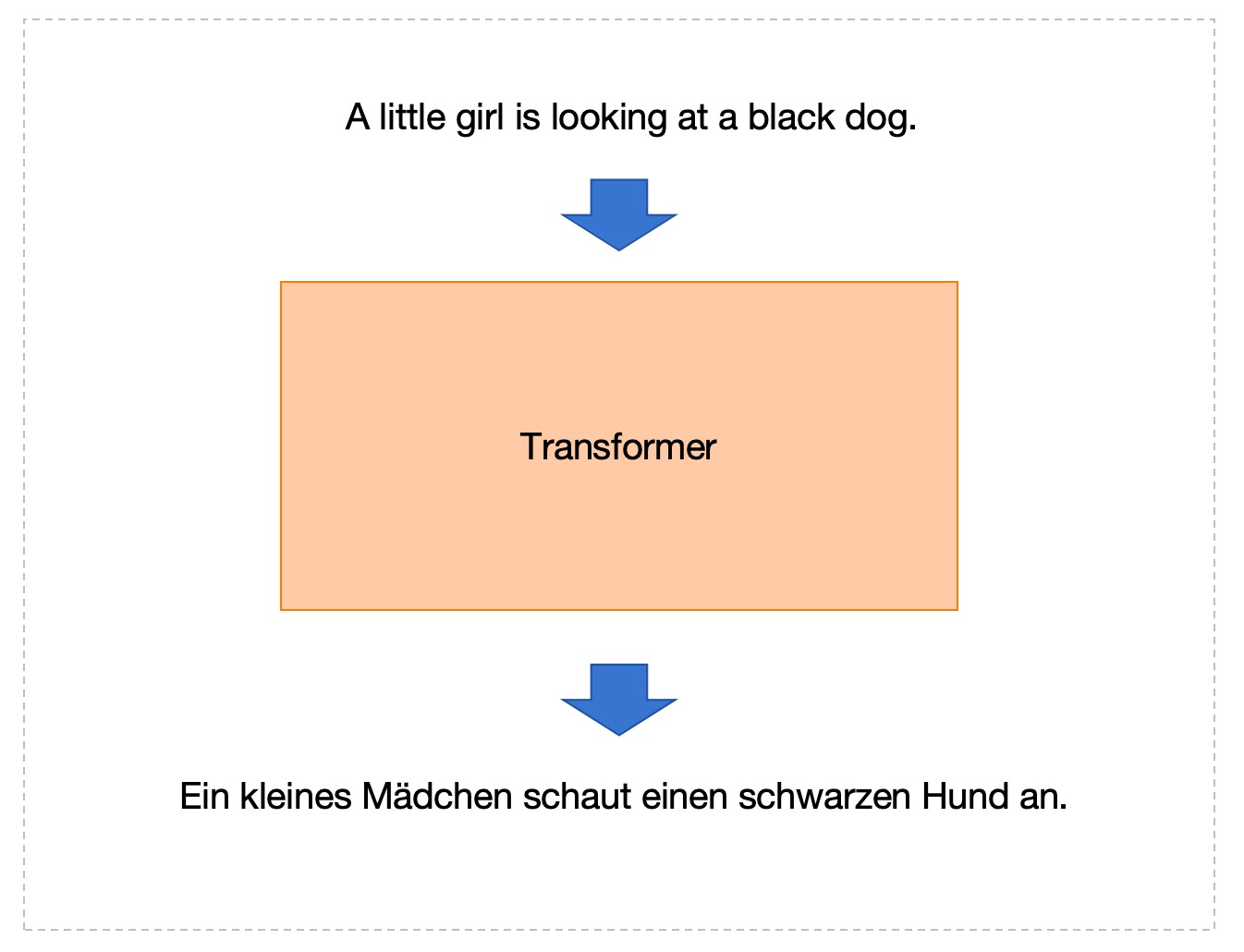
给Transformer输入一个英文句子,它就输出一个德文句子。
但是,具体拆解来看的话,它并不是一下子把整个德文句子输出出来的。它是一个单词一个单词地生成的。如下图:
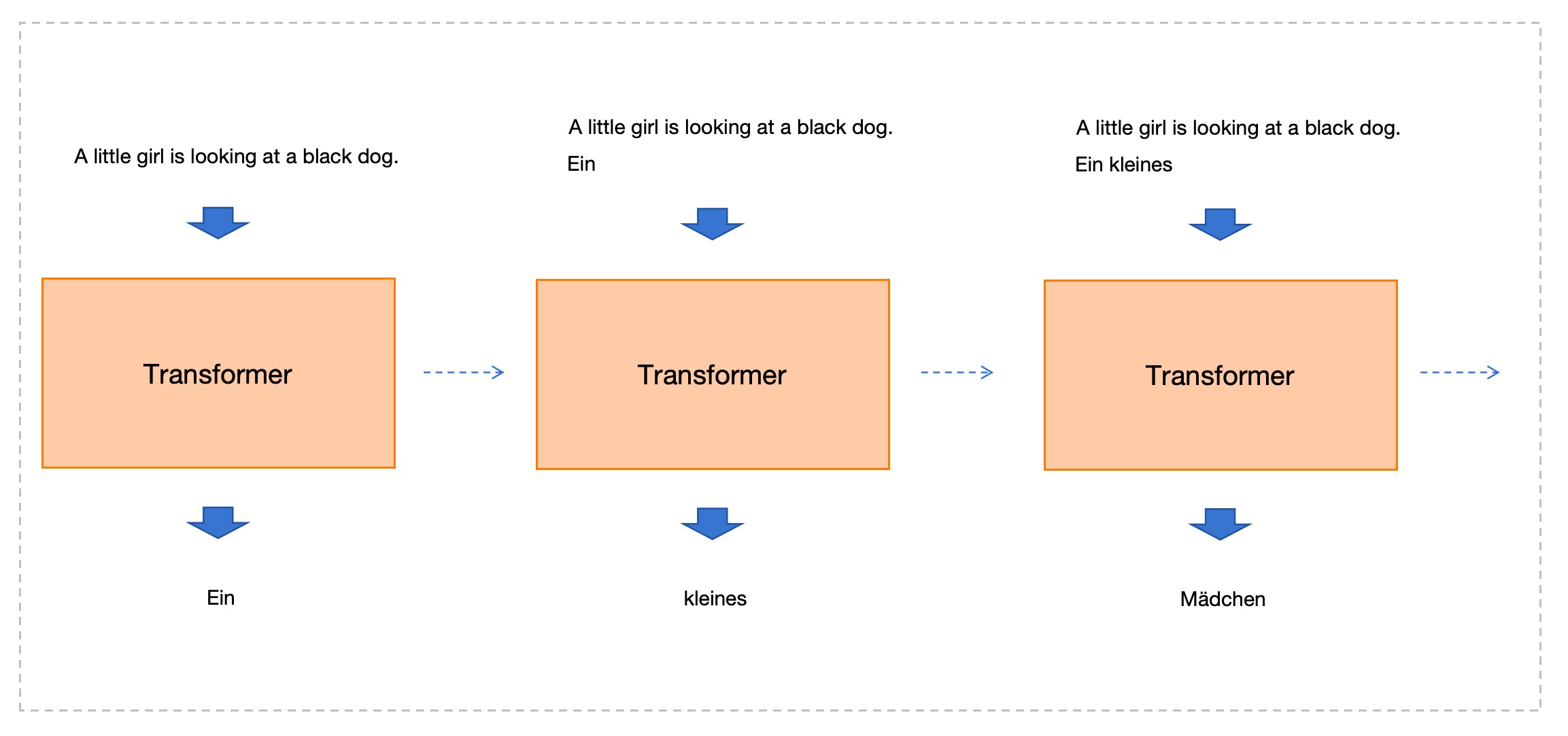
上图展示了前3个德文单词的生成过程,从左到右的虚线箭头表达了时间顺序:
- 第1步:以原始英文句子作为输入,生成第1个单词「Ein」。
- 第2步:以原始英文句子+已经生成的单词「Ein」作为输入,生成第2个单词「kleines」。
- 第3步:以原始英文句子+已经生成的2个单词「Ein kleines」作为输入,生成第3个单词「Mädchen」。
- 依此类推,直至生成完整个德文句子。
当然,更准确的说法是,Transformer每次生成的是一个token。在实际场景中,token未必和单词一一对应。但我们可以先忽略掉这个细节。
这种每次生成下一个单词的工作方式,在Transformer的论文[1]中被称为是「自回归」 (auto-regressive) 的。不管是对于Transformer还是LLM来说,这都是至关重要的一个特性。之所以按照这种方式工作,其实也好理解:
- 参考前面已经生成的单词,来预测下一个单词,有助于形成一个合适的完整句子。人类做翻译的时候也是类似的过程。
- 输出的句子,它所包含的单词数量是预先未知的,需要在「步步为营」的生成过程中动态地确定句子长度。
- 从模型实现的角度,它需要在字典 (dictionary) 规定的有限空间内进行预测。在前面的英文翻译德文的例子中,它需要在由所有德文单词组成的字典中,找到一个合适的单词进行输出。
细看Transformer
在前面一节,我们从外部(也就是使用者)的角度,粗看了一下Transformer的工作方式。现在,我们进入Transformer的内部,分模块来细看一下它的工作过程。
先回顾一下前面的Transformer的模型架构图:
这个图侧重结构,不太能传达出整个工作过程的信息;而且也暴露了太多的技术细节,不利于初学者理解。我们把它重新绘制一下,且只突出当前关注的部分,得到一个新的Transformer模块图:
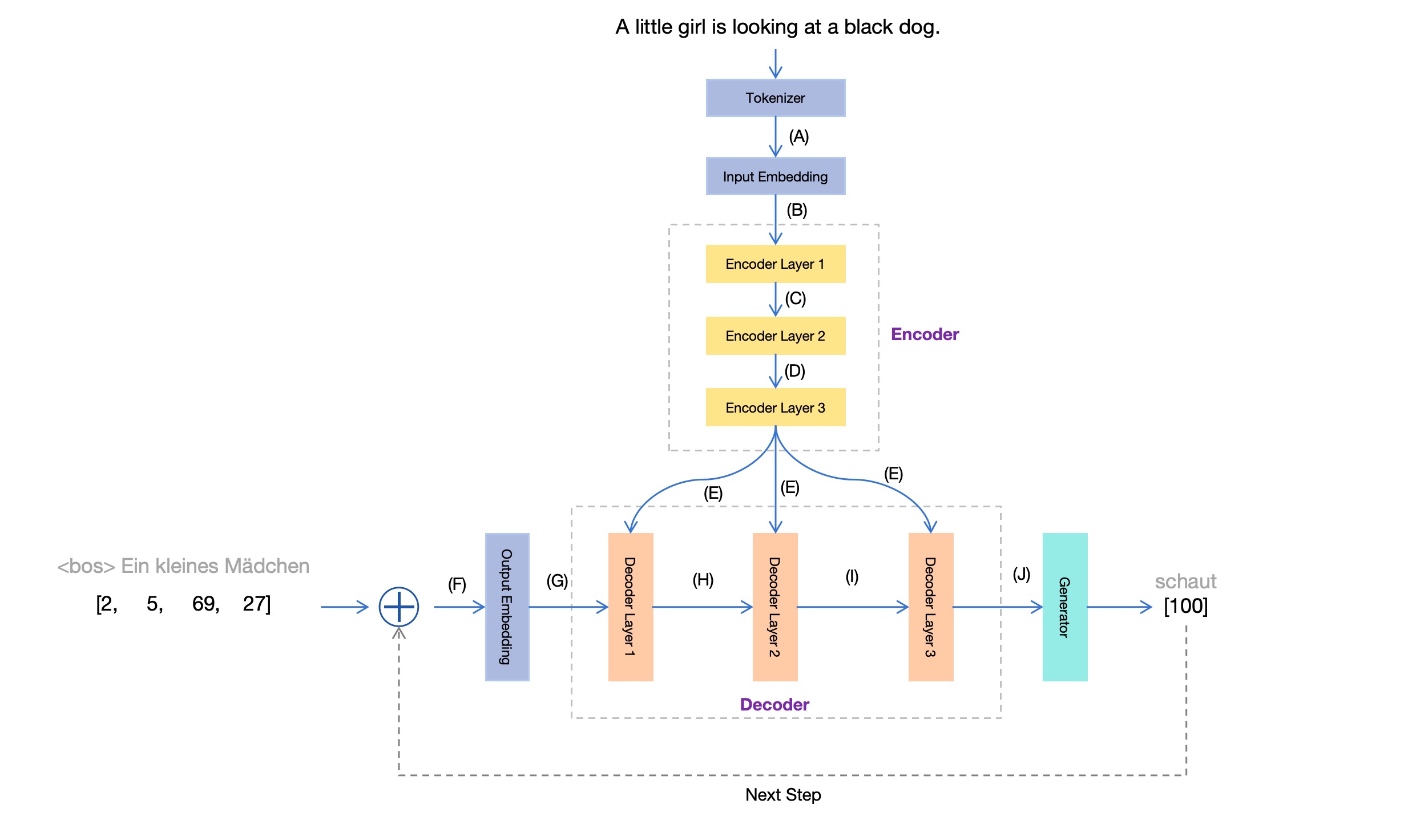
现在,结合前面英文翻译德文的例子,我们把这个图的各个局部解释一下。
Tokenizer
不管是句子还是单词,计算机都没法直接处理。计算机只能处理数字。因此,输入的文本在送进Transformer模型之前,会先经过一个Tokenizer,把文本转换成模型能够处理的数字。
具体来说,Tokenizer做三件事:
(1)分词。也就是把输入句子分割成若干token。我们前面提到,在实际场景中,token未必和单词一一对应。不过为了例子展示简单,我们把一个单词作为一个token。
A little girl is looking at a black dog.
这个英文句子,分词之后,得到9个单词和一个英文句点。总共是10个token,如下:
['A', 'little', 'girl', 'is', 'looking', 'at', 'a', 'black', 'dog', '.']
(2)数字化。把每个token转成一个数字。这一步转换需要依赖一个字典。在实际应用中,一个字典由所有可能的token组成(所有英文单词再加上一些特殊token,通常有几万个),并且对每个token进行索引编号。英文字典类似下面的样子:
[('<unk>', 0), ('<pad>', 1), ('<bos>', 2), ('<eos>', 3), ('a', 4), ('.', 5), ('A', 6), ('in', 7), ('the', 8), ('on', 9), ('is', 10), ('and', 11), ('man', 12), ('of', 13), ('with', 14), (',', 15), ('woman', 16), ('are', 17), ('to', 18), ...]
根据这个字典,原始输入句子变换为:
[6, 61, 33, 10, 56, 20, 4, 26, 34, 5]
(3)拼接特殊token。
在输入句子前面,加上<bos>(在字典中索引为2),标识序列的起始;在结尾加上<eos>(在字典中索引为3),标识序列的结束。变换后输入序列成为一个长度为12的数字序列:
[2, 6, 61, 33, 10, 56, 20, 4, 26, 34, 5, 3]
也就是说,在前面的Transformer模块图的位置 (A) ,我们得到的就是这个数字序列。
Input Embedding
虽然前面已经把文本token转换成了数字,但机器学习中通常会使用多维向量来表示数据。Transformer默认使用512维的内部表示。因此,前面长度为12的数字序列,经过了Input Embedding这个模块的处理之后,就转换成了12个512维的向量。类似下面的形式:
[
[-1.7241e-01, 4.1798e-01, -3.8916e-01, ..., -8.0279e-01],
[ 8.9571e-03, 6.5723e-01, -3.1734e-01, ..., -5.2142e-01],
[ 3.4392e-01, 2.8687e-01, 4.4915e-01, ..., -5.1037e-01],
...,
[-1.6729e-01, -2.8000e-01, 1.3078e-01, ..., -4.3512e-01]
]
以上这些数据共有12行512列。也就是说,每一行是一个512维向量,对应输入序列中的一个token。
在前面的Transformer模块图中,位置 (B) 处,我们得到的就是这12个以512维向量表示的token。
Encoder
从Transformer整体来看,Encoder负责将输入序列(通常是自然语言的)变换成一个「最佳的」内部表示;而Decoder则负责将这个「内部表示」变换成最终想要的目标序列(通常也是自然语言的)。现在,我们先来看一下Encoder,它其实是由多个网络层组成的。
输入序列进入Encoder之后,会经过多个Encoder Layer。每经过一层,相当于输入序列中的每个token进行了一次向量变换(非线性的),也就离那个「最佳的」内部表示又接近了一步。但是,每次变换都不改变向量的维度数量。因此,在前面的Transformer模块图中,位置 (C) ,位置 (D) ,位置 (E) ,这些地方得到的仍然是12个512维向量。
每个Encoder Layer到底做了什么呢?这里面关键的一个机制是自注意力 (self-attention)。这也是Transformer成功的关键因素之一。
为什么需要自注意力呢?Transformer的作者之一Jakob Uszkoreit,曾经在他的一篇blog中举了一个非常典型的例子[3]:
(1) The animal didn’t cross the street because it was too tired.
(那只动物没有过马路,因为它太累了。)
(2) The animal didn’t cross the street because it was too wide.
(那只动物没有过马路,因为马路太宽了。)
这两个句子只有一词之差(最后一个词不同),但这影响了it具体指代的内容。在第 (1) 个句子中,it指代animal,而在第 (2) 个句子中,it指代street。
从这个例子中,我们可以看出几个小现象:
- 组成句子的不同token之间,是有关系的。
- 这种关系的紧密程度,在不同的token之间并非是等同的。也就是说,针对其中的某个具体的token而言,它与句子中某些token的关系,比另外一些token更加紧密。比如,前面的例子中,it与它所指代的名词(animal或street)关系更为紧密,远远超过it与句子中其他token的关系。
- 这种关系的紧密程度,是受上下文影响的。比如,在前面第 (1) 个句子中,it与animal的关系更为紧密;而在前面第 (2) 个句子中,it则与street的关系更为紧密。
那么,Transformer的自注意力机制是如何来描述这些现象的呢?通过前面的讨论,我们已经了解到,在模型内部,每个token都是用一个多维向量来表示的。向量的值决定了这个token在多维空间中的位置,也决定了它所代表的真实含义。前面这些现象可以概括为:一个token的真实含义,不仅仅取决于它自身,还取决于句子中的其它上下文信息(来自其它token的信息)。而借助向量,就可以用数量关系来描述这些现象了:相当于是说,一个token的向量值,需要从句子上下文中的其他token中「吸收」信息,在数学上可以表达为所有token的向量值的加权平均。这些权重值,我们可以称之为注意力权重 (attention weights)。
在Jakob Uszkoreit的blog中[3],token之间的注意力权重,有一个可视化的图:
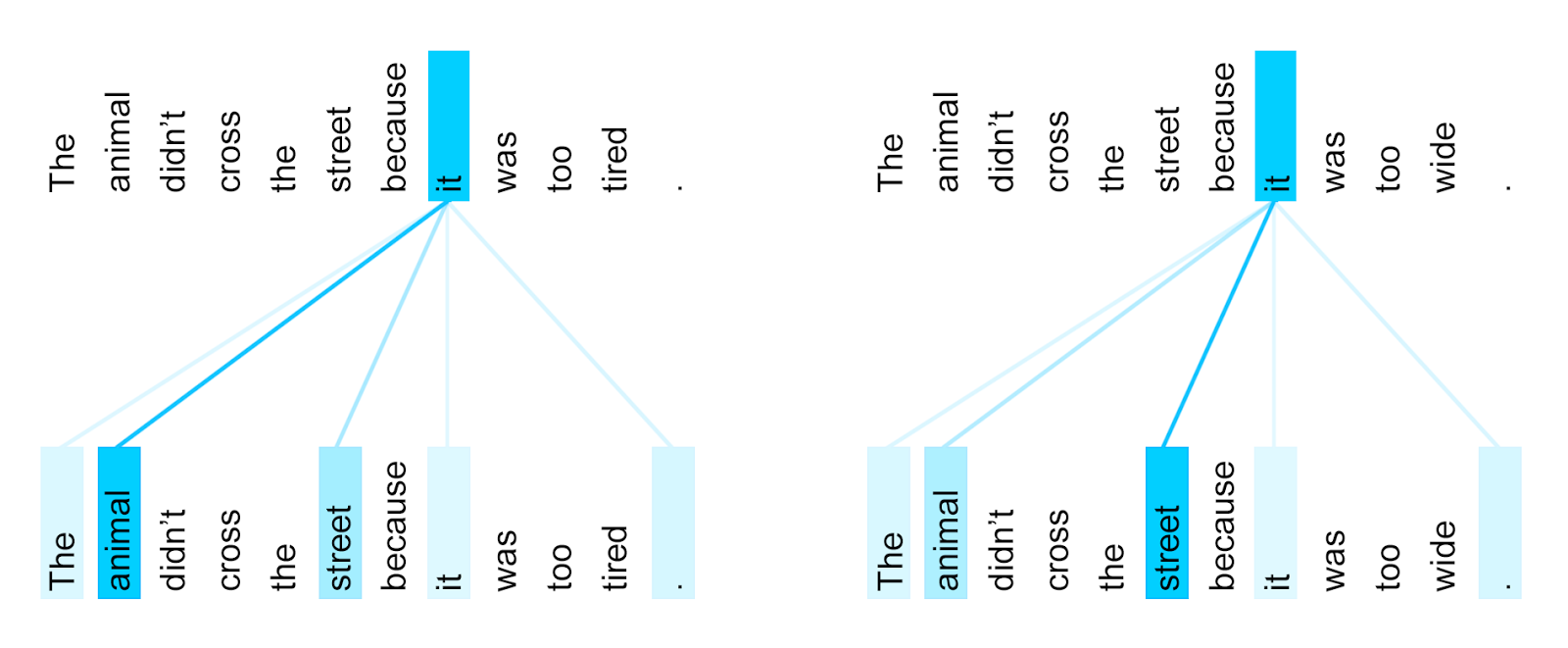
这个图描述了,在一个训练好的Transformer中,it这个token与其他token之间的注意力权重。蓝色的深浅表达了权重的相对大小。
现在结合本章节开始的Transformer模块图,我们对自注意力机制做一个小结。在Encoder中,每经过一层Encoder Layer,一个token都会「参考」上一层的所有token,并根据对它们注意力权重的不同,决定「携带」它们中多少量的信息进来。对于这一过程,一个最简化的说法可以表达为:一个token会注意到 (attend to)所有其他token。
Decoder及其它
我们再回顾一下Transformer模块图。图的下半部分描述了「生成」的过程。我们在上一章节已经讨论了自回归的生成过程,这里我们尽量描述更多细节。
首先,Output Embedding模块与前面的Inpput Embedding类似,都是把token转换成向量。但是一定要注意,Output Embedding模块输入的token,其实是来自最终生成的token。那么,在最开始模型还没有生成任何token的时候,这里输入什么呢?答案是:标识序列起始状态的特殊token,也就是<bos>,作为第一个输入的token。
一旦有了token输入,整个生成过程就可以执行起来了。图中右下方的Generator每次生成一个新的token,再把这个新生成的token当做输入,并以此为条件继续生成token。在Transformer模块图中,图的下半部分展示了生成过程中的一个时刻:根据上一步已经生成的序列“Ein kleines Mädchen”,正在生成下一个token:「schaut」。图中的数字[2, 5, 69, 27]
以及[100],表示相应token在德文字典中的索引编号。
我们讨论了Output Embedding的输入,现在来看一下它的输出。与Inpput Embedding一样,它的输出也是向量(默认512维)。也就是到了图中 (G) 的位置。
后面经过三个Decoder Layer,每个Decoder Layer中又包含两个注意力机制:
- 一个自注意力 (self-attention);
- 一个交叉注意力 (corss-attention)
这里的自注意力,是用来描述生成的序列的(德文);而前面Encoder中的自注意力,是用来描述输入序列的(英文)。这中间有个非常关键的区别:对于Decoder这里的自注意力来说,生成的过程需要遵循因果关系。也就是说,生成下一个token的时候,它必须只能注意到 (attend to) 之前已经生成的token;所以,对于已经生成的序列来说,Decoder Layer对这个序列进行处理的时候,序列中每个token也都应该保持跟生成时一样的逻辑,即它只能注意到 (attend to) 在它之前的token。
而Encoder中的自注意力却允许序列中的每个token都可以注意到 (attend to) 所有的token(包括在它之前和它之后的)。
Decoder中的自注意力,为了遵循因果关系,在计算上需要构建一个mask矩阵:
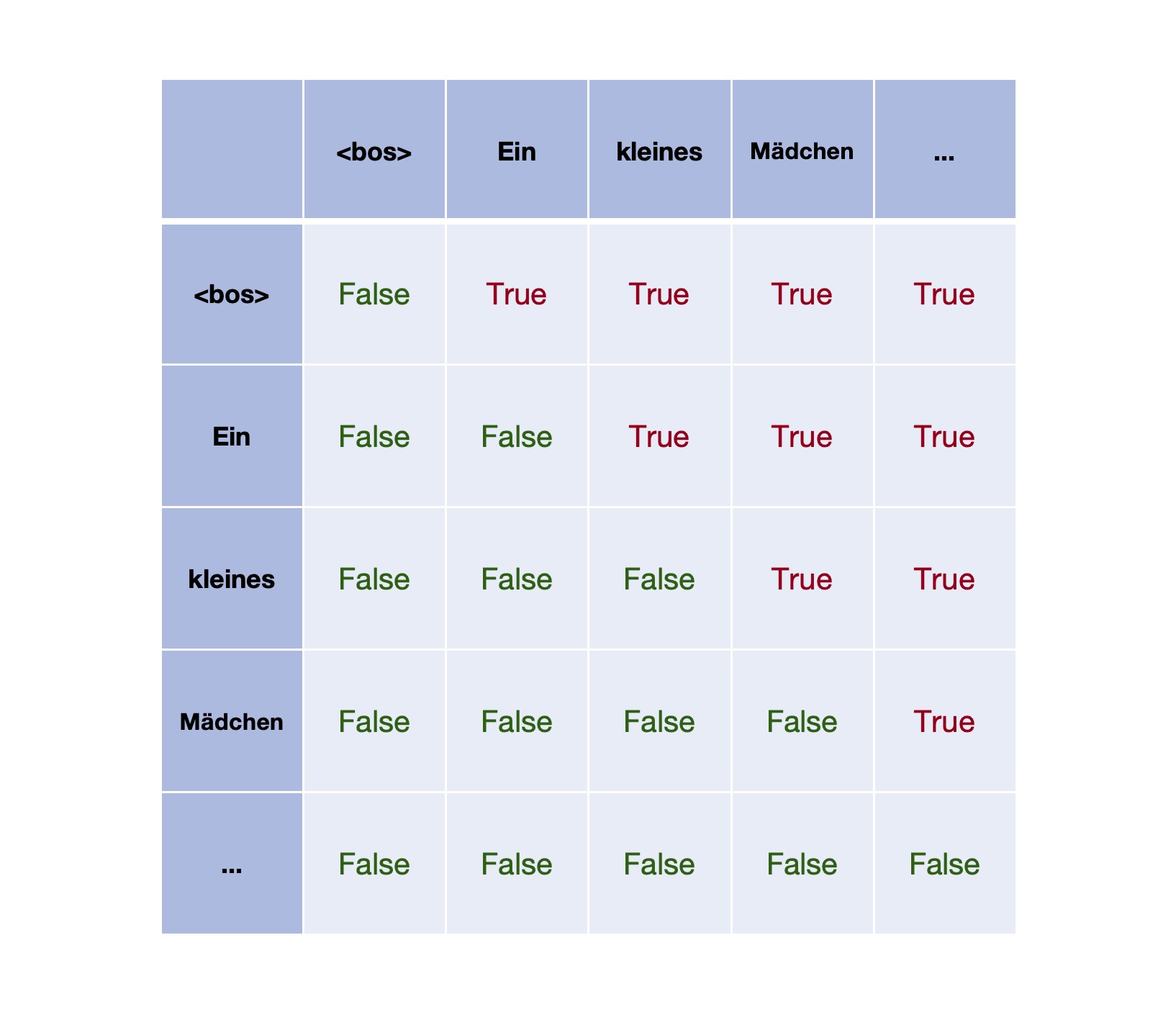
矩阵中为True的地方,表示在生成的序列中,每个token都不能注意到 (attend to) 它后面的token。
交叉注意力与自注意力不同的地方在于:自注意力用于表达同一个序列内部各个token之间的注意力权重,而交叉注意力则用于表达两个不用序列的token之间的注意力权重。Decoder中的交叉注意力,允许在生成下一个token的过程中,以输入序列的内部表示作为参考。也就是参考了图中位置 (E) 处的向量值。
最后,我们把整个Encoding和Decoding的过程放在一起,总结一下:
- 对输入序列进行Encoding,每经过一层Encoder Layer,都执行一次自注意力的过程。每个token都从所有其他token「获取」信息。经过最后一层Encoder Layer之后,每个token得到了一个「最佳」的内部表示。
- 通过Decoding过程进行生成,每经过一层Decoder Layer,都执行一次自注意力和一次交叉注意力的过程。
- 在自注意力执行过程中,生成序列中的每个token只从它前面的token「获取」信息。
- 在交叉注意力执行过程中,生成序列中的每个token都从Encoding结束后得到的内部表示中的所有其他token「获取」信息。
这一过程,可以由以下动图来形象地表达(出自blog[3]):

关于动图的说明:这个动图借助一个例子,可视化地展示了Transformer两个阶段的处理过程:先是Encoding,后是Decoding。图中每个圆点表示一个向量,也就是某个token在Encoder或Decoder某一层的内部表示。图中的运动弧线,表示沿着自注意力或交叉注意力指导的方向上,token之间信息的流动方向。在前半部分的Encoding过程中,自上而下,是经历了三个Encoder Layer;而在后半部分的Decoding过程中,则是自下而上,经历了三个Decoder Layer。
小结
以上本文的所有描述,基本上都是基于一个已经训练好的Transformer来讨论的。在这个训练好的Transformer中,注意力权重参数已经有了恰当的值。而这些注意力权重参数的得来,则依赖Transformer的训练过程。
除了训练过程,还有一些重要的细节,由于篇幅原因,本文也同样没有涉及到。比如,多头注意力机制 (Multi-Head Attention) ,位置编码 (Positional Encoding) ,用于计算注意力权重的q、k、v,等等。如果想把这些讨论清楚,还需要引入很多额外的其他信息,我们后面有机会再说。
现在让我们简单总结一下。
我们大体上可以说,LLM的发展,正是沿着Transformer所奠定的技术基础前进的。尤其是其中Decoder-Only的架构,已经成为发展最壮大、也最成功的技术分支。而在这些技术的发展过程中,注意力机制则起到了至关重要的作用:
- Transformer的注意力机制,能够比以往算法更好地从输入序列中捕获长距离 (long-distance) 的依赖关系。这使得模型能够学习到序列中更为复杂的模式。
- Transformer的注意力机制,在工程实现上允许并行计算,消除了传统RNN技术的串行依赖。这使得模型能够在更大的数据集上训练。
除了以上因素,基于Decoder-Only的模型架构,促进了自回归方法 (auto-regressive) 的广泛应用。这种方法,使得模型可以从大量未标注的序列数据中进行学习,从而摆脱了传统的监督学习对人工标注数据的依赖。
所有这些因素加起来,使得研究人员能够把互联网级的数据灌进模型,并能使用有限的算力在有限的时间内获得训练结果。结合Decoding的过程,LLM彻底把Predict Next Token发扬光大了。基于此,OpenAI提出了影响深远的Scaling law[4],并发展成为某种类似信仰的东西。
(正文完)
参考文献:
- [1] Ashish Vaswani, et al. 2017. Attention Is All You Need.
- [2] Jingfeng Yang, et al. 2023. Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond.
- [3] Jakob Uszkoreit. 2017. Transformer: A Novel Neural Network Architecture for Language Understanding.
- [4] Jared Kaplan, et al. 2020. Scaling Laws for Neural Language Models.
- [5] Language Translation with nn.Transformer and torchtext.
- [6] Sebastian Raschka. 2024. Understanding and Coding Self-Attention, Multi-Head Attention, Cross-Attention, and Causal-Attention in LLMs.
- [7] Arjun Sarkar. 2022. All you need to know about ‘Attention’ and ‘Transformers’ — In-depth Understanding.
- [8] Jay Alammar. 2020. The Illustrated Transformer.
- [9] Austin Huang, et al. 2022. The Annotated Transformer.
其它精选文章:
- 对于2024年初的大模型,我们期待什么?
- 知识的三个层次
- 看得见的机器学习:零基础看懂神经网络
- 内卷、汉明问题与认知迭代
- 在技术和业务中保持平衡
- 分布式领域最重要的一篇论文,到底讲了什么?
- 漫谈分布式系统、拜占庭将军问题与区块链
- 三个字节的历险
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-transformer-attention.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。
