分布式领域最重要的一篇论文,到底讲了什么?
2021-04-11
正在阅读本文的读者们,可能之前已经读过了我写的有关线性一致性、顺序一致性以及因果一致性的分析文章。这些一致性模型的关键在于,它们定义了一个系统在分布式环境下对于读写操作的某种排序规则。
没错,分布式系统内的事件排序,涉及到最深层的本质问题。图灵奖得主Lamport在1978年发表的经典论文,《Time, Clocks, and the Ordering of Events in a Distributed System》[1],正是对这些本质问题的一个系统化的阐述。
今天,我们就来解析一下这篇经典论文,看看它到底讲了什么,以及相关的思路是怎样的。
为什么这篇论文如此重要?
先讲一个小故事。
两位研究人员Paul Johnson和Bob Thomas在1975年发表了一篇题为《Maintenance of duplicate databases》的论文[2],提出了一种基于消息时间戳的分布式算法。Lamport看到这篇论文后,很快就发现了算法存在的一些问题。他向论文作者指出了错误并帮助修正了算法。
在Lamport的自述中,他之所以能够指出算法的错误,是因为他对相对论有比较深入的理解[3]。他一眼就看透了Paul Johnson和Bob Thomas的算法的本质,用他自己的话来讲:
I realized that the essence of Johnson and Thomas’s algorithm was the use of timestamps to provide a total ordering of events that was consistent with the causal order.
(译文:我意识到,Johnson和Thomas提出的算法的本质在于使用时间戳来提供事件的一种全局排序,而这种排序是和因果顺序保持一致的。)
在认识到这个「本质」之后,Lamport写成了《Time, Clocks, and the Ordering of Events in a Distributed System》[1]这篇论文,后来成为了分布式领域的经典论文,也是Lamport被引用次数最多的论文。
要理解这件事相关的描述,必须对事件偏序、因果性、相对论等概念有基本的了解。但这不是我们目前的重点(相关讨论会在下一章节开始)。现在你只要记住,这篇论文之所以经典,是因为它揭示了分布式系统的某些深层本质,深深地影响了人们对于分布式系统的思考方式。
当然,这篇论文除了理论意义和历史价值之外,它与业界一些重要的分布式系统实践也都有紧密的联系。比如,在大规模的分布式环境下产生单调递增的时间戳,是个很难的问题,而谷歌的全球级分布式数据库Spanner就解决了这个问题,甚至能够在跨越遍布全球的多个数据中心之间高效地产生单调递增的时间戳。做到这一点,靠的是一种称为TrueTime的机制,而这种机制的理论基础就是Lamport这篇论文中的物理时钟算法(两者之间有千丝万缕的联系)。再比如,这篇论文中定义的「Happened Before」关系,不仅在分布式系统设计中成为考虑不同事件之间关系的基础,而且在多线程编程模型中也是重要的概念。另外,还有让很多人忽视的一点是,利用分布式状态机来实现数据复制的通用方法(State Machine Replication,简称SMR),其实也是这篇论文首创的。
总之,如果在整个分布式的技术领域中,你只有精力阅读一篇论文,那一定要选这一篇了。只有理解了这篇论文中揭示的这些涉及时间、时钟和排序的概念,我们才能真正在面对分布式系统的设计问题时游刃有余。
分布式系统中的事件和偏序关系
从论文的题目看,《Time, Clocks, and the Ordering of Events in a Distributed System》,论文主要是讲三个基础概念:时间(Time)、时钟(Clock)、事件排序(Ordering of Events)。它们之间的关系大概是:
- 一个分布式系统由很多进程组成,而一个进程可以看成是一个事件序列。所以说,事件是一个抽象概念,根据应用场景不同,程序运行发生的任何事情都可以表示成事件。比如,根据论文中举的例子,一个子程序开始执行,可以看成是一个事件;一条机器指令的执行,也可以看成一个事件。
- 时间是一个物理学上的概念。每个事件发生的时候,都对应时间的某个数值。而根据相对论,时空是不可分割的,时间必须与空间一起讨论才有意义。
- 时钟分两种,一种是物理时钟(Physical Clock),或者叫实时时钟(Real Clock);另一种是逻辑时钟(Logical Clock)。物理时钟是对时间的一种度量;现实中的物理时钟肯定是有误差的。而逻辑时钟是跟物理时间无关的,用于对每一个发生的事件指派一个单调递增的数值,是系统执行节拍的一种内部表示。
- 两个不同的事件,可能具有先后关系,它们之间是能够排序的;也可能两个事件之间根本无法按照先后关系来排序。也就是说,事件排序是偏序的(Partial Ordering)。
论文实际上是从事件开始讲起的。进程的执行被看成是一连串事件的持续发生。随后,事件之间的排序问题就很自然地被提出来了。联系我们日常的系统设计实践,我们就经常需要对分布式系统中的不同事件的发生次序进行判定。比如我们在之前的文章中讨论的各种一致性模型,主要就是给予不同读写操作(事件)一个合理的排序;再比如为了实现串行化(Serializability)的事务隔离性,也需要判定各个事务操作之间的排序。这些排序问题,可能涉及到在一个进程内部的多个事件之间排序,这通常还是比较容易的;同时还可能涉及到对发生在不同进程(位于不同节点上)上的事件进行排序,这通常就没有那么直观了。
如果我们说事件a在事件b之前发生,直觉上的含义大概是:事件a发生的时间比事件b发生的时间要早。然而,这种判定事件之间次序的方式,是依赖物理时间的。这要求我们必须引入物理时钟才行,而物理时钟不可能百分之百精确。
因此,Lamport在定义事件之间的关系的时候特意避开了物理时间。这就是著名的「Happened Before」关系(用符号“→”来表示)。见下面进程P、Q和R的消息时空图(注意图中自下而上时间递增):
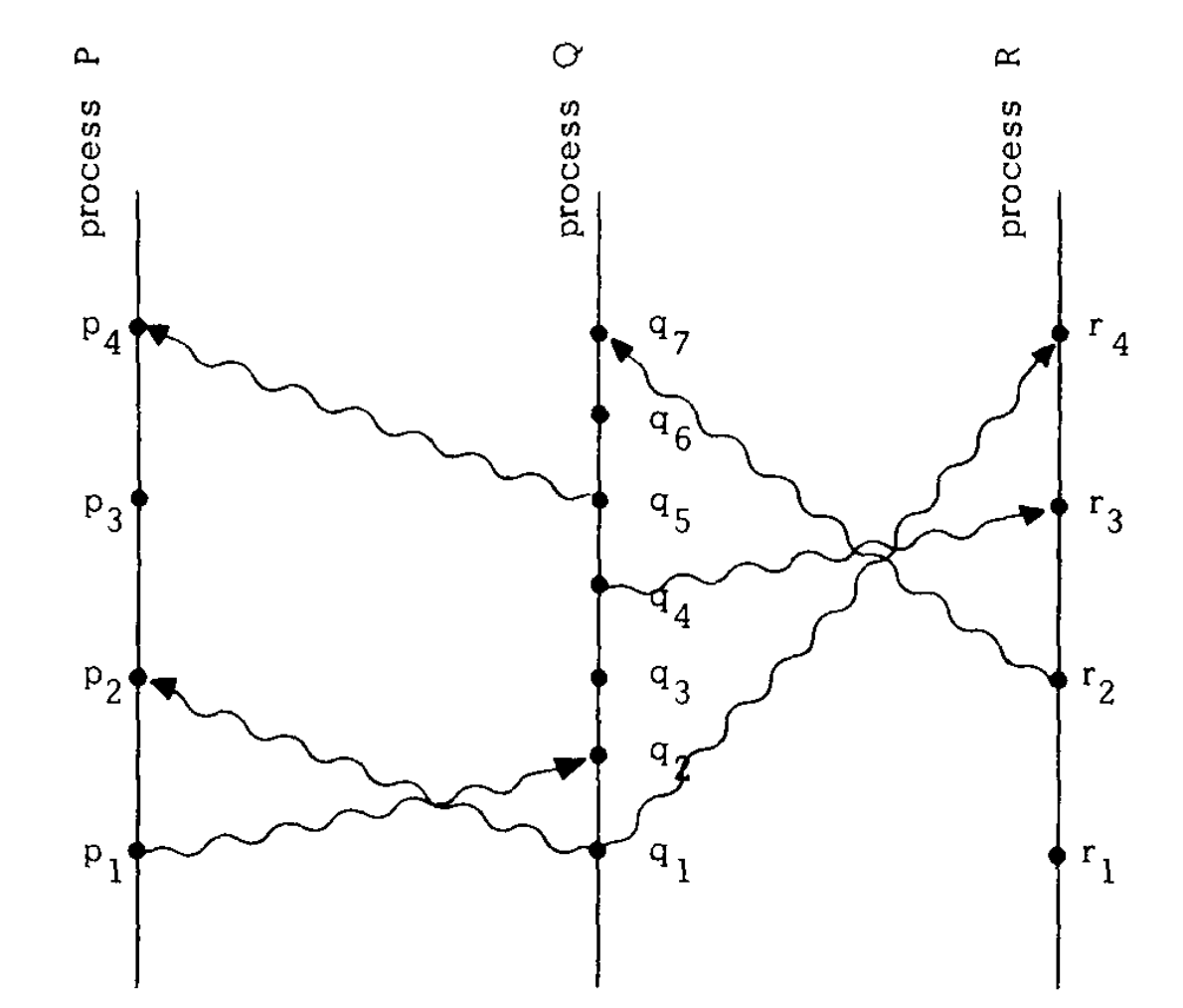
结合上图我们举例解释一下「Happened Before」关系:
- 同一进程内部先后发生的两个事件之间,具有「Happened Before」关系。比如,在进程Q内部,q2表示一个消息接收事件,q4表示另一个消息的发送事件,q2排在q4前面执行,所以q2→q4。
- 同一个消息的发送事件和接收事件,具有「Happened Before」关系。比如,p1和q2分别表示同一个消息的发送事件和接收事件,所以p1→q2;同理,q4→r3。
- 「Happened Before」满足传递关系。比如,由p1→q2,q2→q4和q4→r3,可以推出p1→r3。
这种「Happened Before」关系的关键在于,它是一种偏序关系。也就是说,并不是所有事件之间都具有「Happened Before」关系。比如p1和q1两个事件就是无法比较的,q4和r2也是无法比较的。
相信阅读过上一篇文章《条分缕析分布式:因果一致性和相对论时空》的读者,已经发现了这里的「Happened Before」关系定义与因果一致性中的因果顺序定义非常相似。实际上,因果一致性的概念[4]相当于将「Happened Before」关系应用在了读写操作之上。
Lamport在论文中是这样描述与因果性的关系的:
Another way of viewing the definition is to say that a→b means that it is possible for event a to causally affect event b. Two events are concurrent if neither can causally affect the other.
(译文:看待「Happened Before」关系的另一种方式,相当于是说,a→b意味着事件a有可能在因果性上对事件b产生影响。如果两个事件谁也无法影响对方,那么它们就属于并发关系。)
最后要说明的是,「Happened Before」关系,几乎是分布式系统中最基础的一个概念。Lamport的论文后面的其他概念和算法,也都是以这个偏序关系为基础建立起来的。你可能已经注意到,我们在介绍「Happened Before」关系之前,在描述中有几次使用了「先后关系」这个字眼来描述两个事件之间的关系。现在我们知道,「先后关系」是一个非正式的描述,而「Happened Before」才是用于描述两个事件之间关系的最规范的、也是唯一正确的概念。这个概念清晰地表达一种偏序而非全序关系,规定了哪些事件之间不可比较,哪些事件之间具有「Happened Before」关系。随着我们对于分布式系统设计经验的不断丰富,我们会发现这一概念将贯穿于分布式系统设计的任何细节中去。
逻辑时钟
前面我们提到过,Lamport在定义事件之间的「Happened Before」关系时特意避开了物理时间。这也就意味着,对事件的「发生时间」进行度量,只能根据逻辑时钟。
逻辑时钟相当于一个函数,对于每一个发生的事件,它都能给出一个对应的数值(即给这个事件打上了一个时间戳)。用符号来表示的话就是:事件a发生时对应的时钟值(时间戳)是C〈a〉。
为什么要定义逻辑时钟这个概念呢?我们前面讨论过,在分布式系统中我们经常需要对不同的事件进行排序。那么,为了实现这种排序操作,我们很自然地就需要对事件的发生进行一种数值上的度量。我们希望,可以通过比较事件的时间戳数值大小,来判断事件发生的次序(即「Happened Before」关系)。这就好比我们通过看钟表上显示的数值来确定时间的流逝一样。
当然,逻辑时钟在给事件打时间戳的时候,必须要满足一定条件的。这个过程必须能在一定程度上反映出事件之间的「Happened Before」关系。论文这一部分最重要的就是定义了一个时钟条件(Clock Condition),如下:
- 对于任意的事件a和b:如果a→b,那么必须满足C〈a〉 < C〈b〉。
只有满足这个时钟条件的逻辑时钟,才是真正有效的。
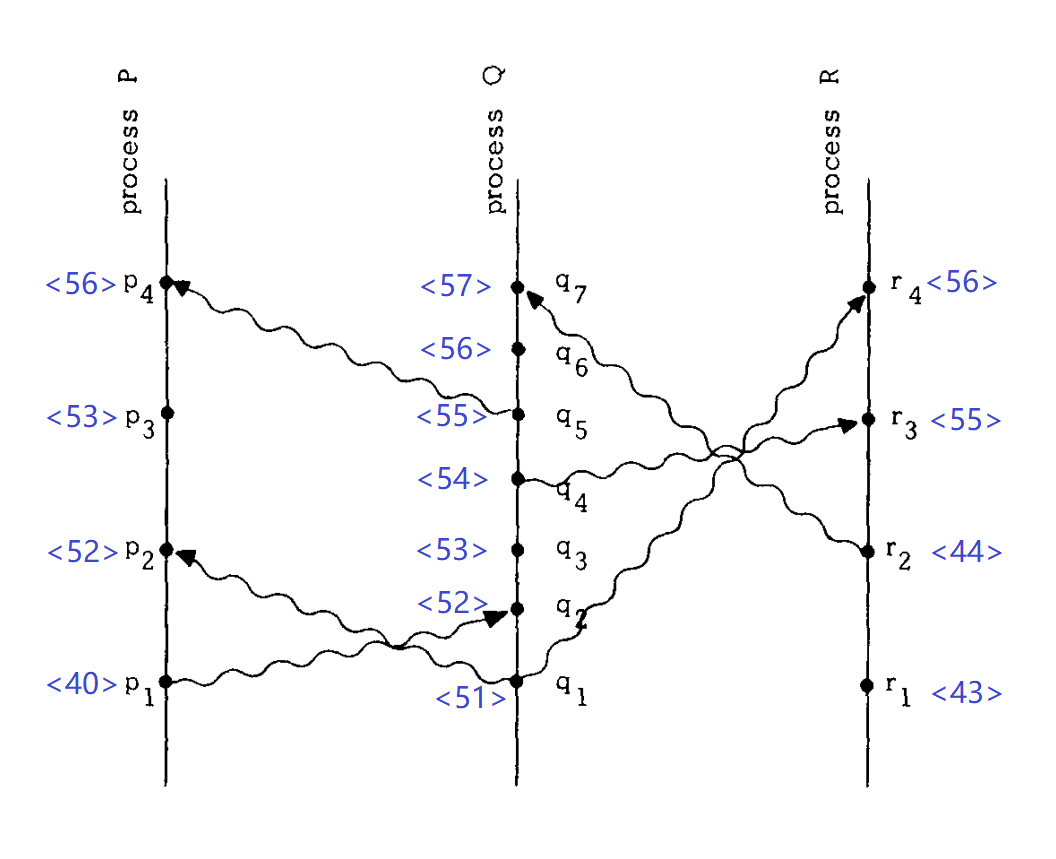
为了更直观地说明逻辑时钟的含义,现在我们重新看一下前面的消息时空图(上图)。我们在图上用蓝色字体在方括号中标注了一些数字,而且在每个消息收发事件旁边都标了一个。这些数字表示某个逻辑时钟给对应的事件打的时间戳。
如果仔细检查的话,会发现图中标注的逻辑时钟是符合前面的时钟条件的。举几个例子:
- 考察进程Q内部的两个事件,q2→q4,而C〈q2〉 = 52 < C〈q4〉 = 54。
- 再考察同一个消息的发送事件和接收事件,p1→q2,而C〈p1〉 = 40 < C〈q2〉 = 52。
现在我们已经直观地看到了一个合理、有效的逻辑时钟是什么样子。至于这个逻辑时钟是怎么实现出来的(比如各个事件的时间戳的具体数值是怎么产生的),论文中给出了一种实现,我们这里就不展开讨论这些细节了。但我们需要尤其注意的是,逻辑时钟的时钟条件,是一个单向的条件,反过来是不成立的。比如:
- 我们有C〈p3〉 = 53 < C〈q4〉 = 54,但不能说明p3→q4成立。也就是说,虽然对任意两个事件来说,它们各自对应的时间戳在数值上都可以比较大小,但据此并不能得到两个事件之间存在「Happened Before」关系。从本质上看,时钟条件的这种单向推导逻辑,是由「Happened Before」关系的偏序特性所决定的。
为什么又需要全局排序?
我们简单回顾一下前一个章节的思路。最开始,我们引入逻辑时钟,是希望可以通过比较事件的时间戳数值大小,来帮助我们判断事件之间的「Happened Before」关系。然而,最后由于时钟条件的单向推导逻辑的限制,我们发现,不能根据两个事件对应的时间戳在数值上的大小来推断出它们之间是否存在「Happened Before」关系。真是一个矛盾的结果!
导致这个矛盾的原因,还是在于「Happened Before」的偏序性。对于不具有「Happened Before」关系的两个事件来说,它们对应的时间戳数值比较大小,是没有意义的。但是,确实可以根据两个时间戳的大小,来为两个事件「指定」一个次序。这个次序是人为指定的,并不是客观上要求的。还是拿前面的消息时空图来举个例子:p3和q4这两个事件,它们之间不存在「Happened Before」关系。但是,我们发现C〈p3〉 = 53,C〈q4〉 = 54,而53 < 54,所以我们人为指定一个次序,即认为p3是在q4之前发生的。实际上,由于这两个事件之间不存在「Happened Before」关系,我们不管是认为p3在q4之前发生,还是认为q4在p3之前发生,都没有大碍。
现在,我们就引入了另外一个问题:如果我们按照逻辑时钟给出的时间戳从小到大把所有事件都排成一个序列,那么就得到了分布式系统中所有事件的全局排序。下面我们把前面进程P、Q和R的消息时空图中的所有事件,按照时间戳进行全局的大排序,会得到:
- p1 => r1 => r2 => q1 => p2 => q2 => p3 => q3 => q4 => q5 => r3 => p4 => q6 => r4 => q7
在这个排序中,所有事件之间的「Happened Before」关系都被保持住了;而本来不存在「Happened Before」关系的事件之间,我们也依据时间戳的大小,通过人为指定的方式得到了一个次序。总之,我们得到了所有事件的一种全局排序,而这种排序是和「Happened Before」关系(即因果顺序)保持一致的。
那么,这样一种全局排序有什么用呢?实际上,这是实现任何分布式系统的一种通用方法。只要我们获得了所有事件的全局排序,那么各种一致性模型对于读写操作所呈现的排序要求,很自然就能得到满足。回想一下我们在之前的文章《条分缕析分布式:浅析强弱一致性》中的分析,线性一致性和顺序一致性所要求的,正是要把所有读写操作(对应这里的事件)重排成一个全局线性有序的序列。
实际上,之所以前面设计出了逻辑时钟,最终目的就是为了得到一种事件全局排序的机制。而更近一步,事件的全局排序结合状态机复制(State Machine Replication)的思想,几乎可以为任何分布式系统的设计提供思路。关于这一点,Lamport曾经写下了如下的句子[3]:
It didn’t take me long to realize that an algorithm for totally ordering events could be used to implement any distributed system. A distributed system can be described as a particular sequential state machine that is implemented with a network of processors. The ability to totally order the input requests leads immediately to an algorithm to implement an arbitrary state machine by a network of processors, and hence to implement any distributed system.
(译文:我很快就意识到,对事件进行全局排序的算法,可以用于实现任何分布式系统。一个分布式系统可以被看作是一个由处理器网络实现的序列状态机。对输入请求进行全局排序的能力一旦具备,我们立即就能推导出使用处理器网络实现任意一个状态机的算法,因此可以用于实现任何分布式系统。)
逻辑时钟的异常行为
我们来看一个小例子。
假设Alice和Bob是一对好朋友,他们住在两个不同的城市。Alice在网络上观看足球比赛,现在她在自己的计算机上发出了一个查询请求(记为请求A),用于查询比赛的比分。假设处理请求的是一个分布式系统,并且采用逻辑时钟来为请求打上时间戳。然后请求A返回了最新的比分。Alice这时发现有了一个新的进球得分,于是她打电话给另一个城市的Bob,告诉他去服务器上查询同一个比赛的比分结果。于是,Bob通过自己的计算机发出了请求B。由于系统采用了逻辑时钟,因此处理请求B的服务器有可能为请求B打上了一个比请求A更小的时间戳。对于逻辑时钟来说,这种行为属于正常情况。这是因为,一方面,逻辑时钟的定义特意避开了物理时间,系统产生的时间戳与请求的真实时间先后并没有直接关系;另一方面,在系统内部,请求A与请求B这两个事件之间,并不存在「Happened Before」关系,因此并不保证请求B的时间戳一定比请求A的时间戳更大。结果,请求B由于被打上了一个更小的时间戳,有可能在全局排序中排到了请求A的前面,所以Bob并没有查询到最新的球赛比分(也许只查询到了旧版本的数据,这里的行为取决于一些额外的数据库实现机制),因此与Alice看到的结果产生了不一致。
这种情况,Lamport在论文中称为异常行为(anomalous behavior)。可见,只是使用逻辑时钟,不能避免这种异常行为;而一个好的分布式系统设计,应该消除这种异常行为。
我们看到,请求A和请求B实际上应该是存在因果关系的,因为是Alice在发出请求A之后打电话告诉了Bob,之后请求B才被发出来。但这个因果性是通过系统外部的联系方式(打电话)来体现的,系统内部并不知晓,所以没有在请求A和请求B之间构建起「Happened Before」关系。
Lamport的论文行文到这里,出现了一个不小的跳跃。我们可以这样思考:出现异常行为的原因在于系统不知道Alice给Bob打了电话,所以才认为给请求B打一个更小的时间戳是合理的。显然,让系统知道Alice给Bob打电话这个事实,是不太可能的。但我们注意到,如果考虑一下请求A和B发出的时间先后,这个问题可能就有办法解决了。在这个例子中,Alice给Bob打电话起码要花上几分钟,也就是说请求B发生的时间比请求A要晚几分钟。对于晚了这么久的请求B,系统仍然给打了一个更小的时间戳,根本原因在于逻辑时钟是没有和真实的物理时间绑定的。因此,我们可以得到结论,仅仅使用逻辑时钟是不够的,需要使用物理时钟才行。又因为我们需要一个分布式的系统,所以物理时钟不能只有一个实例,而是最好每个进程都有自己对应的本地物理时钟。否则,运行物理时钟的进程就会成为单点,也就失去了分布式的意义。
那么,物理时钟需要多精确,才能杜绝这种异常行为?显然这些物理时钟需要满足一定的条件。从直觉上看,Alice给Bob打电话需要分钟级的时间,对于计算机系统来说,这个物理时钟大概不需要那么精确。但是,如果Alice通知Bob的方式,不是打电话呢?如果是通过更快的一种方式呢?显然,Alice通知Bob的速度越快,系统对于物理时钟的要求也越高,才不至于出现异常行为。那么,Alice通知Bob的速度,最快可以达到什么程度呢?答案是:光速。因为在这个世界上信息传递的最快速度就是光速了。现在我们假设,如果系统的物理时钟满足这样一个最苛刻的条件:即使Alice通知Bob的速度达到光速,系统也总是能保证对请求B打上的时间戳要大于请求A的时间戳,那么,就能保证永远不出现前面的异常行为。这样的一个时钟条件,在Lamport的论文中被称为Strong Clock Condition。具体描述如下:
- 对于任意的事件a和b:如果a➜b,那么必须满足C〈a〉 < C〈b〉。
这看起来跟前面逻辑时钟的时钟条件差不多,实则不然。这里的“➜”和“→”的含义截然不同:
- “→”表示「Happened Before」关系;
- 而“➜”表示由相对论定义的事件偏序关系。
具体含义我们下一小节再讨论。
时空本身定义了一种偏序
如果不了解一点相对论的时空概念,那么就很难理解前面的Strong Clock Condition是什么含义。那接下来我们就简单介绍一下相关的概念。
我们生活的空间是三维空间,但是为了更好地用图象来表示,我们先看二维的情况。现在假定我们的世界是一个二维平面,如下图:
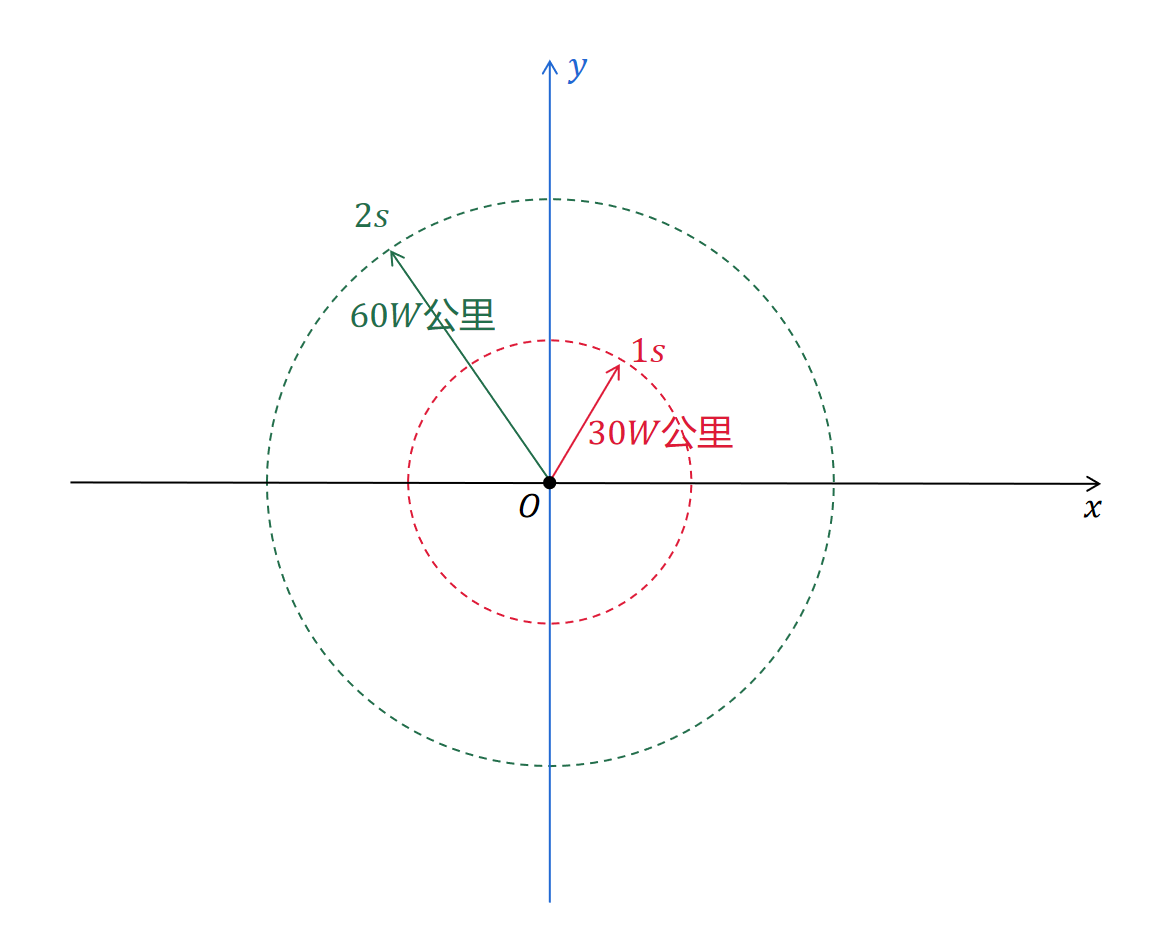
平面上有一个点O,这个点的位置上放置了一个光源。我们以点O为原点,建立一个二维坐标系。位于O点的光源发出的光线,会在这个平面上朝着四周各个方向传播。根据光的传播速度计算,这些光线在1秒后会到达以O为圆心、以30W公里为半径的圆周,在2秒后会到达以O为圆心、以60W公里为半径的圆周。
上面这个图形象地表达了光在二维平面上传播的情况。但为了更好地表现光随着时间的流逝传播的情况,我们增加一个时间维度,得到下面的时空坐标:
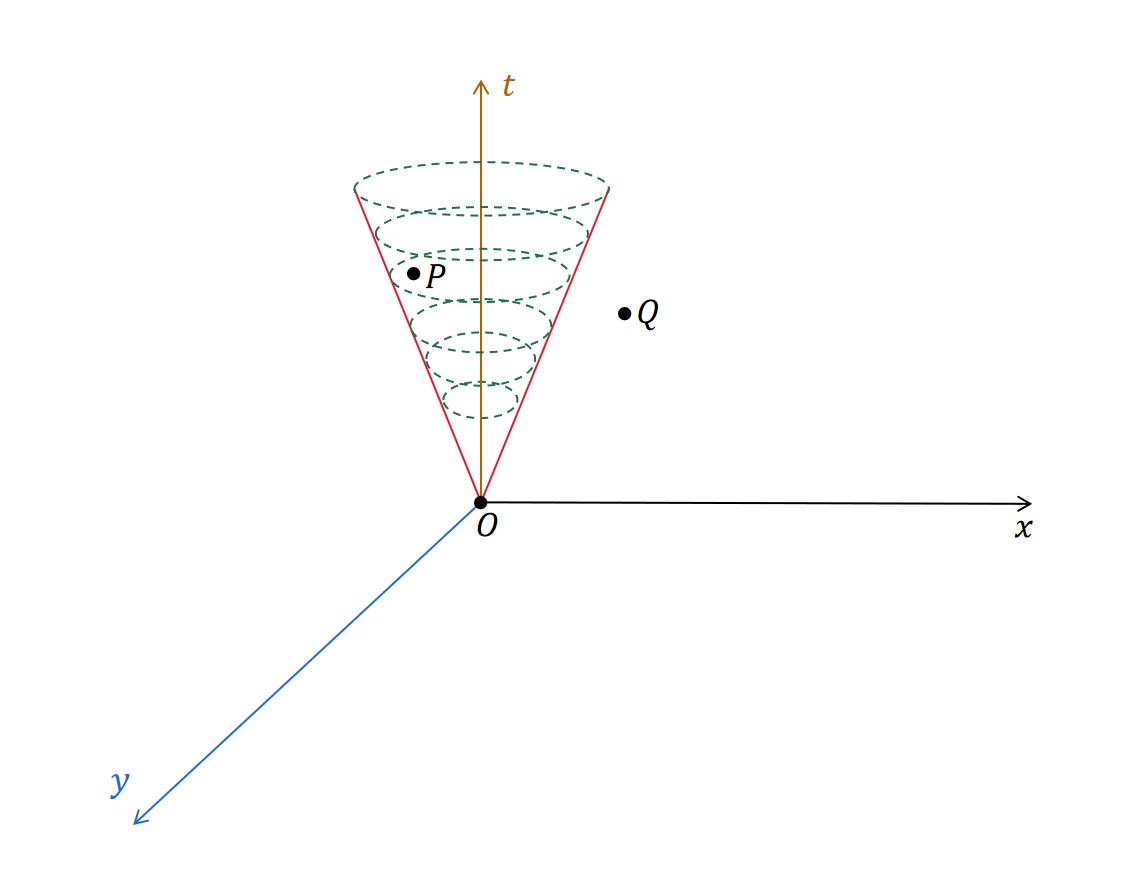
在这个时空坐标中,空间占两维(x和y),时间占一维,形成了一个三维时空。在这样的一个时空坐标中,在每个时刻t,光所到达的地方都会形成一个圆周(图中用绿色虚线圆周表示)。最终,光的传播所经过的时空位置构成一个向上的光锥(称为未来光锥)。
在这个三维时空坐标系中,每个点都可以是一个事件。比如点P,表示在特定位置、特定时刻发生的某个事件。同理,点Q也可以表示一个事件。而原点O,可以表示在原点位置发生于时刻0的事件。
根据相对论,任何信息传递的速度,最快就是光速。而一个事件要想对另一个事件产生影响,至少要在那个事件发生之前传递一定的信息到达所在的空间位置。因此,一个事件所能够影响的范围,就是以它为顶点的未来光锥内部的时空区域。以上图为例,点P在点O的未来光锥内部,因此事件P可能受到事件O的影响;而点Q在点O的未来光锥外部,因此事件Q不可能受到事件O的影响。
这些事件之间可能产生的影响关系,就是我们上一章节末尾所提到的事件偏序关系“➜”。例如,对于事件O和事件P的关系,我们可以用符号表示成:O➜P。但事件O和事件Q之间就不存在O➜Q的关系。
以上为了方便理解,我们讨论的是三维时空的情况(两维空间+一维时间)。而现实世界是四维时空,包括三维空间+一维时间。在四维时空坐标中,我们不再能直观地画出光锥的形状,但背后的原理可以借助理性来类推。
现在,我们来对前面碰到的诸多概念进行一个总结:
- 一个事件可能对它的未来光锥内部的任何事件产生因果性上的影响。
- 一个事件与它的未来光锥内部的任何事件之间,满足一个偏序关系,即“➜”。
与「Happened Before」关系进行对比,我们可以认为,「Happened Before」关系是专门针对分布式系统设计出来的概念,是对相对论中的事件偏序关系的一种模拟。Lamport在论文中定义完「Happened Before」的概念之后,讲了这样一段话:
In relativity, the ordering of events is defined in terms of messages that could be sent. However, we have taken the more pragmatic approach of only considering messages that actually are sent.
(译文:在相对论中,事件的排序是根据可能发送的消息来定义的。然而,我们这里采取了更务实的做法,仅仅考虑那些实际上已经发送过的消息。)
最后我们回到物理时钟的Strong Clock Condition上来。如果每一个物理时钟都能够做到百分之百精确(跟真实时间随时保持一致),那么这个强时钟条件是显而易见满足的。为什么呢?因为由“➜”所表示的两个事件之间的偏序关系,意味着后一个事件在前一个事件的未来光锥之内,当然它的时间坐标就要大于第一个事件了。但是,物理时钟一定是有误差的,当我们从理论回到工程的现实,就需要一个时钟同步算法来保证Strong Clock Condition总是被满足。
物理时钟同步算法
我们的目标是,通过运行一个时钟同步算法,保证时钟对于任何事件打上的时间戳都不产生前面的异常行为(anomalous behavior)。也就是说,对于任意两个有偏序关系的事件(或者说可能在因果性上产生影响的两个事件),我们的物理时钟要保证总是会为后一个事件打上一个更大的时间戳。
要实现这个目标,我们面临的障碍主要来源于物理时钟的两种误差:
- 时钟的运行速率跟真实时间的流逝速率可能有差异;
- 任意两个时钟的运行速率有差异,它们的读数会漂移得越来越远。
Lamport在论文中提出的物理时钟同步算法,做的事情其实就是,将这两种时钟误差考虑在内,不断地对各个进程本地的物理时钟进行微调,把误差控制在能够满足Strong Clock Condition的范围内。算法细节我们就不讨论了,我们这里只说一下算法的指导思想。
分别考虑进程内的事件和跨进程的事件:
- 对于进程内发生的不同事件,必须保证后发生的事件比先发生的事件时间戳要大。这实际上是要求我们保证每个物理时钟实例的读数总是单调递增的。这是比较容易实现的,我们只需要在微调时钟读数的时候,只把读数调大而不把读数调小。
- 对于发生在两个不同进程上的事件,就比较麻烦了。我们还是再考察一下前面Alice和Bob的例子。Bob之所以感受到了异常,是因为Alice通过系统外的一种方式通知了Bob,于是在请求A和请求B这两个事件之间确立起了偏序关系。现在为了保证不出现异常行为,我们就要求,不管Alice向Bob传递信息这个过程发生的速度有多快(最快可以达到光速,但在实际系统中,由于网络延迟和缓存等原因会慢很多),请求B发生时的时钟读数都必须大于请求A发生时的时钟读数。这个要求可能没法被满足的原因,在于两边的物理时钟可能有误差。因此,就需要在不同的物理时钟之间交换信息,并借助这些信息同步时钟读数。通过这种方式,预期可以把时钟之间的误差控制在一定范围内。可以这么说,只要我们在时钟之间交换信息足够频繁,就有希望做到这一点。这是两种机制的赛跑:一方面,Alice通过系统外的方式向Bob传递信息,只要这个过程足够快,他们就有可能“看到”时钟误差造成的时钟读数减退(也就是出现了异常行为);另一方面,物理时钟同步算法通过在时钟之间不断交换信息并按照一定规则调整时钟读数,将时钟误差控制在一定范围内。只要算法的各个参数设置得当,就能保证:即使Alice向Bob传递信息的速度达到物理极限——光速,他们也无法“看到”时钟读数的减退现象。于是,Strong Clock Condition就被满足了。
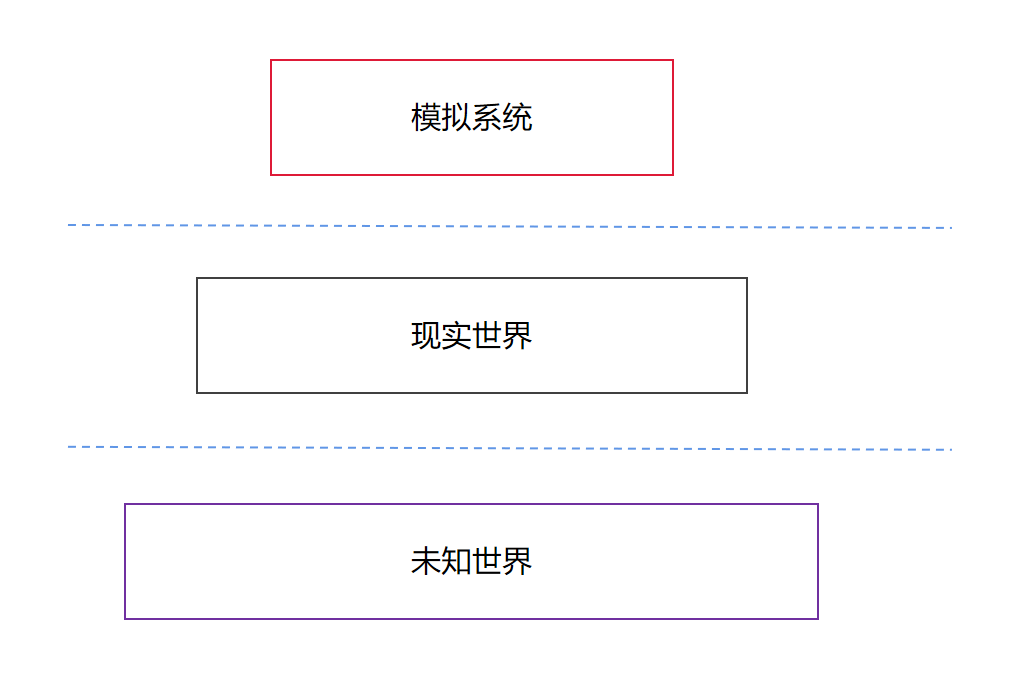
我们这个世界
一个分布式系统自成宇宙,它是对现实世界的一种刻画。分布式系统由不同的进程组成,而不同的进程分布在不同的空间,每个进程可以看成一个单独的参照系。当我们按照这样的观点重新审视这个世界的时候,会产生一些很有意思的想法。
分布式系统是一个模拟系统。如果仅仅使用逻辑时钟,就相当于在使用一种系统内部自洽的方式对时间进行了模拟。由于逻辑时钟跟物理时间无关,因此我们站在系统内是不能感知到现实世界的时间流逝的。Alice和Bob之所以能发现系统的时间戳产生异常,是因为他们之间存在一种系统外的信息传递方式。
假设我们生活在模拟系统内部,我们会发现,Bob在一个较早的逻辑时刻(对应较小的时间戳)接收到了来自Alice在较晚的逻辑时刻(对应较大的时间戳)的信息,相当于接收到了来自未来的信息,而且这个信息是通过不在这个系统内的某种机制传递的。据此,我们也许不需要特意“向外看”,就能推断出在这个系统外部,还有一个世界(我们的这个现实世界)。
同理,在我们当前生活的这个现实世界中,信息传递的速度受限于光速,而且时间永远向前流逝。也许某一天,我们发现了某种超越光速的信息传递手段,或者我们接收到了来自未来的信息(意味着我们可以预知未来了),那么,也许就说明,在我们这个世界的底层,还有一个更大的未知世界存在在那里。
小结
Lamport这篇论文之所以重要,在于它深入到了分布式系统的基础层面,并延伸到宇宙的本质。除了提出「Happened Before」、逻辑时钟、事件偏序等等一系列概念之外,它还划定了系统的能力边界。它告诉我们,什么样的问题可以在系统内部,遵循一个纯异步的模型(asynchronous model)框架就能解决(比如非拜占庭模型下的共识问题);而什么样的问题,必须求诸系统的“外部”(也就是物理世界)才能得到解决(比如拜占庭模型下的共识问题、线性一致性问题等)。所有这些,都深深地影响了人们对于分布式系统的思考方式。
对这篇经典论文以及相关话题的分析,让我们到达了分布式领域抽象层次的一个高峰。后面在分布式系统这个方向上,我们会重回实践,结合一些实际问题和系统,再来做其他方面的一些讨论。
(正文完)
参考文献:
- [1] Leslie Lamport, “Time, Clocks, and the Ordering of Events in a Distributed System”, 1978.
- [2] Paul R. Johnson, Robert H. Thomas, “Maintenance of duplicate databases”, 2015.
- [3] Leslie Lamport, https://www.microsoft.com/en-us/research/publication/time-clocks-ordering-events-distributed-system/.
- [4] Mustaque Ahamad, Gil Neiger, James E. Burns, et al, “Causal Memory: Definitions, Implementation and Programming”, 1994.
其它精选文章:
- 条分缕析分布式:到底什么是一致性?
- 漫谈分布式系统、拜占庭将军问题与区块链
- 知识的三个层次
- 看得见的机器学习:零基础看懂神经网络
- 给普通人看的机器学习(一):优化理论
- 漫谈业务与平台
- 在技术和业务中保持平衡
- 三个字节的历险
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-time-clock-ordering.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。

最新文章
- 为什么agent和workflow可以融合在同一个架构里?
- 万字长文!两栖模式构建Agent,与OpenClaw/Hermes不一样的解法——开源AmphiLoop
- Claude Managed Agents意味着什么?
- 【开源】专为「探路+编码」范式设计的全新浏览器工具集+Skills
- 不用手写一行代码,10分钟立等可取,爬取twitter和github动态
- 使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
- 过年了,聊聊AI和人文
- 使用Bridgic长程自主模块+MCP,控制你的浏览器
- AI智能体纪元或将从2026开始归零
- 从Python异步编程的剖析中体会智能体并发编程模式