【开源】专为「探路+编码」范式设计的全新浏览器工具集+Skills
2026-04-03
读过我前两篇公众号的朋友大概知道,两周之前我们就把浏览器自动化工具库bridgic-browser给开源了。经过大家的反馈和最近两周的打磨,目前已经升级到v0.0.3版本,现在各方面比较稳定了。
欢迎大家star,提交issue甚至提交PR。朋友们的关注是我们继续努力的动力❤️
今天我正式给各位朋友讲讲这个开源库本身的故事(和背后的思考)。
TL;DR
- 一切来源于对未来两个趋势的判断: AI与软件边界的重塑以及未来世界的AI互联。
bridgic-browser是朝着这个未来迈进过程中的一个产物。 bridgic-browser这个库本身的关键feature:体现「先探路、再编码」范式的Skill;一一对应的CLI和Python工具集;支持语义不变性的可预测ref生成算法;用户登录状态保持;等等。- 最后:一个实际案例的生成过程展示(视频)。
bridgic-browser的产生背景
第一点,AI与软件的边界确实在重塑。长远来看,所有可能被自动化的工作流,未来肯定会被AI自动化掉。但是,这里的具体路径上存在两个不同的剧本:
- AI Coding。典型的例子是Claude Code、Cursor。
- AI即时操控软件。典型的例子是OpenClaw、CoWork。
前者(AI Coding),让生产软件(包括自动化软件)更廉价。后者,将自然语言即时转变为行动,直接成为软件的某种替代。
但是,从大的视角看,两种方式都不完美。AI Coding提升了研发效率,也是目前AI落地到B端最重要的一种形式。不过就像我们在上一篇所讲的,类似Claude Code这样的coding agent,就像一台精密的仪器。语言天生的模糊性,需要专业工程师在一个一个的commit中去填补。AI即时操控软件看起来很美好,但它有几个致命的问题:稳定性、安全性、大量消耗token。总之,这些缺陷使得,前者局限在软件工程领域(主要是编码领域);后者局限在C端个人桌面上。
所有这些,影响了AI技术向更广、更加纵深的场景中去应用。
所以说,「先探路、再编码」作为一种新的范式,是未来构建自动化工作流、快速将语言转变为行动的一种很有前景的思路。因为它结合了前面两者的优势:AI通过即时操控工具进行探路,为了后续的AI Coding过程铺平道路,减少猜测、增加客观依据,从而增加一次性编码成功的概率;而通过AI Coding将自动化工作流的逻辑尽量「固化」,提升了稳定性和安全性,同时大大降低token消耗(有时候甚至是零token)。
第二点,在未来世界中,软件和硬件都会通过AI互联起来。我们这里先只讨论软件。一方面,大量软件已经开始CLI化,便于AI去操控。另一方面,以前封闭的体系,包括技术打通难度大的,以及不想开放的,都有可能在AI能力突破后被打破。未来是个高度互联、允许相互编排的世界。但我们今天谈的重点不是这个。
作为未来超级自动化的一个重要组成部分,对于浏览器的自动化自然也需要一套趁手的工具。这个就是bridgic-browser产生的直接原因。而在bridgic-browser设计和编写的过程中,我们始终围绕着「先探路、再编码」这一范式,期望它能够通过不断优化持续降低自动化工作流构建和维护成本。
浏览器自动化的痛点
我们回到浏览器自动化技术。这项技术其实涵盖了非常多的场景,包括但不限于网页爬取、E2E测试、RPA、运维监控等等。所有这些场景都面临一个痛点:当页面结构变化的时候,以前写好的程序就不工作了,必须重写。这个问题在测试场景下尤其严重,因为待测试的页面本身也在快速迭代。甚至是刚用了一次的测试程序,连第二次使用的机会都没有。
很显然,借助当前的AI技术栈,应该让AI来产生代码,从而降低代码修改成本。但是呢,一方面,AI生成是否真正可控这本身就是个问题;另一方面,这里还存在一个待解的问题:AI在真正访问页面之前,它是不知道页面内容的(其实所有基于CLI的自动化生成都有这个问题)。这也是为什么需要「先探路、再编码」的客观基础。
我们建议的做法,是把自动化任务描述成自然语言,存到一个名叫task.md的markdown文件中。类似下面这个样子:
![]()
然后在Claude Code中调用bridgic-browser skill来一次性生成程序。输入如下命令:
/bridgic-browser 执行 @task.md 里面的任务
接下来bridgic-browser skill会引导Claude Code完成「先探路、再编码」的整个过程,把程序生产出来(中间一路按1或2,放行各种执行权限即可)。这样的话,实际需要维护的,就只有task.md。等到后面页面结构发生变化,或者任务需求本身有变动的时候,就可以再次执行上述过程,快速把最新的程序重新生成出来。
bridgic-browser的关键特性
【两套平行工具集】
bridgic-browser提供了非常丰富的浏览器控制工具,目前分为15大类总共67个工具。为了支持「先探路、再编码」,这67个工具分为平行的两套来提供,一套是CLI的,一套是Python的。前者用于探路,后者用于编码。
67个CLI工具如下:
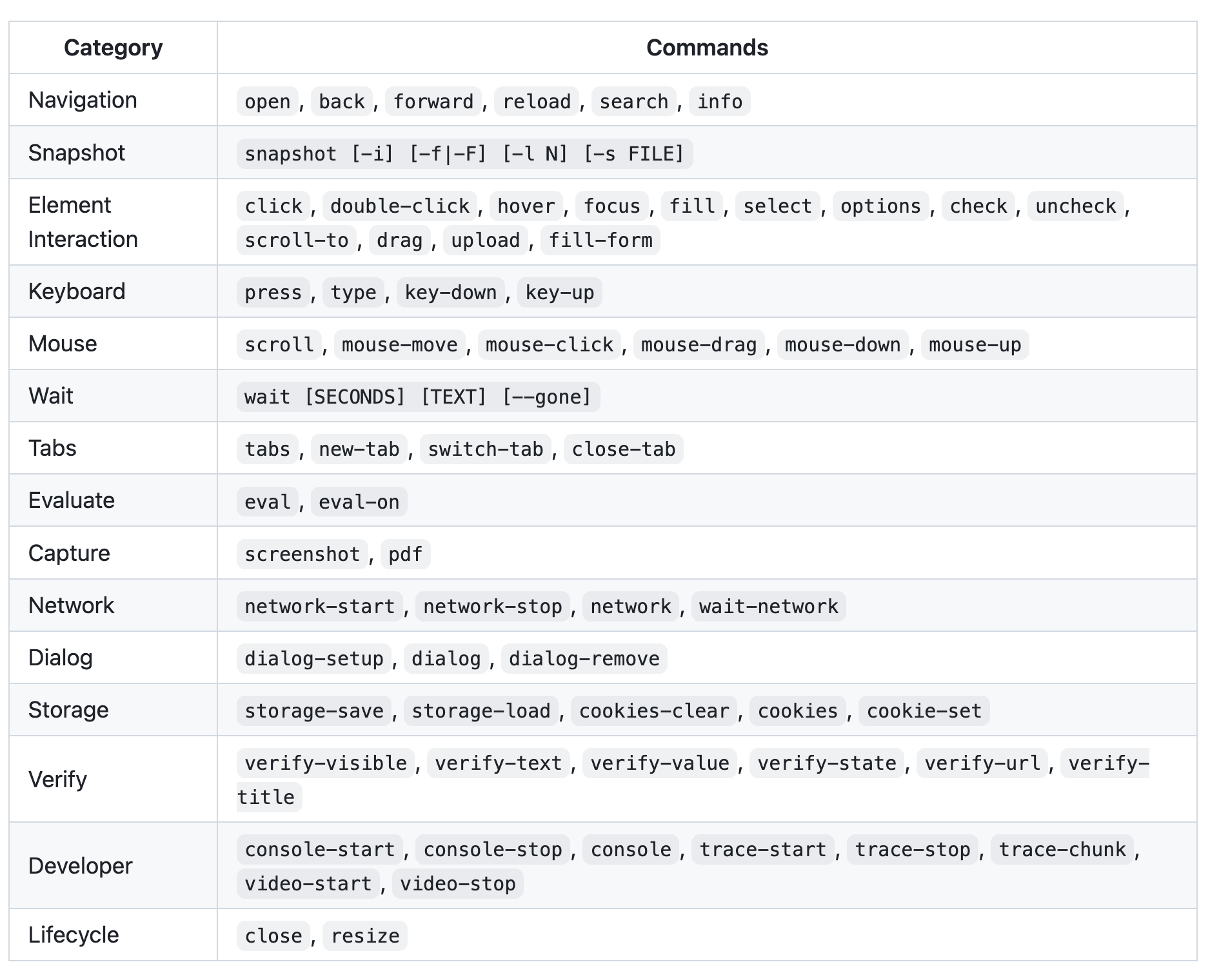
CLI工具与Python工具的对应关系如下(维护在了skill里面):

【探路+编程的Skill】
npx skills add bitsky-tech/bridgic-browser --skill bridgic-browser
基于bridgic-browser的API,这个skill会引导Claude Code (或其他coding agent)完成环境初始化,然后按照「先探路、再编码」的方式工作。而且,关于浏览器自动化过程中的一些「经验」,比如碰到登录页面怎么处理,比如碰到循环列表怎么操作,是打开新Tab还是在原来Tab下去导航,再比如如何尽量模拟人的操作频率,避免被封禁,等等。
【支持语义不变性的ref生成算法】
这个特性是bridgic-browser的一个特色。
很多朋友可能知道,网页结构有两套表示:一个是DOM,一个是无障碍树(accessibility tree)。AI驱动浏览器的时候,使用后者会效果更好,因为它通常带有了更多计算后的操作语义信息。这里通常要解决两个问题:第一,提供页面的一种快照表示,包含无障碍树+ref引用。第二,模型规划下一步后,会确定要操作的ref,然后根据ref精确定位到页面元素去操作。
现在很多AI浏览器方案都采用动态ref的形式。也就是说,页面每次加载,无障碍树所有节点的ref都会重新生成。但为了配合「先探路、再编码」的范式,bridgic-browser的ref并不是完全动态的,而是采用了一种新的生成算法,保证页面结构上的非动态元素的ref在页面重新加载后保持不变。这个做法有利于coding agent在探路后使用静态的ref来做代码生成。
【登录状态保持】
bridgic-browser默认支持登录状态保持。在自动化程序首次执行时,允许通过类似human-in-the-loop的机制让用户来登录一次,bridgic-browser会把包含登录状态在内的用户级数据保存下来。后续程序再执行时就保持原来的登录状态执行,不需要人来处理。
【其他特性】
bridgic-browser还针对一些实际场景做了很多细节优化。比如:
- 默认支持Stealth模式。在无头模式(headless mode)下使用 50+ Chrome 参数 + JavaScript patches,在有头模式(headed mode)下仅使用 ~11 个标志,以匹配真实 Chrome 的指纹特征。
- 网页快照支持获取到嵌套iframe内部的信息。有些富文本编辑器或页面嵌入视频,以及Google的reCAPTCHA都是iframe嵌入形式存在的。
- 更适合AI的网页快照返回和保存机制。默认行为下,当页面数据较少时,快照直接返回;而当面超过阈值时,快照数据会存入文件,避免撑爆AI Agent上下文。
- 网页快照支持获取placeholder。
- 交互模式下网页快照包含link地址信息。
- ref定位算法支持优雅降级,6级策略覆盖所有结构场景,提高AI操作容错性。
生成过程实例展示
下面录制了一个探路+代码生成的例子。它的主要功能是到Andrej Karpathy的X (twitter) 主页上获取最近一段时间的动态(中间涉及登录过程)。task.md内如如下所示:
![]()
视频参见# 自动化工作流生成示例。
小结
本篇出现的task.md任务描述示例,可以到GitHub上下载,然后测试体验:
https://github.com/bitsky-tech/bridgic-examples/tree/main/browser-automation-examples
另外注意:本文介绍的skill既可以用在Claude Code中,也可以与OpenClaw等产品配合使用。当然具体效果(生成成功率和产物质量)会随着模型不同而有些差异。效果最好的目前还是Claude Code。
目前相关的源码和方案仍然在快速迭代中,欢迎试用、留言讨论。您的反馈是推动项目进展的重要动力。感谢star:
(正文完)
其它精选文章:
- 不用手写一行代码,10分钟立等可取,爬取twitter和github动态
- 使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
- 过年了,聊聊AI和人文
- AI智能体纪元或将从2026开始归零
- 【开源】我亲手开发的一个AI框架,谈下背后的思考
- AI Agent时代的软件开发范式
- AI Agent的概念、自主程度和抽象层次
- 科普一下:拆解LLM背后的概率学原理
- 分布式领域最重要的一篇论文,到底讲了什么?
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-release-bridgic-browser.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。

最新文章
- 为什么agent和workflow可以融合在同一个架构里?
- 万字长文!两栖模式构建Agent,与OpenClaw/Hermes不一样的解法——开源AmphiLoop
- Claude Managed Agents意味着什么?
- 【开源】专为「探路+编码」范式设计的全新浏览器工具集+Skills
- 不用手写一行代码,10分钟立等可取,爬取twitter和github动态
- 使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
- 过年了,聊聊AI和人文
- 使用Bridgic长程自主模块+MCP,控制你的浏览器
- AI智能体纪元或将从2026开始归零
- 从Python异步编程的剖析中体会智能体并发编程模式