万字长文!两栖模式构建Agent,与OpenClaw/Hermes不一样的解法——开源AmphiLoop
2026-04-14
今天非常高兴,我们正式推出一个全新的开源代码库——AmphiLoop。但是,这不仅仅是一个代码库,更是一套全新的AI智能体构建方法论、技术栈和工具链。它允许我们使用自然语言对任务进行描述和编排,同时具备运行时在workflow模式和agent模式之间自动切换的能力。
这也正是这个项目名字AmphiLoop的由来——Amphibious Loop (两栖循环)!接下来我会详细介绍整个体系和背后的原理,文章很长,全部是我手敲成文(无任何AI辅助),建议先收藏后慢慢再看。
龙虾的爆火和企业落地的难点
「龙虾」已经成为这个时代的一个符号。
它的爆火确实有它的道理:日常工作中确实存在大量的繁琐的操作,类似整理资料啊、搜索信息啊、跨系统搬运表单啊,这些操作都不难却消耗着人的精力。有了类似OpenClaw、Hermes Agent、CoWork这样的智能体之后,普通人第一次拥有了能够快速将语言转变为行动的工具。人可以从繁琐的、一步一步的亲手操作中抽离出来,摇身一变,不做「牛马」,只需做「审查者」,这个体验确实是充满愉悦的。
企业当然想把龙虾的能力引入到主营业务当中,因为按照常理推论,用自然语言驱动业务流程的自动化,这意味着生产率的极大提升。但是,AI能力难以驯服的特点,这个时候在龙虾的身上就体现得淋漓尽致:
- 安全吗?不给它权限它就没法真正干活儿,给了权限万一它乱搞怎么办?
- 稳定吗?在个人桌面上跑跑,偶尔不听话也就算了;但在严肃场景下,能保证100%运行稳定吗?
- 成本高吗?都知道龙虾可是个token消耗大户,而且随着用法不同波动很大。对于个人用户来说,一个月的token账单爆了,顶多一个月多花个几百块,可能也没什么大不了的;但对于企业用户来说,账单爆了可不是闹着玩儿的。
再从需求任务的规模来看,企业任务与个人任务也有所不同。个人任务通常是桌面上的小任务,整理邮件、整理文稿、检索信息,等等。这些任务的规模通常是微小的,当然,自动化带来的愉悦感也就是那么一瞬。但更酷的事情其实在于,使用AI构建整个自动化系统。
实际上,AI Coding的效率提升,已经让软件产品的迭代生产急剧加速。引发的问题在于,从整个软件工程的生命周期视角来看,编码效率提升了,那么其他阶段的效率也要跟得上才行。测试、部署、运维,甚至是需求的产生和管理,也都要跟得上新时代的软件迭代速度。这需要构建一整套AI自动化系统。
速度的提升意味着频繁的变更。就拿自动化测试来说,假如产品界面每天都在迭代,甚至一天迭代好几版,如何才能让自动化测试跟得上这个节奏?依照「常理」,对频繁变更的产品进行测试,干脆也别写测试脚本了,人工来测试算了,但这会消耗大量的人力成本。反之,如果维护一套自动化测试脚本,随着产品快速迭代,测试脚本也要频繁修改,又带来了额外的维护成本。还有一种方案,使用「龙虾化」的方案:假设有一个企业内部可用的“大号”龙虾,每当产品需求变更了,那么就把产品需求直接扔给这个龙虾,让它来执行自动化测试。这个思路是有一定的道理的,毕竟自动化测试其实也是在调用各种工具,而当前使用工具效率最高的方式,就是通过AI来调用(用魔法对抗魔法嘛)。但是,这就回到了前面讨论的一些问题上:它执行可控吗(稳定性问题)?它token消耗大吗(成本问题)?
之所以这么纠结,是因为很多时候,我们的需求本身就是看似「矛盾」的,或者说,是「既要又要」的。既想要那种将语言快速转变为行动的高效率(以适应环境变化),与此同时,又想要可靠、安全、成本低。
所有这些,影响了AI技术在更广、更加纵深的场景中被采用。
以前有人会说,这主要是准确率的问题。随着模型能力提升,准确率上去了,就稳定可控了,就可以在更多场景中使用AI了。说实话,这个结论非常片面。放眼历史上数次工业革命,当前AI这种工具,不同于蒸汽机、内燃机、电力以及信息技术中的大部分工具,它本质上就是基于概率的、充满不确定性的。当今的AI是一种柔性的力量,解决的也是偏柔性的问题。准确率再提升,也达不到100%的确定性;另一方面,token的成本问题也不容小觑。
所以说,AI技术落地难的主要原因,并非它的准确率还不够高,而是我们使用这种独特能力的方式不对。以正确的方式运用技术,才能发挥最大的威力。因此,我们需要一套全新的驾驭AI的方式、一套全新的方法论和技术栈。
这也是我们开发AmphiLoop(以及它所依赖的Bridgic框架)的底层逻辑。
问题的本质分析
我们前面提到过,AI是一种独特的工具,它天生就不可能达到准确率100%。在我去年年底的《AI智能体纪元或将从2026开始归零》一文中,我们也讨论过一个概念,称为错误累积效应。举个例子:假设执行一个任务分5步,每一步执行成功的概率是90%,那么整体执行成功的概率只有59%。
这意味着,随着任务要执行的步数越来越多,AI驱动任务出错的概率也会越来越高。注意,错误累积效应是根植于概率学当中的,是不可能改变的。那是不是就意味着,使用AI完成自动化任务,在本质上就是没有希望的?如果这样的话,当前龙虾的产品形态,发展到目前这个阶段是不是就算到头了?它或许注定了只是个AI玩具,永远也别想在真正严肃的、价值高的场景下使用?
当然了,这个问题本身的描述就过于粗放。我们需要拆解开来分析。
首先,不同的任务其实性质也不同。按照“任务的目标和路径是否明确”这个维度,我们先尝试对任务进行一个粗略的分类:
- (1)确定性的任务。任务的目标和路径都很明确。比如,登录到某个App上,进入任务中心,帮我签个到(该场景仅限于技术讨论)。这一类任务大量存在,使用传统的编程技术就能够实现自动化。其主要问题在于实现成本。
- (2)目标非常明确但路径不清晰的任务。比如,下棋对弈,或者对战类的游戏。目标是赢得比赛、击败对手,非常明确,但具体怎么赢不知道。
- (3)目标大致明确的任务。这一类任务也大量存在,但只是到了大模型时代才有了相对有效的解法;以前的传统编程技术对这一类问题解决得非常不好。鉴于这一类问题很重要,我多举几个例子。
- 第一个例子:比如指定目录下有很多收集好的资料和工作文件,请帮我整理这些材料,然后写一个XXX主题的报告。这个任务的目标相对明确,要写出一个报告,但是报告写成什么样子,质量如何,并不明确。所以我们说“目标大致明确”。至于具体实现路径,到底这个报告怎么写出来,写的过程中先查哪一个资料,再查哪一个资料,参考资料中的文段如何在报告中被引用和组合,我没有指定,也不想操心。所以说,这个任务的路径是不明确的。
- 第二个例子:全网搜索Andrej Karpathy的最新动态,总结一下他最近在关注什么以及有什么新的研究方向。目标相对明确,但去哪里搜信息、怎么搜,这个路径不明确。
- 第三个例子:基于参考图和剧本帮我生成一个视频。“生成视频”这个目标是明确的,只是视频生成出来是什么样子我才会满意,这个不明确。同样,怎么完成生成的路径也不明确,我也不关心。
- 第四个例子:帮我整理下桌面;帮我批量回复邮件,等等。
- (4)混合型任务。通常是前面(1)(3)两类任务的组合。比如,去GitHub上查看某个代码库的release页面,翻页查看最近7天的发布记录,然后写一个总结,告诉我最近主要的迭代方向是什么。这个任务的前半部分是确定性的任务(目标和路径都很明确);后半部分则属于第(3)类任务。
其次,我们再考察一下事情的另外一面:为了自动化执行这些不同种类的任务,我们有哪些方法可用?在LLM出现之前,我们需要构建软件程序,也就是确定性代码(有分支、有循环),来执行一个任务。而在LLM出现之后,我们手里又多了一种方法:使用agentic loop(类似龙虾提供的即时规划与执行的能力)。就像我在之前的《AI Agent时代的软件开发范式》一文中所讲 ,LLM带来的planning的自主性,是AI Agent时代软件开发中「新」的特性。所以,现在我们拥有了本质上截然不同的两种执行模式:workflow模式和agent模式,前者使用确定性代码(不依赖模型),后者使用类似龙虾的agentic loop(依赖模型)。
OK,前面的几种任务分类和这里的两种执行模式,它们之间的对应关系,我们现在可以总结如下:
- 第(1)类确定性的任务,既可以由workflow模式来驱动,也可以由agent模式来驱动。
- 第(2)(3)类任务,包含更多「不确定性」,只能由agent模式来驱动。
看起来agent模式似乎是「万能」的,它好像什么都能做。但这正是当前对于AI的使用和预期发生错位的地方!这里的第(1)类确定性的任务,当它由agent模式来驱动的时候,存在诸多的问题:
- 当任务复杂了(长程的),它就不稳定。同样的任务,重复执行很可能获得不一样的结果。这是由前面说的AI的概率学本质所决定的,错误累积效应在这里体现明显。
- token消耗极高。agent模式的能耗远远高于workflow模式。
- 不稳定还会引发很多安全性问题。比如,执行出错,导致越权或执行危险操作;prompt被注入,导致被远程控制。
这是当前人们使用AI的一个重大误区!使用错误的方式来解决本来确定性的问题。这也是很多人在使用龙虾中经常犯的错误,不管什么任务都一股脑都扔给AI。
所以说,对于即时性的(可能是一次性的)、路径不明确(目标也不一定明确)的任务,使用agent模式是最合适的(有时候是唯一的方式);而对于确定性的、长程的、routine执行的任务,使用workflow模式才是最合适的。
当然呢,workflow模式有它的劣势:变更不够灵活,也无法应对环境的变化。所以,为了结合各种技术优势,我们就能理解AmphiLoop的一些关键设计决策:
- 使用自然语言来描述任务。享受将语言快速转变为行动的高效率,需求变更灵活。
- 一套由「探路 - 编码 - 验证」循环来引导代码构建过程的方法论和工具。AmphiLoop并不直接使用agent模式执行自然语言描述的任务,而是以最低成本将自然语言转化成代码。「探路 - 编码 - 验证」的方法论用于降低这个转化的门槛。
- 生成的代码同时包含workflow模式和agent模式。两个模式可以相互结合、甚至自动切换。这也是amphibious这个词的来历。
对于workflow模式和agent模式的相互结合、自动切换,这里还需要做一些补充。我们前面把任务的分类展开之后会发现,现实世界其实还是挺复杂的。但其实这还不算完,现实世界的任务还包含着更多变化。
第一个变化是,一个任务包含的「不确定性」有多少,是跟任务的具体描述高度相关的。什么意思呢?比如说,前面第(3)类任务中的“搜索Andrej Karpathy最新动态”那个例子,我们没有指定具体去哪里搜、怎么搜。这个时候它的路径是很不明确的,这也有可能影响任务的执行效果。我们尝试把更多关于Andrej Karpathy的个人经验写进这个任务。假设我们先做了一下调查研究,发现Andrej Karpathy有一个个人网站,3个blog地址,还有一个YouTube channel,但是这些至少半年都没有更新了。而Karpathy保持频繁活跃的地方,主要是两个:一个是twitter (x.com), 一个是GitHub。那这时候我的搜索策略就变得明确了、有针对性了。如果我们把这些具体的搜索策略写进任务描述,那么这个任务就具有了更多「确定性」的部分。
这说明,对需求进行描述的详细程度、具体程度,可能会导致任务中原来不确定性的部分变得确定,或者反过来,让原本确定性的部分变得不确定。这就要求我们的方案需要基于语义恰当地生成代码,最好是任务中确定性的部分按workflow模式生成代码,而不确定性的、需要自主性发挥的部分,就按照agent模式生成代码。
第二个变化是,任务在执行过程中可能遭遇环境变化。比如,对一个网站页面进行自动化操作,但某一天页面发生改版了,导致元素位置或名称发生了变化。再比如,前面我们提到的自动化测试场景,待测试的产品页面由于需求变更导致布局变化。平常情况下,可能workflow模式来执行更合适(稳定、省token),但一旦这种环境变化发生,workflow模式就处理不了了。这时候最好程序能够自动切换到agent模式继续推进任务执行。
以上这两个问题,都是AmphiLoop在架构设计时考虑到的问题。可见,这已经不是业界当前所熟知的智能体运行模式了。它既不是单纯的workflow模式,也不是单纯的agent模式,而是一种全新的智能体运行模式——amphibious模式(水陆两栖模式)。
AmphiLoop 介绍
AmphiLoop是什么?
AmphiLoop,全称是Amphibious Loop (两栖循环),是一套全新的AI智能体构建方法论、技术栈和工具链。它允许我们使用自然语言对任务进行描述和编排,由一个「探路 - 编码 - 验证」循环来引导代码生成和构建过程,并且产物具备运行时在workflow模式和agent模式之间自动切换的能力。
目前,AmphiLoop以一个plugin的形式存在,内部包含相应的commands、skills、subagents和hooks,用于与Claude Code等支持plugin的coding agent一起使用。
AmphiLoop背后由Bridgic项目的几个子框架支撑:
bridgic-amphibious:为产物提供水陆两栖特性。bridgic-core:提供底层基础编排和概念抽象,以及human-in-the-loop支持。bridgic-browser:在浏览器自动化方面提供CLI和Python工具。
AmphiLoop能干什么?
概括讲:
- 用
TASK.md自然语言描述并维护长程自动化任务。这是一种可管理的需求描述形式的雏形,不同于一次性描述完任务就丢弃的方式,这种方式允许将任务看成一个可升级迭代、可维护的单元。 - 由command引导低门槛生成workflow代码。可重复执行、稳定、零token;生成成功率高,基本一次性成功。
- 由command引导生成独特的amphiflow代码。代码同时具备workflow模式和agent模式,可基于环境变化自动切换模式。
- 理论上支持任何长程自动化任务,但在浏览器自动化方面经过了优化,并配备有专门的bridgic-browser工具集。
AmphiLoop如何安装
与Claude Code配置使用时,只需要执行以下两个命令:
# Step 1: 注册 marketplace
claude plugin marketplace add bitsky-tech/AmphiLoop
# Step 2: 安装 plugin
claude plugin install AmphiLoop
也可以进入Claude Code后使用 /plugin命令进行管理(安装、更新、卸载等)。
AmphiLoop用法举例
上手使用AmphiLoop很简单,只需要在Claude Code中手敲 /build-browser命令,系统会提示出完整命令,如下:

然后系统就会引导后面的流程。整个流程大致分为以下几个阶段:
- 创建
TASK.md。 - 选择几个关键配置选项。
- 环境初始化。
- 探路,产生探路报告。
- 生成代码。
- 验证。
- 进一步修复代码(可能)。
基本上,你只需要关注第一步,根据系统提示创建好TASK.md,用纯自然语言描述好任务要求。
建议使用AmphiLoop时尽量选用coding能力比较强的模型,可以大大提高代码生成的成功率。AmphiLoop的优势在于,一旦程序生成成功,后面的执行会大大降低token消耗(对于确定性任务来说是零消耗)。
【创建TASK.md】
执行完/build-browser命令之后,如果任务需求还没有创建,那么系统会做如下提示:
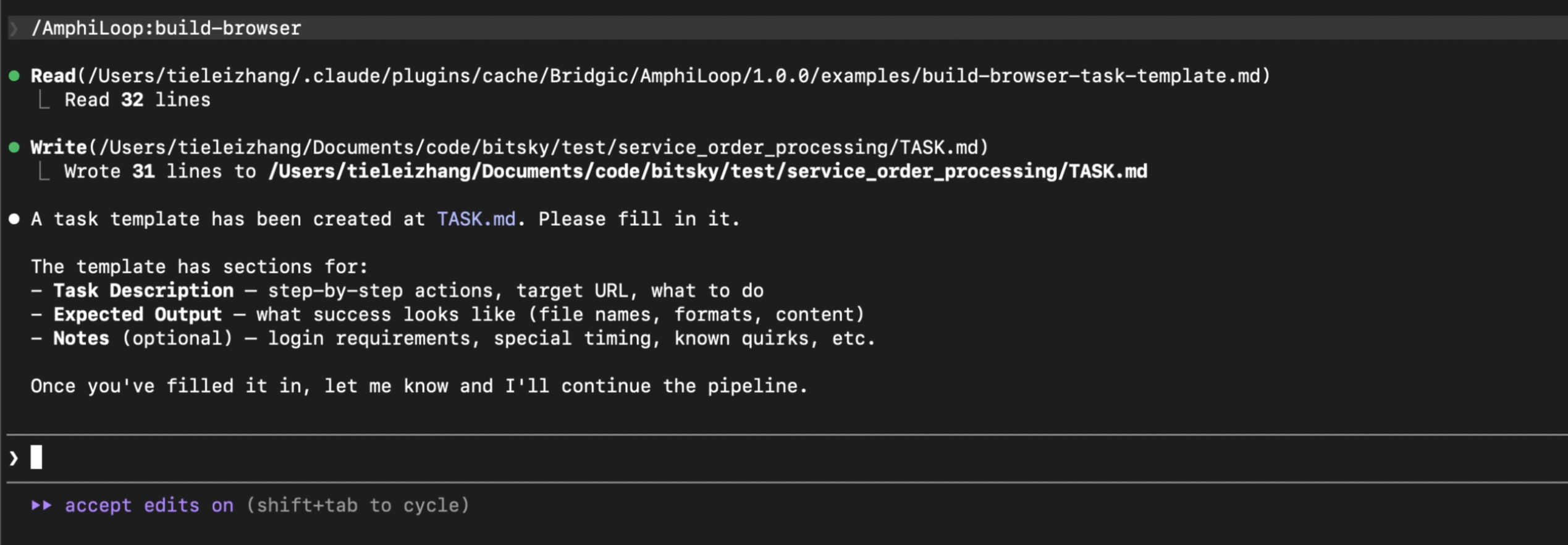
系统已经为你准备了一个TASK.md的模板。接下来你需要修改这个模板的内容,把自己的需求描述出来。在整个使用过程中,这是唯一需要你必须要做的事情。下面是一个例子:
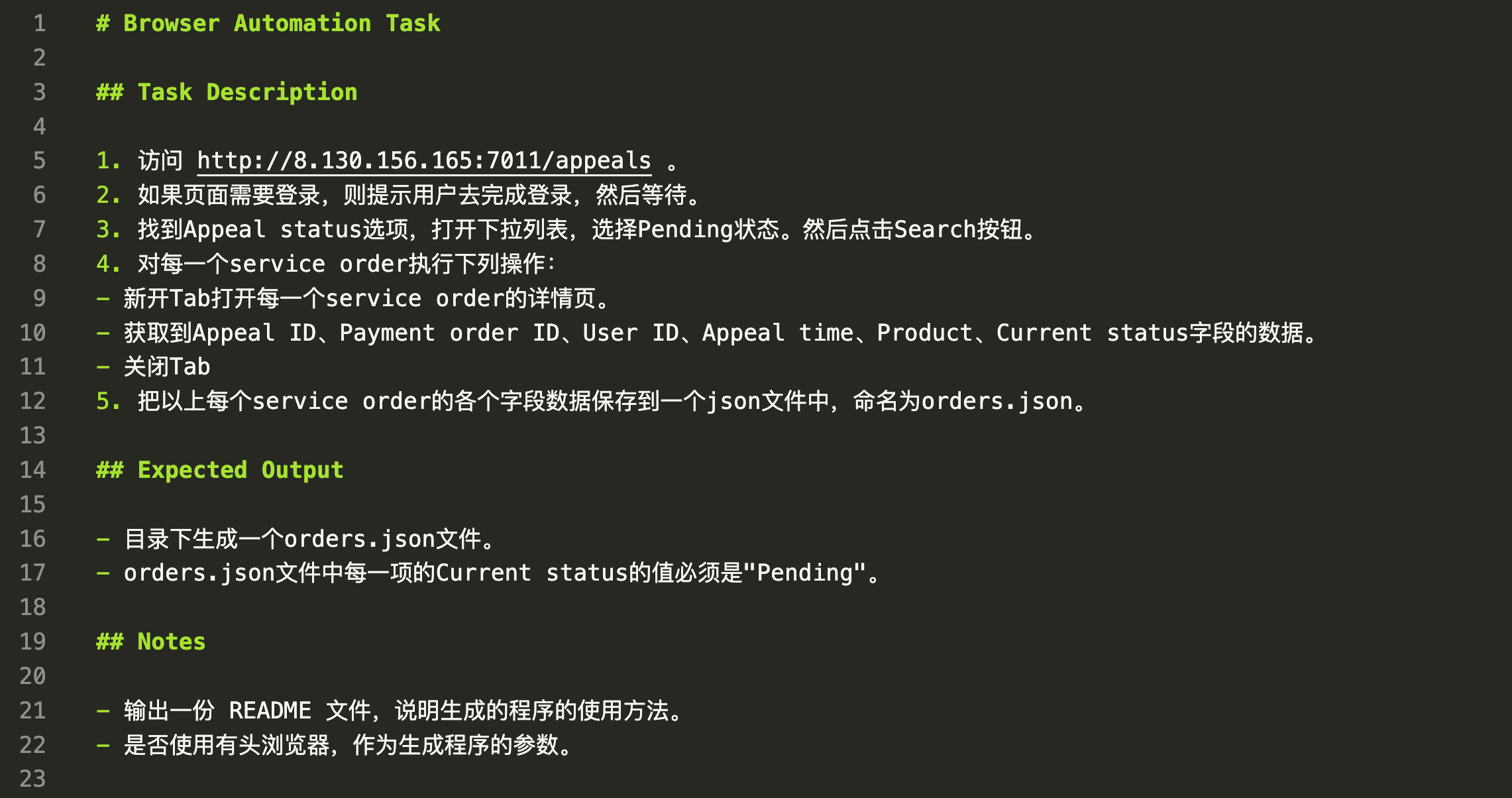
这个文件使用自然语言描述就可以:
- 在Task Description部分,尽量具体地描述要任务执行的每一步动作。
- 在Expected Output部分,描述一下这个任务的预期产出(指的是生成的程序执行后的最终产出物)。注意,AmphiLoop最后会检查Expected Output这里的描述,并据此对生成程序的执行结果进行验证。这是提高程序生成成功率的非常重要的一段描述,需要认真对待。比如在上面截图的这个例子中,Expected Output部分不仅提到了程序会输出一个
orders.json文件,还提到了这个文件中某些可以用于校验的状态。 - 在Notes部分,可以提一些自己个性化的要求。比如生成的程序需要哪些控制参数。
写好TASK.md后,告知Claude Code已经完成:
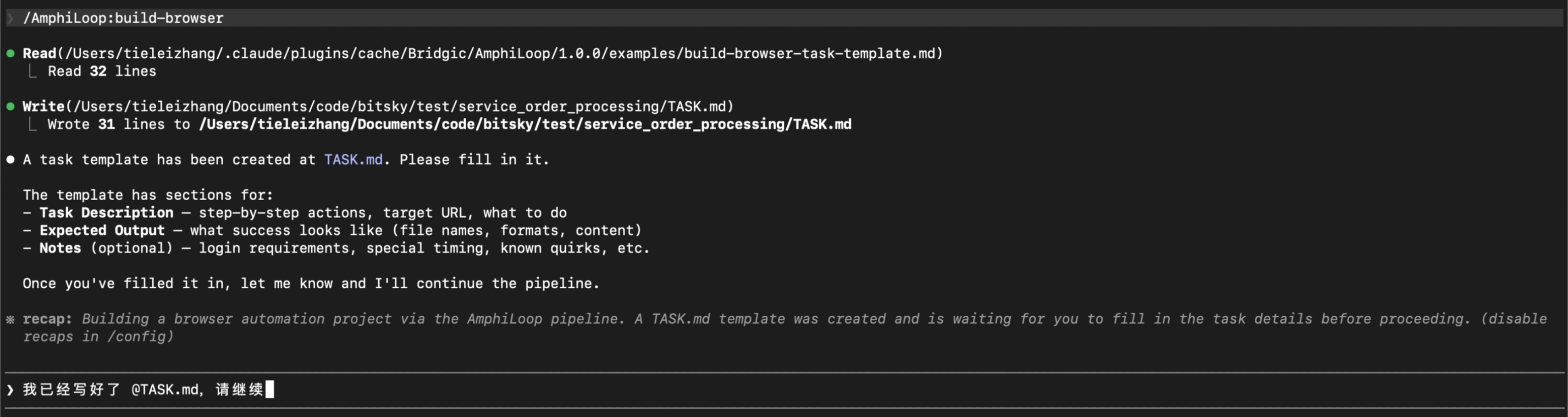
在完成这一步之后,如果TASK.md描述比较清晰的话,后面的过程基本是自动的。你需要做的主要是按1或2来放行Claude Code的一些权限询问。
【选择配置选项】
当前AmphiLoop plugin提供了两个配置选项,需要你根据需求来做一下选择。
第一个配置选项是:项目模式。
AmphiLoop提供了两个选项:
- Workflow:也就是生成的程序主要运行workflow模式,适用于稳定、可预测的任务。这种模式只在必要的时候调用LLM。因此,如果TASK.md描述的任务不包含「不确定性」的成分,那么生成的程序就是零token消耗的。
- Amphiflow:这是AmphiLoop提供的一种独特的程序代码形式,生成的程序同时具备workflow模式和agent模式,可基于环境变化自动切换模式。如果选择这种项目模式,下一步需要创建
.env文件来配置一个LLM模型(agent模式运行时需要)。适合需求变更频繁、运行环境可能变化的任务。
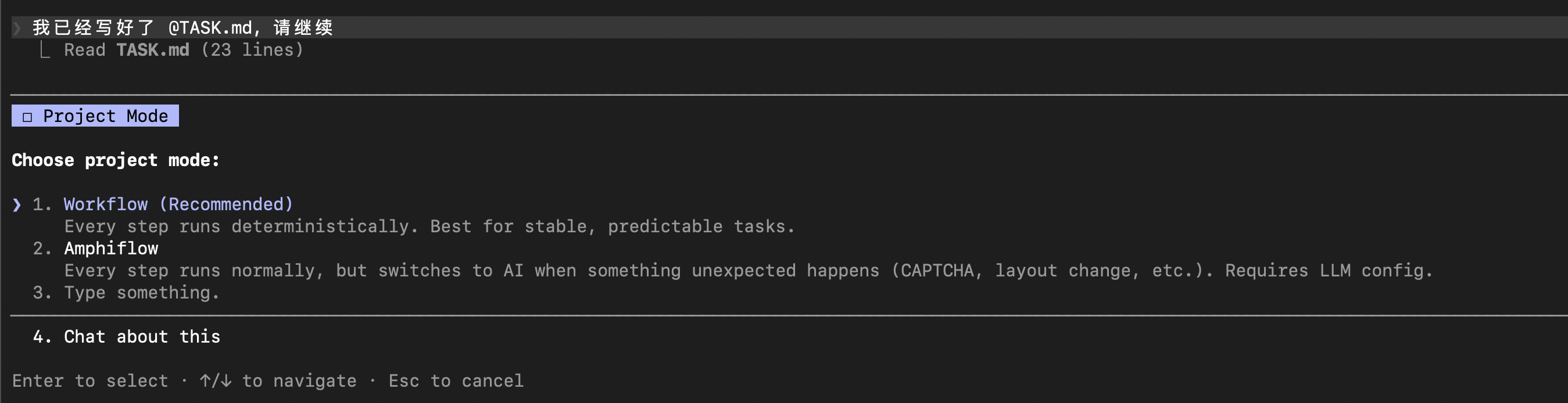
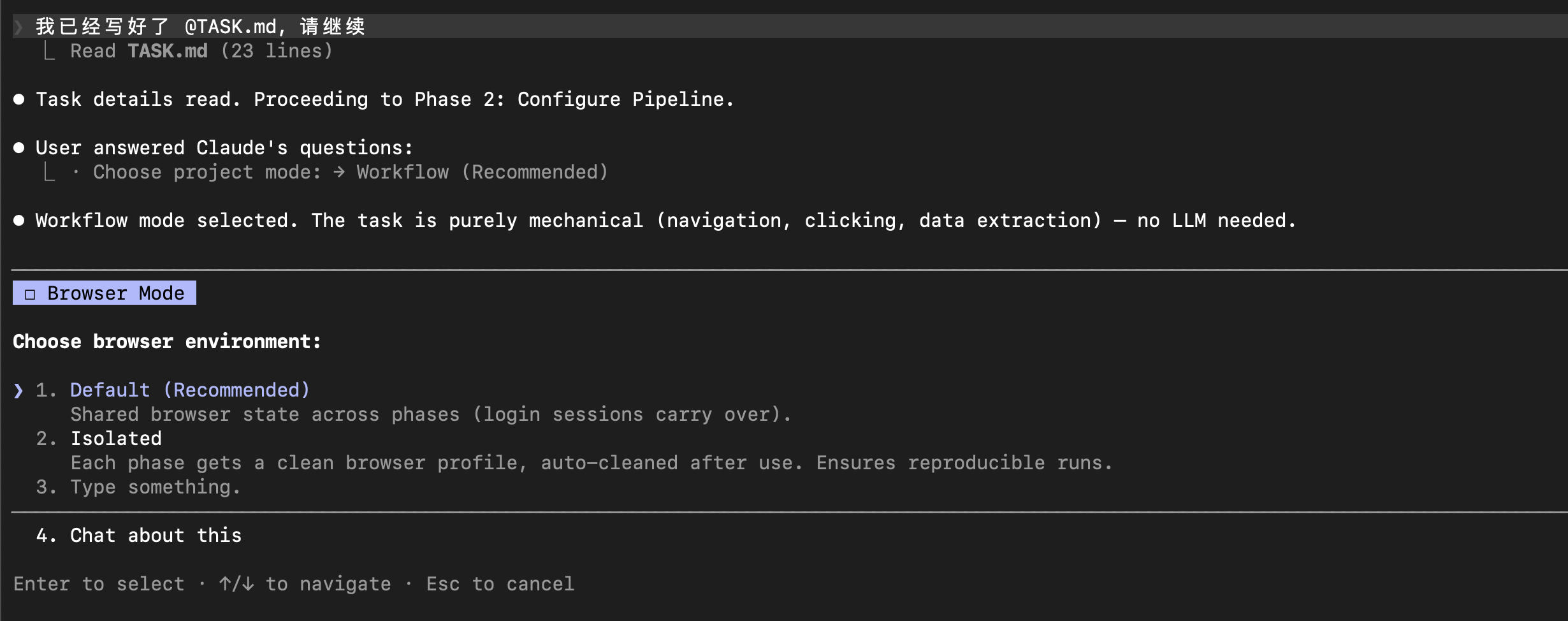
第二个配置选项是:浏览器模式。
当任务涉及到浏览器自动化时,这个选项会出现。这里提供了两个选项:
- Default模式:不同的浏览器实例会共享用户状态。比如,只要登录一次,下次再打开浏览器,登录状态一般会被保持。
- Isolated模式:不同的浏览器实例使用各自隔离的用户状态。也就是说,每次打开浏览器,用户状态都会清理掉。可用于自动化测试等需要的场景。
【环境初始化】
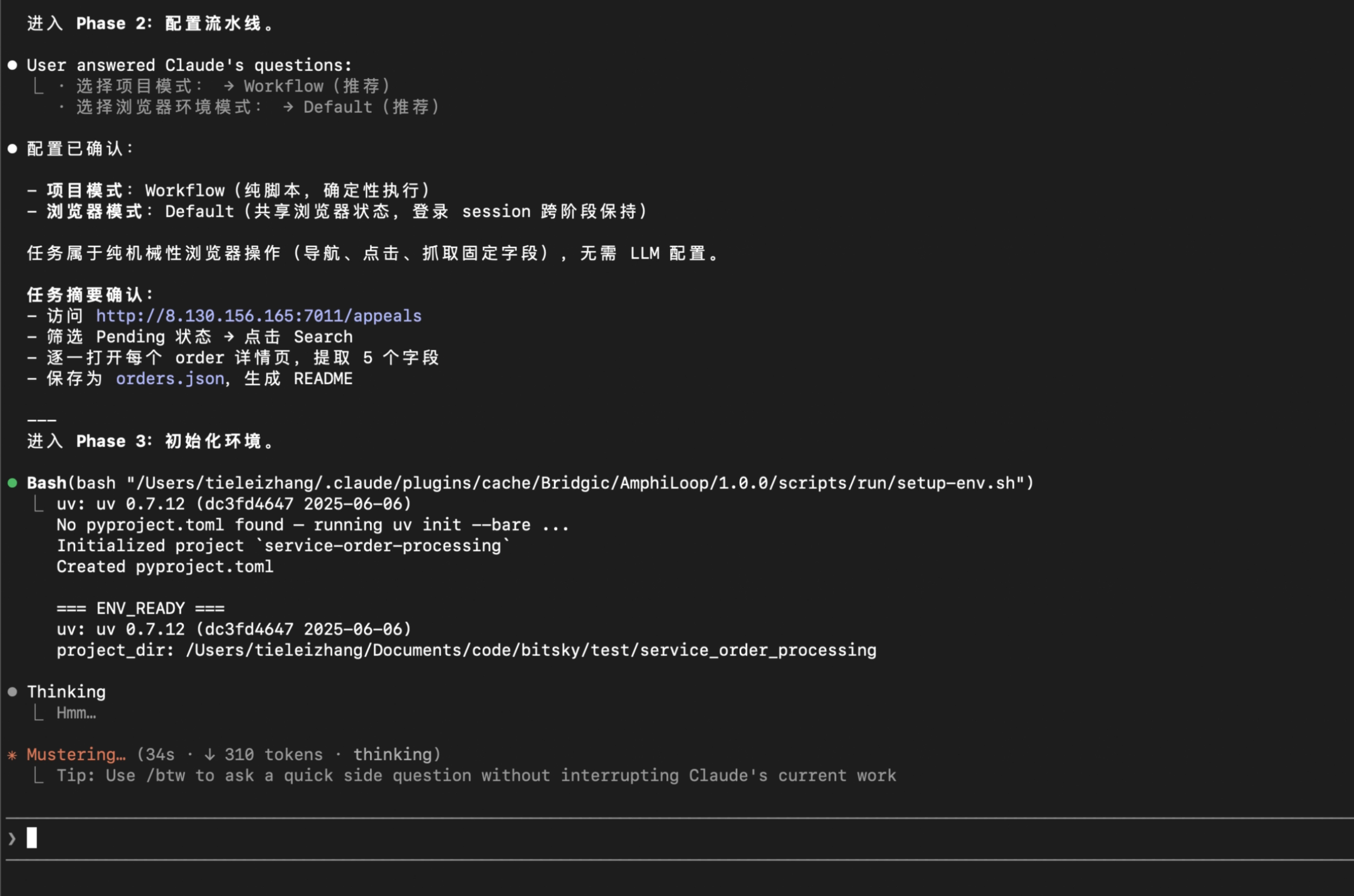
这一步是完全自动执行的。AmphiLoop plugin目前使用uv来管理构建环境和执行环境,使用者完全不用操心背后的依赖如何安装的问题。
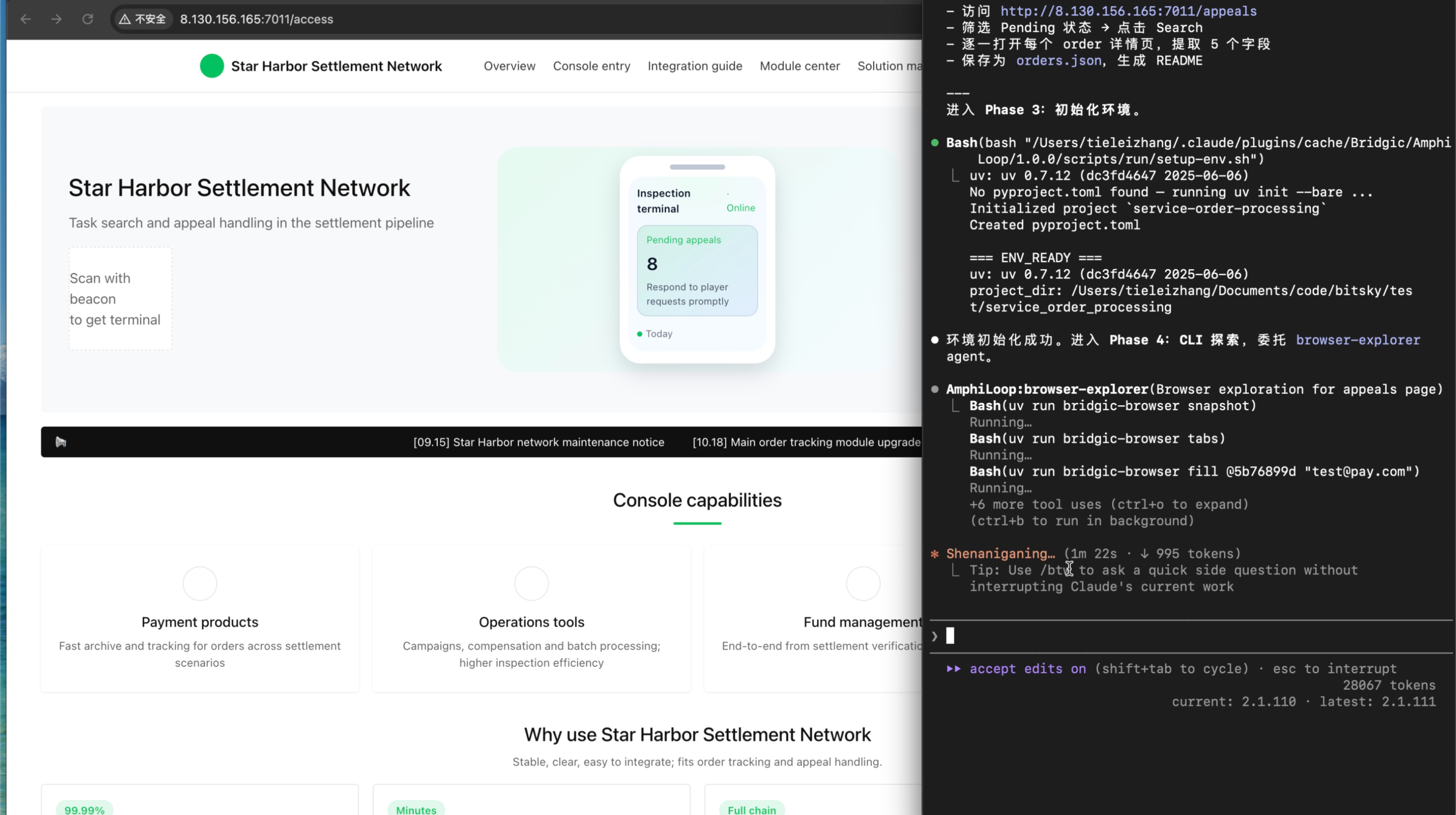
【探路】
探路指的是系统基于任务描述来对执行路径进行一定程度的探索,为后面的代码生成做好准备。在探路过程中,系统会调用CLI工具(包括bridgic-browser的CLI工具),获得一些动态的、未知的信息,比如CLI工具的核心调用顺序、返回值、页面结构等信息。
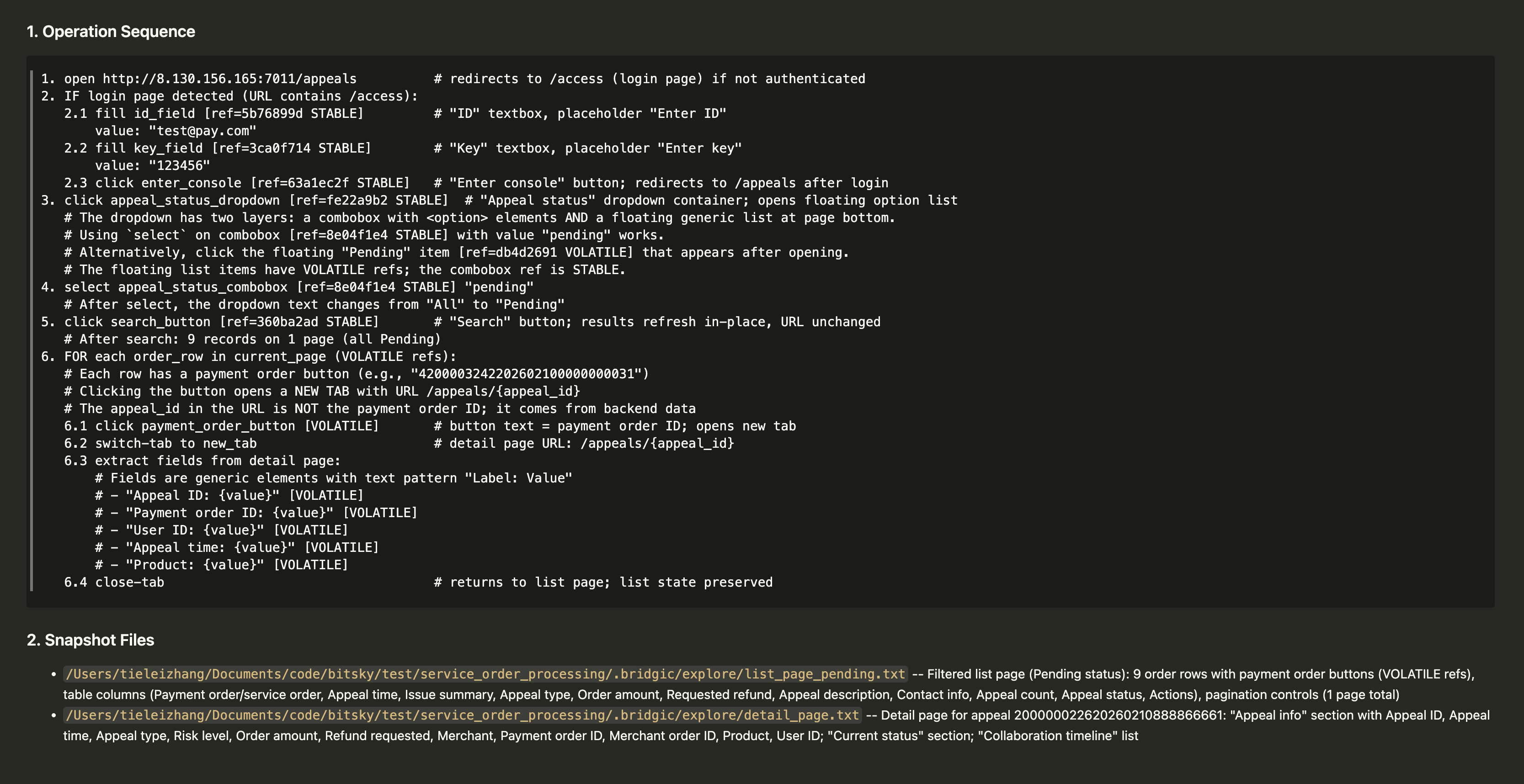
探路结束后,会产生一个探路报告exploration_report.md。下面是一个样例:
【生成代码】
这一步是完全自动执行的。系统参考前面的探路报告,撰写代码。根据前面选择的「项目模式」选项,这里系统会相应地生成Workflow程序或Amphiflow程序。
【验证并修复代码】
在生成代码完成后,AmphiLoop会引导Claude Code对生成的程序进行验证测试。
一方面,AmphiLoop会验证程序是否能够正常运行;另一方面,它还会关注TASK.md中Expected Output的描述,据此对程序的执行结果进行验证。
如果它发现错误情况,会自动修复代码。在修复代码的过程中,AmphiLoop可能会引导程序多次运行并验证,这是预期之内的情况。
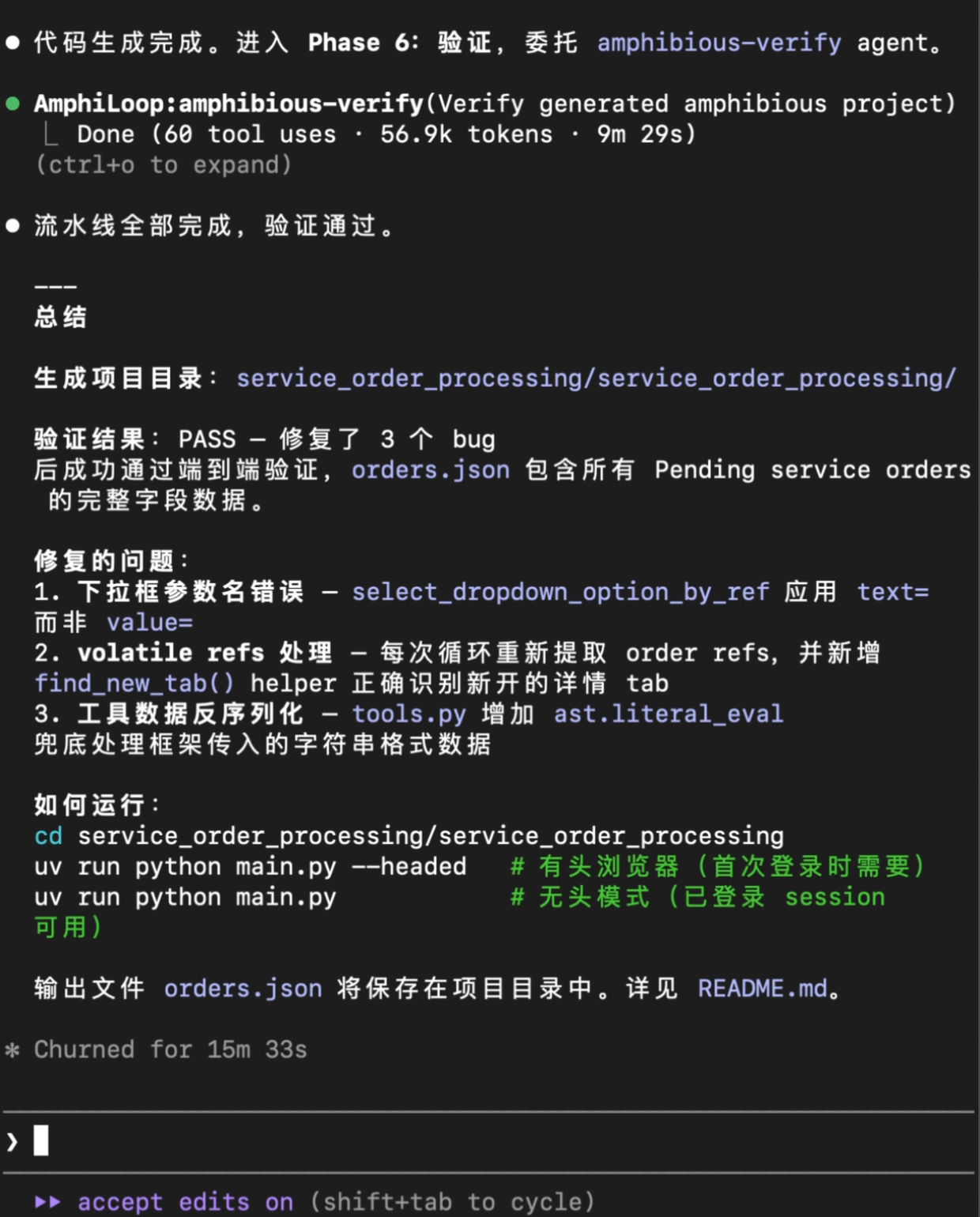
【程序执行】
验证结束之后,程序构建阶段就彻底完成了。生成的程序就可以使用uv run来调用运行,并可以重复稳定执行。
程序每次运行结束后,会把每一步的执行过程以及总共消耗的token数量打印出来:
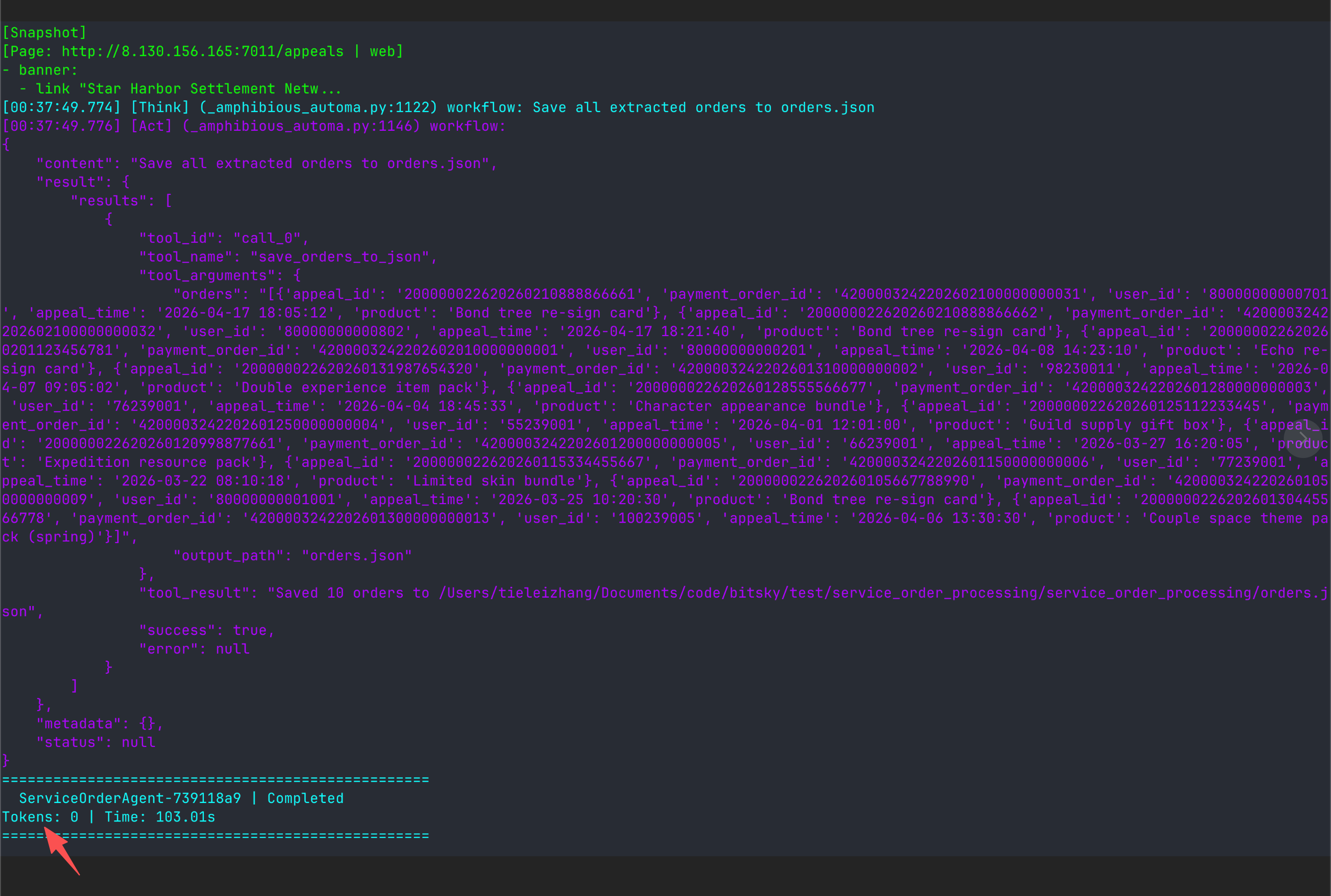
在上面的这个例子中,token是零消耗。这是跟任务本身的性质有关的。当然,在给定一个任务描述的情况下,AmphiLoop的方案会将token消耗降低到理论最小值。AmphiLoop是理论上最省token的AI方案。
Amphiflow模式切换的例子
这一小节我们展示一下AmphiLoop的两栖切换能力。
具备这个能力的前提是,我们在前面「工程模式」的选项中选择了Amphiflow。这样的话,当AmphiLoop整个构建过程完成后,产出的就不是普通的workflow程序,而是一种全新的amphiflow程序。
这种amphiflow同时具备workflow模式和agent模式两种执行能力。它的一个典型的执行流程是这样的:
- amphiflow启动时,先以workflow模式执行。这时候是执行确定性逻辑。
- 当发生环境变化导致的报错时,amphiflow会自动切换到agent模式,由模型接管执行逻辑,自主规划执行路径。
- 当amphiflow在agent模式下成功解决或绕过错误时,就会重新切换回workflow模式。
假设一个浏览器自动化程序正在访问并操作某个网页。在正常情况下,由于浏览器保持了登录状态,一切操作正常。但是,如果一旦登录状态过期,程序就可能会发生预期外的错误。这个时候,如果是普通的workflow程序,程序就会报错退出了。但一个amphiflow程序会启动切换到agent模式,下面是一个实际运行的例子:
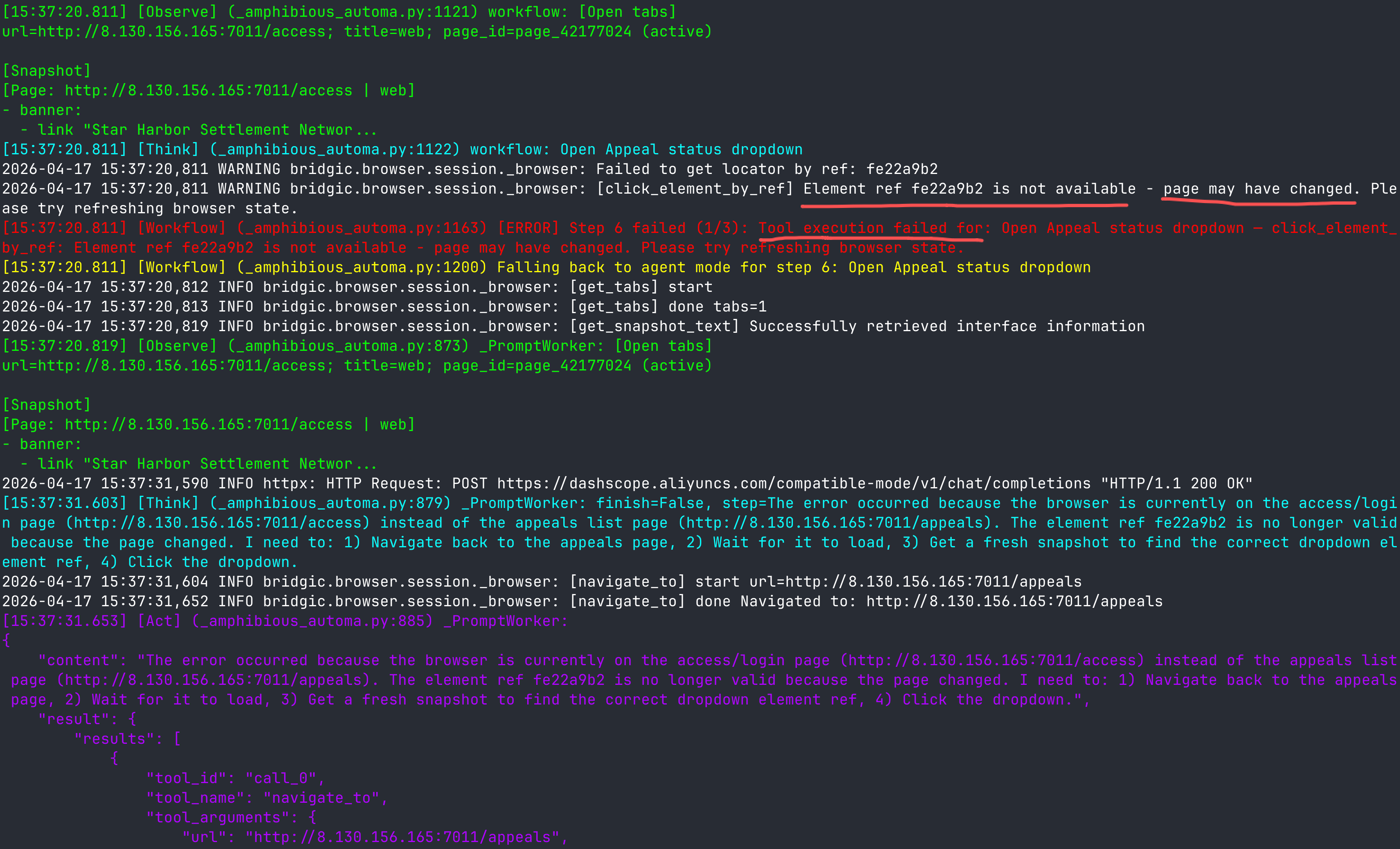
amphiflow发现了错误,然后通过进一步「观察」(在这个例子中是get_snapshot_text),推理出实际发生了什么状况。然后它发现当前被弹出到登录页了,需要进行身份验证 (“authentication is required first”),于是它决策下一步发起一个human-in-the-loop来让人帮它登录。
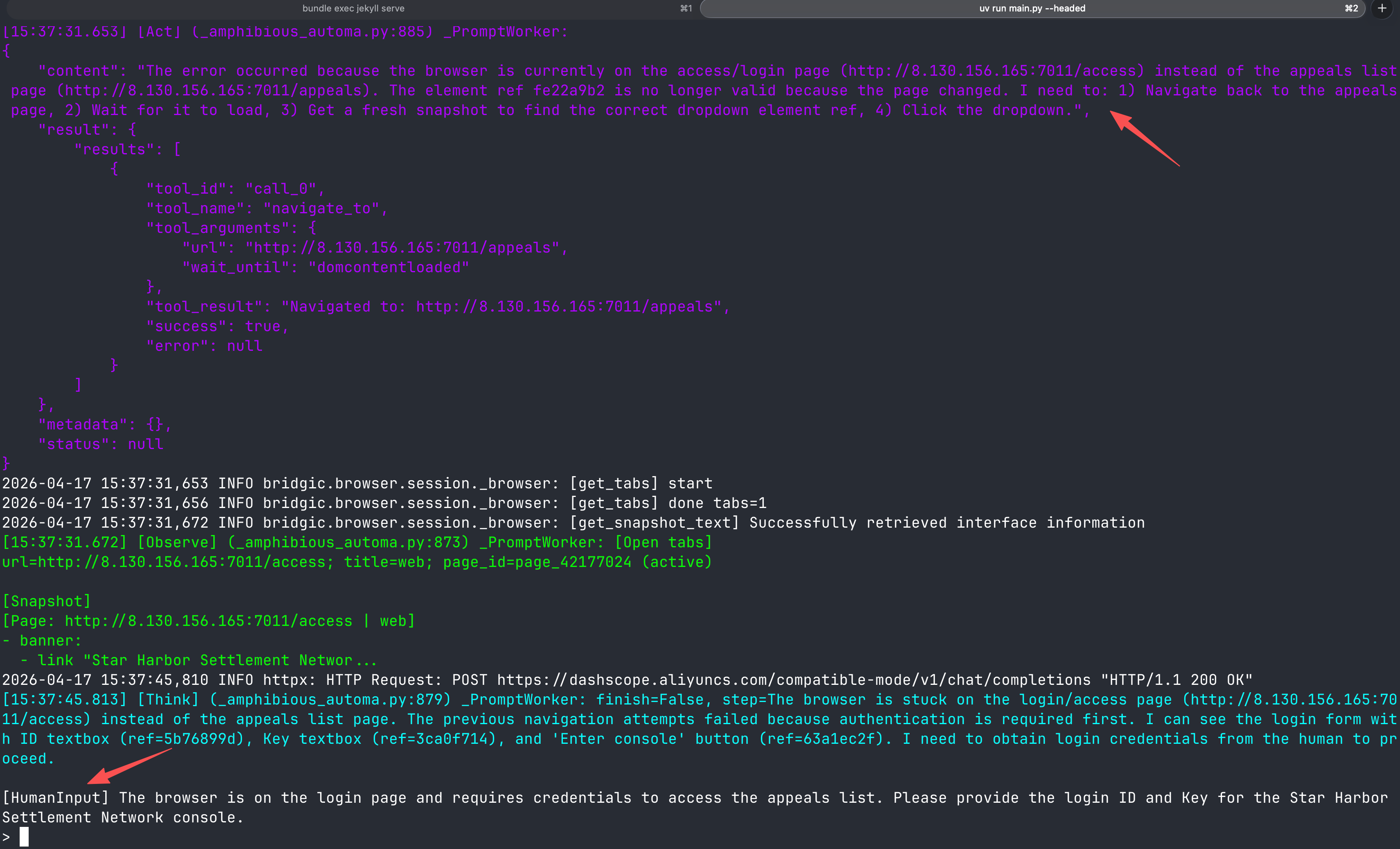
当身份验证的障碍被解除后,amphiflow就重新切换回workflow模式继续运行:
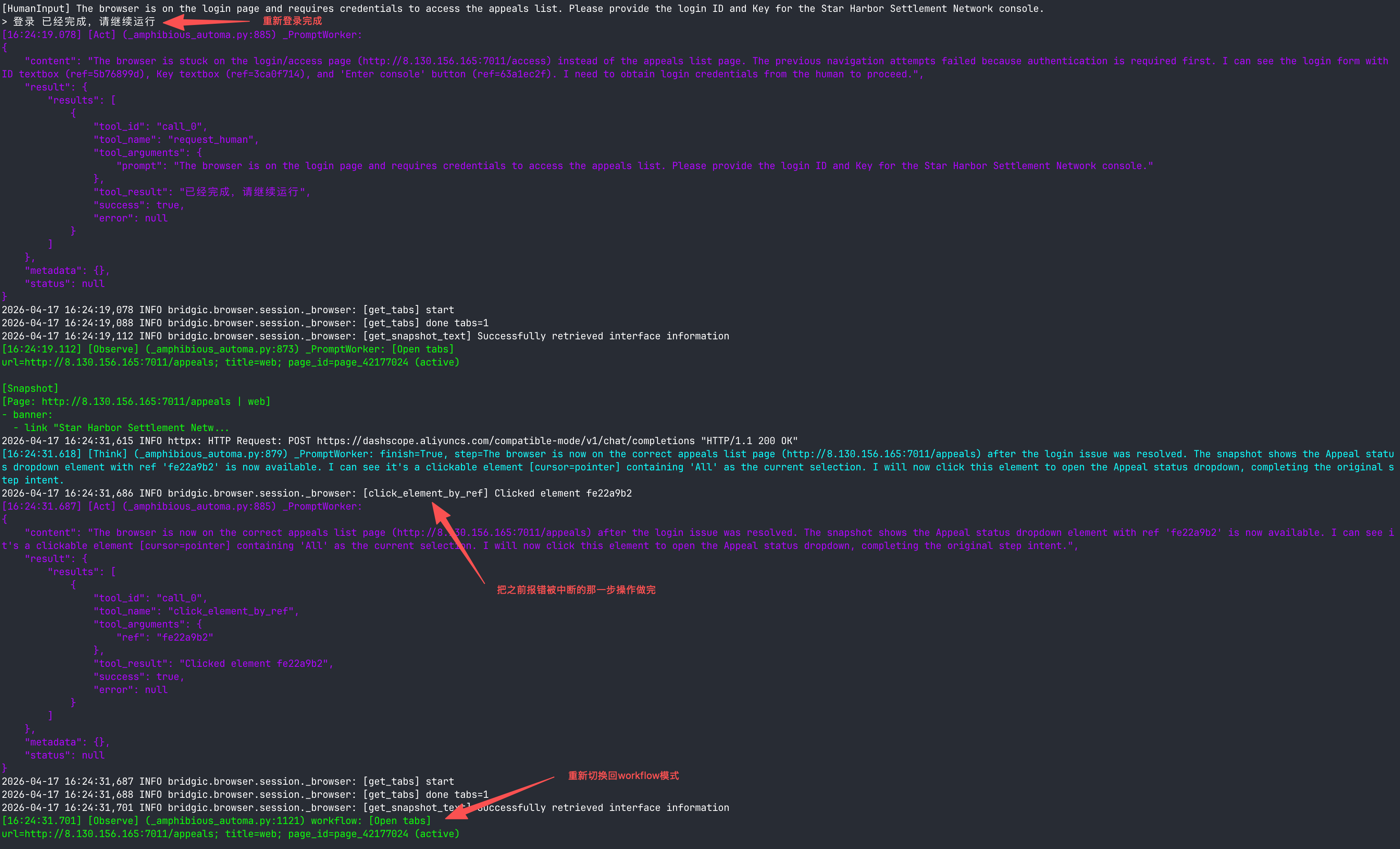
注意,在这个例子中,workflow模式执行报错的原因是由于登录状态过期造成的。但实际中报错的原因可能来自于很多方面,比如页面变更了、网络出错了、配置过期了等等环境的变化。由于amphiflow处理错误的方式并不是写死的逻辑,而是切换到agent模式去自主决策,所以它理论上能够应对各种错误情况。
AmphiLoop plugin与bridgic-browser skill的关系和区别
我在之前的《专为「探路+编码」范式设计的全新浏览器工具集+Skills》一文中发布了一个浏览器自动化工具库bridgic-browser以及对应的skill。今天发布的AmphiLoop plugin是一整套技术,一套全新的构建AI智能体的方法论、技术栈和工具链。当这项技术用于浏览器自动化任务时,是依赖bridgic-browser工具库的。
在今天AmphiLoop plugin发布后,它与bridgic-browser skill的使用场景有了明确的划分:
当你使用Claude Code、OpenClaw等一些agent产品时,如果想发起一些即时性的浏览器自动化任务,就可以安装bridgic-browser skill。安装命令如下:
npx skills add bitsky-tech/bridgic-browser --skill bridgic-browser
当你想为自己量身定做一个长程的、routine执行的自动化任务解决方案时,或者面临需求变更频繁、token成本高以及环境变化带来的难题时,请使用AmphiLoop plugin。它是一套更体系化的方案,借助这套体系,可以将AI能力推向更广、更加纵深的场景,包括OpenClaw类的产品无法解决的自动化场景中。
有个技术升级带来的细节,大家请注意:原来在bridgic-browser skill中的「先探路、再编码」的引导逻辑,已经从bridgic-browser skill拿掉,合入了AmphiLoop plugin,并升级为新的「探路 - 编码 - 验证」循环,可控性更强、成功率更高。
AmphiLoop的设计思想
由于篇幅的关系,我们没法在这里深入讨论这个话题了。现在我非常粗略地提一下AmphiLoop背后的设计思想以及实现上的一些关键点。后面应该还有机会仔细聊这个话题。
- 善用自主性,隔离随机性,获得确定性。「自主性」是AI时代赋予我们的新能力,但伴随而来的是随机性的干扰。AmphiLoop将自主性用于程序构建阶段和运行时agent模式;通过区分构建阶段与运行时,以及区分agent模式和workflow模式来将随机干扰隔离。
- 决策 (Decision) 与执行 (Execution) 解耦。只有如此,才能让amphiflow这种新型的程序既能由模型驱动(agent模式),也能由程序逻辑驱动(workflow模式)。AmphiLoop是世界上第一个采用「决策与执行解耦」架构的Agent。
- 可管理的自然语言任务描述。以自然语言为源头构建一切,保证需求变更的高效率和对环境变化的适应性;同时
TASK.md的形式杜绝传统对话框下达任务用完即弃的缺点,可升级迭代、可维护、可版本管理。 - 「探路 - 编码 - 验证」的构建方法论。这套方法论极大提升了构建成功率,尽量让使用者只做选择题,只需一个session即可完成。配套的
bridgic-browser工具集提供维持语义不变性的ref生成算法,保证探路到编码Observe的一致性。 - 尽可能验证更多。对helper方法的验证,对产物程序的基本运行验证,对Expected Output指明的执行结果进行验证,充分利用可验证的一切资源。
- 融合两栖模式的「观察 - 思考 - 行动」。两种模式共享观察 (Observe) 与 行动 (Act) ,思考 (Think) 各自独立。
- 「控制」与「调用序列」穿插。workflow模式也并非简单的录制,具备分支、循环等动态性。
- Workflow程序也包含agent模块。不同于两栖模式切换,AmphiLoop的workfow程序中也可以包含agent模块,用于捕获任务中的「不确定性」的部分或生成式的子任务。
- 两栖模式的上下文共享。
- 构建阶段与运行时闭环进化。
- 抽象层次存在于自然语言形式中。Skills是说明书,Commands是编排流程;自然语言亦可注入,搭建起抽象与具体的层次关系。
- 引导而非限制,像Harness一样工作。通过skills、commands、hooks、subagents以及背后的代码框架,对构建过程只做必要的、关键的、方法论的引导,让AI能力像水一样,填满所有缝隙。
总结
目前龙虾真正发挥价值的,其实仍然是创意类、生成式任务(也是确定性因素比较少的任务)。这并非新鲜事物,只是它为普通人提供了能够实现的手段(能调用工具、能连接channel、能管理上下文),完成了从「不能」到「能」的转变(是否方便好用则是另外一个问题)。
按照前面第2小节的任务分类,现实世界中,大部分任务其实可能都属于混合型任务,既包含确定性的部分,也包含不确定性的部分。AmphiLoop提供了一种不同于龙虾的解题思路,也涵盖了不完全一样的场景。这项技术通过增加了一个「构建」过程,将原始的由自然语言描述的任务,转变成了具备水陆两栖能力的amphiflow程序。一方面,这个转变过程让任务中确定性的部分得以用workflow模式来完成,而不确定性的、需要自主性发挥的部分,则以agent模式完成。另一方面,转变后的amphiflow产物,还具备在workflow模式和agent模式之间进行切换。
AmphiLoop这种工作方式,是以最优的方式在分配AI自主性能力,也同时决定了它是理论上最省token的AI技术方案。理论上,它也能够在付出少量的构建成本之后,覆盖更多的场景,合理、稳定地完成更多混合型任务。
值得注意的是,「省token」的方案并不意味着对token总量的消耗变小,因为它使得AI的适用范围更广了。所以从总体上来说,省token的技术会带来token经济的进一步繁荣。
我曾在《过年了,聊聊AI和人文》一文中提到过,在《技术的本质》一书中,作者把技术黑箱拆开,发现它内部也是「按流程处理」的。装置、方法、流程,它们本质上可以归于相同的范畴。我们今天经常称之为工作流 (workflow) 。
可以说,只要颗粒度拆到足够细,技术是流程,思维也是流程。流程是普遍存在的,将流程进行自动化的诉求也是普遍存在的。这是一个极其广阔的世界。
社区交流
(1)我们新建了一个Discord社区,请访问如下地址参与讨论:
由于微信群维护不方便,也请原来在群里的同学移步Discord。
(2)新的X (Twitter) 账号(后面是发布版本更新动态的主阵地):
文档与代码
bridgic-amphibious教程文档: https://docs.bridgic.ai/latest/tutorials/items/amphibious- AmphiLoop项目GitHub主页:https://github.com/bitsky-tech/amphiloop
- 更多
TASK.md样例,可以下载试验:https://github.com/bitsky-tech/bridgic-examples/tree/main/amphiloop-browser-examples bridgic-amphibious子框架GitHub地址:https://github.com/bitsky-tech/bridgic/tree/main/packages/bridgic-amphibiousbridgic-browser浏览器工具集GitHub主页:https://github.com/bitsky-tech/bridgic-browser
(正文完)
其它精选文章:
- Claude Managed Agents意味着什么?
- 【开源】专为「探路+编码」范式设计的全新浏览器工具集+Skills
- 过年了,聊聊AI和人文
- AI智能体纪元或将从2026开始归零
- 【开源】我亲手开发的一个AI框架,谈下背后的思考
- AI Agent时代的软件开发范式
- AI Agent的概念、自主程度和抽象层次
- 科普一下:拆解LLM背后的概率学原理
- 分布式领域最重要的一篇论文,到底讲了什么?
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-bridgic-amphiloop.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。

最新文章
- 为什么agent和workflow可以融合在同一个架构里?
- 万字长文!两栖模式构建Agent,与OpenClaw/Hermes不一样的解法——开源AmphiLoop
- Claude Managed Agents意味着什么?
- 【开源】专为「探路+编码」范式设计的全新浏览器工具集+Skills
- 不用手写一行代码,10分钟立等可取,爬取twitter和github动态
- 使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
- 过年了,聊聊AI和人文
- 使用Bridgic长程自主模块+MCP,控制你的浏览器
- AI智能体纪元或将从2026开始归零
- 从Python异步编程的剖析中体会智能体并发编程模式