从Python异步编程的剖析中体会智能体并发编程模式
2025-12-21
今天我们讨论一个跟Python异步编程有关的问题。问题源于我们在开发Bridgic项目时碰到的一个基础编程问题:被调度执行的agent应该运行在一个什么样的线程环境上?
这个问题如此基础,甚至可能是开发任何一个复杂系统时第一步就应该被考虑的问题。智能体的调度执行,为这个问题的讨论提供了一个绝佳的场景,对于我们构建其他系统也具有重要的参考意义。
本文围绕以下四部分内容展开:
- 并发 (concurrency) 和并行 (parallelism) 的区别。
- 典型的任务类型:I/O-bound和CPU-bound,以及GIL的影响。
- Bridgic的并发模式 (Concurrency Mode) 设计思路。
- 并发模式对Bridgic框架层实现的影响。
💾 Bridgic:一个支持动态拓扑的AI智能体框架:
点击这里下载源码 ➜ https://github.com/bitsky-tech/bridgic
并发与并行的区别
我们的讨论以Bridgic的编程场景作为起点。Bridgic是一个agent框架,它需要调度多个agent同时运行。于是,就在两个层面上产生了并发执行的需求:
- 第一,同一个agent内部的并发分支之间需要并发。在一个agent内部,可能编排出并发的执行分支,比如动态子任务拆分,或者并发调用工具。处于不同并发分支上的worker,它们的执行不应该相互阻塞,否则并发分支本身就没有存在的意义了。
- 第二,不同agent之间的执行需要并发。整个系统需要同时处理多个agent的调度运行,因此任何一个agent的执行都不应该阻塞其他agent的执行。
另一方面,计算机系统对于并发执行能力的支持,也分成了两个层面:
- 第一个层面是concurrency,中文翻译过来是「并发」。它指的是一个系统可以同时处理多个任务,多个任务之间可以穿插执行,分时复用。但任一时刻,系统仍然只需要处理一个任务。
- 第二个层面是parallelism,一般中文翻译为「并行」。它指的是一个系统可以在同一时刻同时执行多个任务。
好,从现在开始,为了表达上的准确、无歧义,我们就用「并发」来表示concurrency,用「并行」来表示parallelism。这两者可以用一个比喻来形象地区分:
- 并发,相当于一个厨师同时炒多盘菜。干活儿的只有一个人,他得兼顾多个炒锅。
- 并行,相当于多个厨师同时炒多盘菜。干活儿的人多了,他们就可以各干各的,真正地互不影响。按照《技术变迁中的变与不变:如何更快地生成token?》一文中对系统建模的概念,多个厨师就相当于多个服务通道。
由于「一个厨师」是「多个厨师」的特例,所以一般来说,如果我们说一个系统是并行的,那么也意味着它是并发的。但反过来就显然不成立。
现在问题来了,前面对于调度多个agent并发执行的需求(包含agent内部和agent之间两个层面),是只需要系统具备并发能力就够了呢?还是必须提供并行能力?
要准确回答这个问题,需要进一步分析被调度的任务的性质。我们下一小节展开。
I/O-bound和CPU-bound,以及GIL的影响
按照软件编程的术语(不仅限于Python世界),软件任务通常会被分成两个典型的类型:
- I/O-bound task:大部分时间都在等待输入输出的任务。这类任务占用CPU资源非常少。在它等待I/O的过程中,CPU是空闲的。
- CPU-bound task:大部分时间都在执行某种计算的任务,也就是计算密集型的任务。这类任务对CPU资源的消耗非常大。
通常来说,在互联网业务场景下,I/O-bound task是更常见的。这些任务需要等待的I/O操作一般是指网络请求。而CPU-bound task的常见例子则包括:机器学习训练任务、数学计算任务、数据处理任务、图片/视频处理任务、加密/解密任务等等。
有人可能会说,把软件任务分成I/O-bound task和CPU-bound task两类,似乎不太符合MECE[1]原则(相互独立,完全穷尽)。至少应该还有第三类任务,它们既不消耗大量CPU,也没有长时间等待的I/O操作。严格来说,确实如此。但这类任务由于资源消耗很小,所以对系统的并发执行能力没有什么特殊的要求,在讨论中也就无足轻重。
但是,I/O-bound task这一类任务却是需要进一步分类的。它分成两类:
- Blocking I/O task:也称为synchronous I/O task,指的是这类任务内部调用了同步的I/O操作,会阻塞住调用它的线程。在实际中这种情况是可能发生的,比如你引用了一些老的代码库,而这些代码库不支持异步I/O。
- Non-Blocking I/O task:也称为asynchronous I/O task,指的是这些任务内部只调用了异步的I/O操作,因此原则上不会阻塞住调用线程。在Python的语境下,异步I/O很可能是基于asyncio实现出来的。因此,non-blocking I/O task中的大部分都应该是asyncio-aware的。至于剩下的少部分不是用asyncio实现出来的,但确实又是non-blocking的任务,并不是主流。对于这类任务的处理涉及到一些细节,但根据blog文章“Python Asyncio Part 5 – Mixing Synchronous and Asynchronous Code”[2]在“Using non-blocking IO and periodic polling”这一小节给出的方法,这类任务其实可以很快封装成一个asyncio-aware task。这其中涉及到的细节不是本文的重点,所以这里略过不展开讨论。感兴趣的读者可以参考文末的链接。
总之,根据我们当前关注的重点(对并发执行能力的要求),软件任务可以像下面这样分类:
- I/O-bound task,又分为:
- asyncio-aware task。
- Blocking I/O task;
- CPU-bound task。
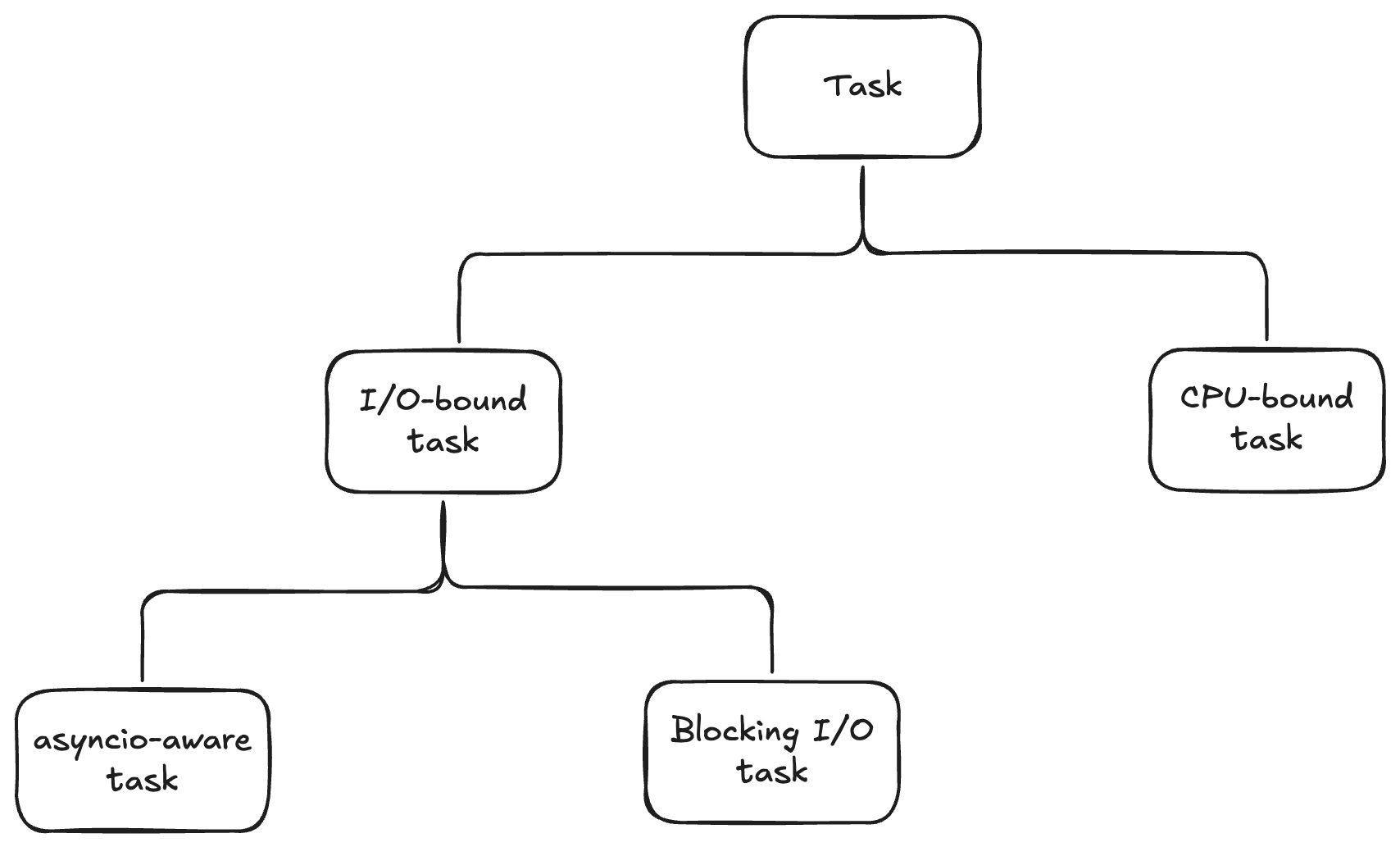
现在我们可以逐个分析一下这几类任务了。
首先,对于asyncio-aware task,自然是使用asyncio[3]来实现并发能力最合适。asyncio是Python的标准库,它提供了使用async/await语法来编写并发代码的能力。asyncio背后的思想是使用event loop和协程 (coroutine) 。
话说起来,event loop是由来已久的一项技术了,属于异步编程的一种实现方式,允许多个task在单线程上分时复用CPU资源。最开始这种技术在客户端(iOS、Android)或web前端编程中使用较多。因为是异步编程,所以早期一般需要通过注册callback来获取任务执行结果,编程方式繁琐,在时序上的要求也高,存在比较高的编程门槛和维护门槛。但是,一些现代语言,比如Python、JavaScript,在配合了协程的技术和async/await语法之后,基本消除了callback,让开发者可以使用类似同步编程的方式来实现异步执行,大大降低了使用门槛。
但从根本上来说,asyncio是在单一线程上以协程为粒度复用CPU资源的一项技术,它不会利用CPU多核的计算能力。又由于asyncio-aware task属于I/O-bound task,这类任务对于CPU的计算资源要求很低,所以使用一个线程就足以处理大量协程。这也是为什么event loop技术得以在服务端编程中被使用的原因:大量任务运行在单线程上,但它们大部分时间都在等待I/O操作(处理网络请求),即使合起来对于CPU资源的消耗也不是瓶颈。Redis就是一个很好的服务端的例子,主要使用一个线程来同时处理大量请求(详情可以参见我之前的文章)。
而对于Blocking I/O task来说,情况就不同了。虽然这类任务对CPU资源消耗也不大,但是它等待I/O的操作是个同步操作,因此会阻塞住调用线程。如果仍然使用单线程event loop的方式来执行此类任务,那么就会把这唯一的一个线程阻塞住,导致其他任务也没法执行。因此,执行Blocking I/O task就需要多线程[4]。
再看一下CPU-bound task。理论上来说,这类任务使用多线程来执行本来是可以的。但是,在Python环境下,由于GIL (Global Interpreter Lock) 的存在,Python对于多线程的实现有一个重要的限制[4]:
In CPython, due to the Global Interpreter Lock, only one thread can execute Python code at once (even though certain performance-oriented libraries might overcome this limitation).
译文:在CPython中,由于存在全局解释器锁,因此同一时刻只有一个线程能够执行Python代码(尽管某些注重性能的库能够克服这一限制)。
这一限制导致,使用Python的多线程来执行CPU-bound task并不是最佳选择。
除了以上限制,Python的多线程还涉及到一些关键的细节:
- 多个线程的执行,是可以在指令级别进行切换的。但由于GIL的影响,同一个进程内同一时刻只能有一个线程在运行,所以多个线程之间仍然只是分时复用。按照上一小节的概念,这属于并发的范畴而非真正的并行(对应只有一个厨师干活儿的情境)。正是因为如此,在Python中使用多线程执行CPU-bound task,不同的任务之间就会争抢CPU,结果就是运行速度变慢。
- Python从3.14版本开始支持free threading[5](需要是特殊的free-threading build版本)。这是一种全新的多线程机制,前面GIL带来的限制就不存在了,Python多线程从此可以实现真正的并行执行。不过目前这个版本在生产环境还没有被大量使用,因此我们在后面的讨论中先不考虑它。
- 大部分I/O操作(包括文件读写、网络数据收发)都是通过调用native代码实现的,并且会主动释放GIL锁[2]。这意味着,当一个线程执行阻塞式I/O操作的时候,它不会阻塞住同一个进程内的其他线程执行(虽然当前线程会被阻塞住)。正是因为这个原因,虽然在一个Python进程内同一时刻只能有一个线程在运行,且一个线程调用一个blocking I/O会阻塞住当前线程,但使用多线程执行Blocking I/O task一般却是没问题的,这些task之间不会相互阻塞。
那么,执行CPU-bound task怎么办呢?目前我们认为,在Python中需要使用多进程机制[6]。
现在小结一下:
- 在不考虑Python高版本free threading的情况下,Python中的asyncio和多线程,这两个机制都只能提供并发执行的能力,代码执行只是分时复用。不同的是,asyncio对于CPU资源的复用粒度是协程,而多线程之间复用CPU资源的粒度是指令。
- Python中的多进程机制才提供真正的并行执行能力。
那么,在Python环境下,对于前面典型的几种任务类型来说:
- asyncio-aware task,应该使用asyncio来实现并发。
- Blocking I/O task,一般使用多线程来实现并发。
- CPU-bound task,应该使用多进程来实现真正的并行。
Bridgic的并发模式设计思路
好,现在我们来具体看一下Bridgic中的并发模式 (Concurrency Mode) 设计。
首先,Bridgic是一个以异步编程为基础的框架。也就是说,它对于worker的调度执行,是基于asyncio的,框架本身的调度逻辑运行在主线程的event loop里面。通过前面的分析,我们知道,asyncio对于asyncio-aware task是天然具备并发执行能力的。但是,对于Blocking I/O task和CPU-bound task来说,这个并发能力是不够的,理论上应该由多线程和多进程来提供。
截止目前,Bridgic支持两种对于worker的运行模式,一种是异步的,一种是同步的。对应的,Biridgic的Worker类定义了两个入口方法:
class Worker(Serializable):
async def arun(self, *args: Tuple[Any, ...], **kwargs: Dict[str, Any]) -> Any:
...
def run(self, *args: Tuple[Any, ...], **kwargs: Dict[str, Any]) -> Any:
...
如果被调度的Worker子类实现了arun异步方法,那么Bridgic就会使用asyncio的方式 (await) 来调用它;相反,如果被调度的Worker子类实现了run同步方法,那么Bridgic就会使用多线程的方式(借助asyncio的event loop提供的run_in_executor方法)来调用它。注意:限于开发上的优先级排序,Bridgic目前还没有支持多进程的调用方式。
根据之前的文章介绍,Bridgic将智能体世界的万事万物都归结到了两个核心概念之上,一个叫worker,一个叫automa。其中worker这个概念就是前面定义的Worker类。不管worker的表现形式如何,比如可能是个可执行的function,也可能是个MCP表达的工具,它最终都会归结到Worker的子类上。
举个例子(由ASL表达):
async def worker_0():
return ...
def worker_1(r0):
return ...
def worker_2(r0):
return ...
async def summary(r1, r2):
return ...
class MyWorkflow(ASLAutoma):
with graph as g:
w0 = worker_0
w1 = worker_1
w2 = worker_2
s = summary
+w0 >> ( w1 & w2 ) >> ~s
使用async def定义的worker,最终会由Worker子类的arun来驱动;使用def定义的worker,最终会由Worker子类的run来驱动。因此,上述代码执行时:
worker_0会先在主线程上以异步方式执行。- 然后
worker_1和worker_2会在新的线程上以同步方式并发执行。 - 最后在
summary执行时再回到主线程异步执行。
结合前面两个小节讨论的一些结论,可能反过来问一个问题,对于agent的开发者会更有指导意义:在实现worker时候,什么时候应该用async def,什么时候应该用def(前者对应Worker.arun,后者对应Worker.run)?
- 对于asyncio-aware task,应该使用
async def。 - 对于Blocking I/O task,应该使用
def。 - 对于CPU-bound task,当前也应该使用
def。这虽然不是真正的并行执行,但还是能够实现多个task分时复用,不至于完全阻塞住。未来可能会基于free threading或者多进程来提供真正的并行能力。
小节一下:Bridgic调度器的「底色」是基于asyncio的event loop的。框架本身的调度逻辑都是运行在主线程的event loop里,然后一个节拍一个节拍地去执行worker。在执行具体某个worker的时候,根据worker的定义方式(最终归结为Worker的arun还是run)来决定是使用asyncio来执行,还是使用多线程来执行。
并发模式对Bridgic框架层实现的影响
就像本文开头所讲,并发模式或线程执行环境是一个基础的编程问题,所以关于它的设计会影响到Bridgic框架的很多方面。最显著的一个影响在于:在worker的同步执行环境(Worker的run,或者def`定义的function)中,框架提供的异步API如何暴露?
举个例子,Automa类有一个API,叫request_feedback_async。它是个异步的function,用于实现第一种human-in-the-loop方案(具体参见文章《一文讲透AI Agent开发中的human-in-the-loop》)。这个API的函数签名如下:
async def request_feedback_async(
self,
event: Event,
timeout: Optional[float] = None
) -> Feedback:
...
显然,这个函数在同步的执行环境中是不能调用的。那么,我们就需要为它准备一个同步的API版本:
def request_feedback(
self,
event: Event,
timeout: Optional[float] = None
) -> Feedback:
...
假设我们现在要实现两个worker,代码例子如下:
async def worker_0():
...
feedback = await self.request_feedback_async(event)
return feedback.data
def worker_1(r0):
...
feedback = self.request_feedback(event)
return feedback.data
class MyWorkflow(ASLAutoma):
with graph as g:
w0 = worker_0
w1 = worker_1
+w0 >> ~w1
在以上这段代码示例中,worker_0是异步的,它在Bridgic的主线程中执行,所以调用request_feedback_async;worker_1是同步的,它在单独的线程中执行,所以调用request_feedback(无需再使用await)。
由于在异步环境中既可以调用异步方法,也可以调用同步方法,而在同步环境中只能调用同步方法,所以只有worker和automa的异步API才需要维护两个版本。相反,同步的API,比如ferry_to、add_worker、post_event等等,都只需要维护一个版本即可,基本上不受并发模式的影响。
而对于类似request_feedback_async这样的异步API,如何提供它的同步版本呢?显然,如果有一个快速适配、低成本的方案是最好的。幸运的是,在Bridgic的架构设计中,这样的方法是存在的!这是因为,前面我们说过,Bridgic调度器的「底色」是基于asyncio的event loop,在这个基础上,并发模式只是伸展出去的枝叶。所以,其实request_feedback内部的实现是通过简单封装request_feedback_async来实现的。具体实现代码很短,如下:
def request_feedback(
self,
event: Event,
timeout: Optional[float] = None
) -> Feedback:
if threading.get_ident() == self._main_thread_id:
raise AutomaRuntimeError(
f"`request_feedback` should only be called in a different thread from the main thread of the {self.name}. "
)
return asyncio.run_coroutine_threadsafe(
self.request_feedback_async(event, timeout),
self._main_loop
).result()
总之,并发执行环境是一个agent框架重要的非功能性需求之一。所有这些细节,再加上可观测性、human-in-the-loop、序列化与反序列化等能力,都已经由框架提供好了,agent开发者无需再为这些基础性问题伤透脑筋。这也是开发agent之所以需要使用框架的一个原因。
源码下载
Bridgic源码地址 ➜ https://github.com/bitsky-tech/bridgic
Automa类的实现代码(内含request_feedback的实现) ➜ https://github.com/bitsky-tech/bridgic/blob/main/packages/bridgic-core/bridgic/core/automa/_automa.py
Bridgic文档地址 ➜ https://docs.bridgic.ai/
ASL教程地址 ➜ https://docs.bridgic.ai/latest/tutorials/items/asl/quick_start/
加入技术交流群
我建了一个“Bridgic开源技术交流群”,后面会在群里发布项目的开发进展及计划,并讨论相关技术。感兴趣的朋友可以扫描下面的二维码进群。如果二维码过期,请加微信ID: zhtielei,备注“来自Bridgic社区”。

(正文完)
参考文献:
- [1] From Wikipedia. MECE principle.
- [2] James Weaver. Python Asyncio Part 5 – Mixing Synchronous and Asynchronous Code.
- [3] Python Documentation. asyncio — Asynchronous I/O.
- [4] Python Documentation. threading — Thread-based parallelism.
- [5] Python Documentation. Python support for free threading.
- [6] Python Documentation. multiprocessing — Process-based parallelism.
其它精选文章:
- 基于动态拓扑的Agent编排,原理解析+源码下载
- 【开源】智能体编程语言ASL——重构智能体开发体验
- 【开源】我亲手开发的一个AI框架,谈下背后的思考
- 一文讲透AI Agent开发中的human-in-the-loop
- AI Agent时代的软件开发范式
- AI Agent的概念、自主程度和抽象层次
- 技术变迁中的变与不变:如何更快地生成token?
- 科普一下:拆解LLM背后的概率学原理
- 分布式领域最重要的一篇论文,到底讲了什么?
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-bridgic-concurrency-mode.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。

最新文章
- 为什么agent和workflow可以融合在同一个架构里?
- 万字长文!两栖模式构建Agent,与OpenClaw/Hermes不一样的解法——开源AmphiLoop
- Claude Managed Agents意味着什么?
- 【开源】专为「探路+编码」范式设计的全新浏览器工具集+Skills
- 不用手写一行代码,10分钟立等可取,爬取twitter和github动态
- 使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
- 过年了,聊聊AI和人文
- 使用Bridgic长程自主模块+MCP,控制你的浏览器
- AI智能体纪元或将从2026开始归零
- 从Python异步编程的剖析中体会智能体并发编程模式