谈谈智能体开发和可观测性
2025-12-01
今天,我以开源Bridgic 的链路追踪集成 (tracing) 为例,聊一聊AI时代的可观测性 (Observability) 相关的话题。
本文分成三个部分:
- 回顾一下传统的可观测性技术。
- 讨论一下AI时代的可观测性。
- 以Bridgic的tracing集成为例,从微观上看一下如何对workflow和agent进行链路追踪(包括如何完成嵌套式的链路追踪)。
💾 Bridgic:一个支持动态拓扑的AI智能体框架:
点击这里下载源码 ➜ https://github.com/bitsky-tech/bridgic
传统的可观测性
可观测性技术由来已久。自从分布式的互联网技术架构发展起来并成为主流,可观测性技术也经历了多次迭代,目前已经非常完善和成熟。一般认为,可观测性又分为三个更具体的方向[1]:事件日志 (logging) 、链路追踪 (tracing) 和聚合度量 (metrics) 。
- 事件日志 (logging):俗称「打日志」,是程序员最基础的调试手段。值得一提的是,当今开发智能体程序的时候,很多工程师经常使用的手段仍然是「打日志」,至少在项目初期是这样的。当打印的日志越来越多的时候,工程师们会选择将同一类型的日志打印到同一个文件中,方便查阅。当然了,如果系统演变成一个复杂的分布式系统,那么就会使用Elastic的技术栈,或者将不同节点的日志采集后通过Kafka等中间件汇聚到数据湖当中。
- 链路追踪 (tracing):追踪单请求的链路调用信息。在典型的互联网系统架构中,链路追踪一般指的是分布式链路追踪,用于追踪一个请求内对于多个后端微服务的调用情况。现代分布式链路追踪公认的起源是Google在2010年发表的论文《Dapper : a Large-Scale Distributed Systems Tracing Infrastructure》[2],该论文提到,链路追踪的目的主要是两个:理解系统行为和解决性能问题。如果用于调试目的,相比「打日志」的方式,链路追踪的一个明显优势是,它会将一个请求内部的所有调用使用同一个
trace id串起来。相对于在充斥了各种日志的文件中用肉眼搜寻同一个请求的信息,这通常要高效得多。 - 聚合度量 (metrics):在Peter Bourgon的经典博客“Metrics, tracing, and logging”一文中[3],作者举了这么几个关于metrics的例子:当前队列长度、HTTP请求数量、请求持续时间的分布。需要注意的是,metrics与前两者的关系:metrics可能由logging提供的日志聚合出来,也可能由tracing提供的信息聚合出来,也可能都不是。
文本接下来的侧重点会放在链路追踪 (tracing) 上面。
为了便于后面的讨论,我们稍微复习一下链路追踪中的几个基础概念。见下图(出自谷歌的论文[2]):
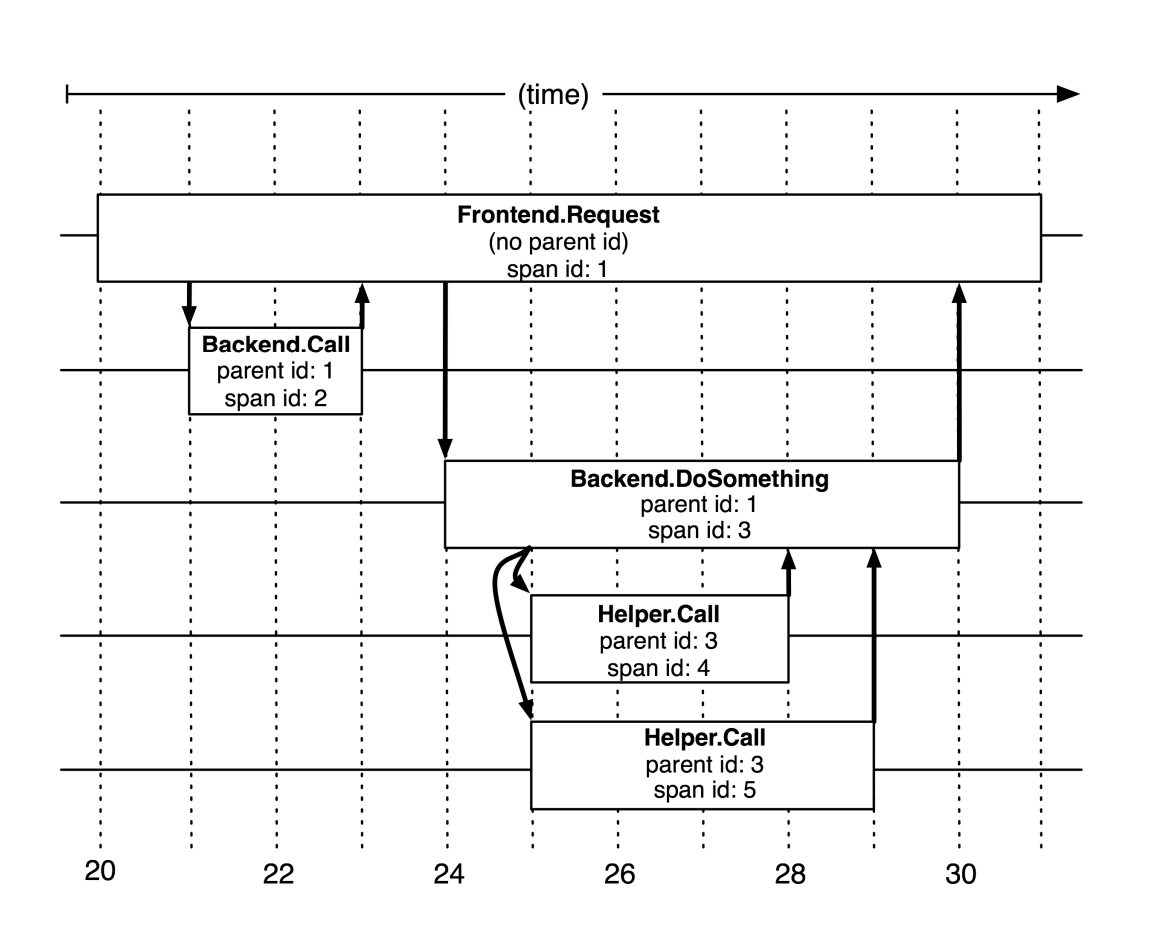
- 第一个基础概念是span(跨度)。一次请求中,每次服务调用会产生一个span。服务调用开始,span开始;服务调用结束,span结束。被调用的服务,还很可能调用其他服务,又会产生新的span。
- span之间有父子关系。每个span都会记录引发它的那个上级调用的span是哪个,称为parent span。请求触发的第一个span,没有parent,称为root span(上图中的Frontend Request)。
- Trace Tree:由同一次请求产生的各个span,基于父子关系,会组装出一个trace tree。也就是说,一次追踪 (tracing) ,会产生一个树型的信息结构,也就是trace tree(上图实际就是一棵树)。
AI时代的可观测性
随着LLM技术的发展,市场上已经涌现出一大批专门为智能体系统做可观测性的平台和开源项目。有人说,AI时代的可观测性跟以前不同了,也更重要了,因为LLM带来了非确定性的决策逻辑,系统的行为比以前更难以预测了。这么说当然没有什么大问题。
不过在技术飞速变化的当前,弄清楚什么东西变了,而什么东西没变,还是很重要的一个问题。可观测性的侧重点不同了,但思路和原则并没有发生颠覆性的变化。以前的系统,复杂度集中体现在分布式服务的调用关系上;而在AI智能体开发中,复杂度来源于如何理解智能体内部的自主行为上,也包括多智能体之间的调用关系上。这种复杂度跟分布式没有直接关系,而是跟LLM的生成行为和推理轨迹有关。
我们在集成opik、LangWatch这一类智能体可观测性平台的过程中发现,这些平台一般还是以链路追踪 (tracing) 系统为核心,这跟传统的可观测性系统在本质上是一样的。不同的是,span的概念应该在智能体的追踪中对应什么单元。在以前的可观测性系统中,span一般对应一次微服务的调用;而现在,span可能对应一次LLM调用、一次工具调用、一次subagent的handoff,或者其他关键逻辑的调用。
具体到Bridgic中,基本的执行单元被抽象成了worker,而automa作为编排容器去调度执行worker(这些概念读者可以参见我之前的另一篇文章)。很自然地,当我们每次调用一个worker的时候,就在链路追踪中自动产生一个span。这就是一种最基础的集成方式。
值得注意的是,automa本身作为worker的子类,也可以被嵌入其他automa实例中,从而通过嵌套组合的方式来达到模块化和组件化编程的目的。神奇的是,恰恰是这种概念的抽象,跟一个链路追踪系统的trace tree的概念正好对应上。最终,用一个trace id串起来的整个agentic系统的调用关系,恰好会形成一个多层级的树型结构(下一小节会看到一个具体代码例子)。
大体来看,AI时代的链路追踪,跟传统的链路追踪并没有什么本质的不同。智能体开发的场景,也很容易适配、映射到一个链路追踪系统上。当然,围绕基础的链路追踪能力,opik、LangWatch这一类平台,基本上也会涉及到评测 (evaluation) 、数据集管理 (dataset) 、prompt工程等智能体开发流程中特有的能力。这些才是AI时代可观测性中不同的那些因素(或许已经超出了「可观测性」这一概念的范畴)。另外,在智能体的可观测性度量 (metrics) 方面,对于token成本的监控,也是一个非常重要的能力。
现在,我们来小结一下前面的这些发现:
- 第一,从基础的链路追踪能力上来说,AI时代的可观测性和传统的可观测性并没有本质的区别。在现代的agentic系统的开发中,可观测性的某些方面变得更重要了,但显然不是新旧交替的关系。以前的技术和思路在基础层面上依然有效。
- 第二,为了更好地开发agentic系统,我们还需要更多的基础设施。它们可以提供前面提到的evaluation、dataset、prompt方面的提效工具,也可能是重塑一套行之有效的编程范式。这套范式告诉我们,工具多了怎么筛选,数据多了超出上下文窗口了怎么处理,长时间运行不稳定了怎么办,等等。
实例:Bridgic的trace集成
链路追踪的技术一般都有一个特点:对应用层透明。使用者只需要打开一个开关,所有tracing工作便自动开启了。Bridgic对于opik和LangWatch的集成,也是这样的效果。
下面,我们以两个具体的例子(以LangWatch为例),来展示这部分的效果(文末附代码下载)。
例子1:三层嵌套的workflow
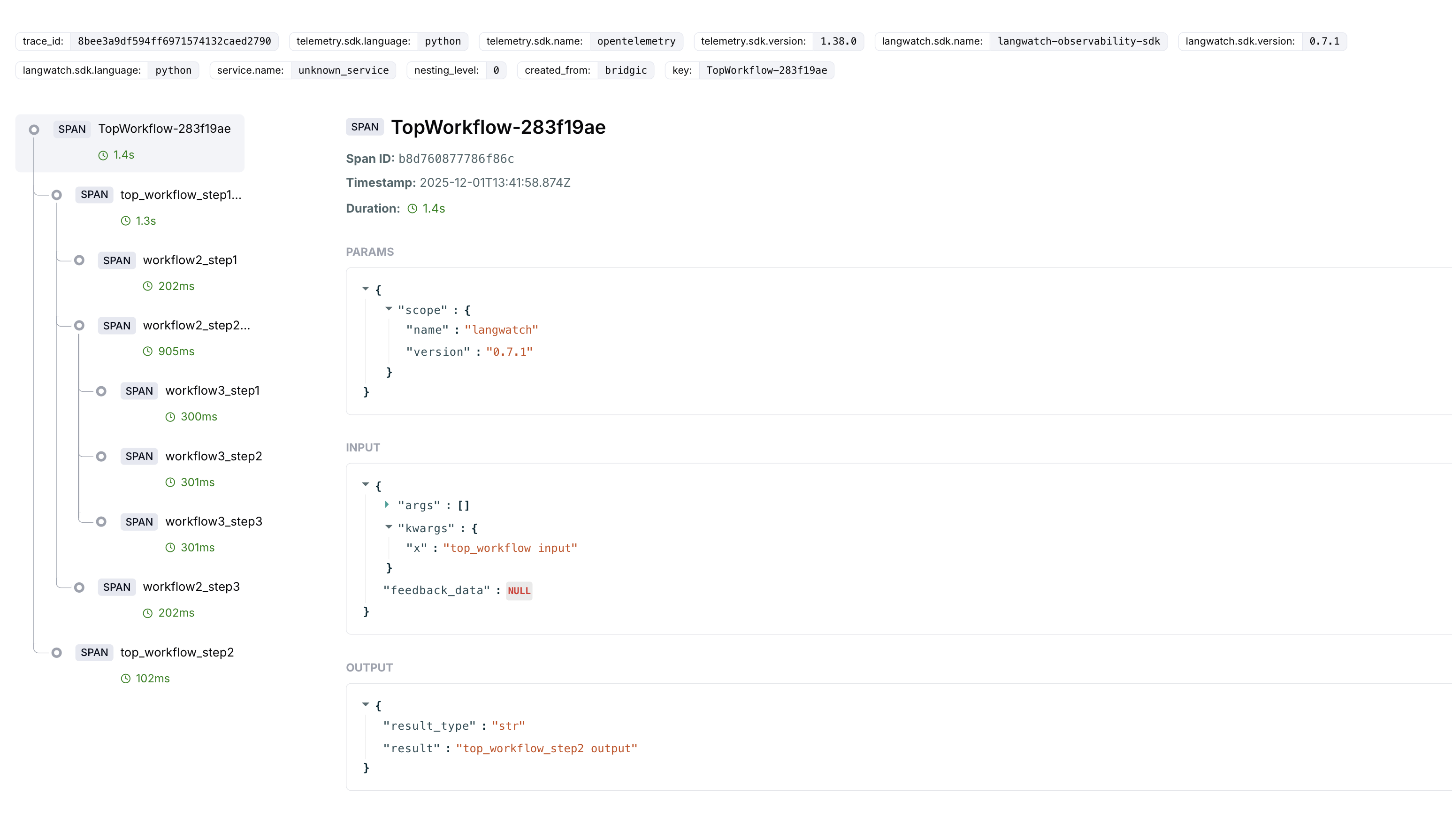
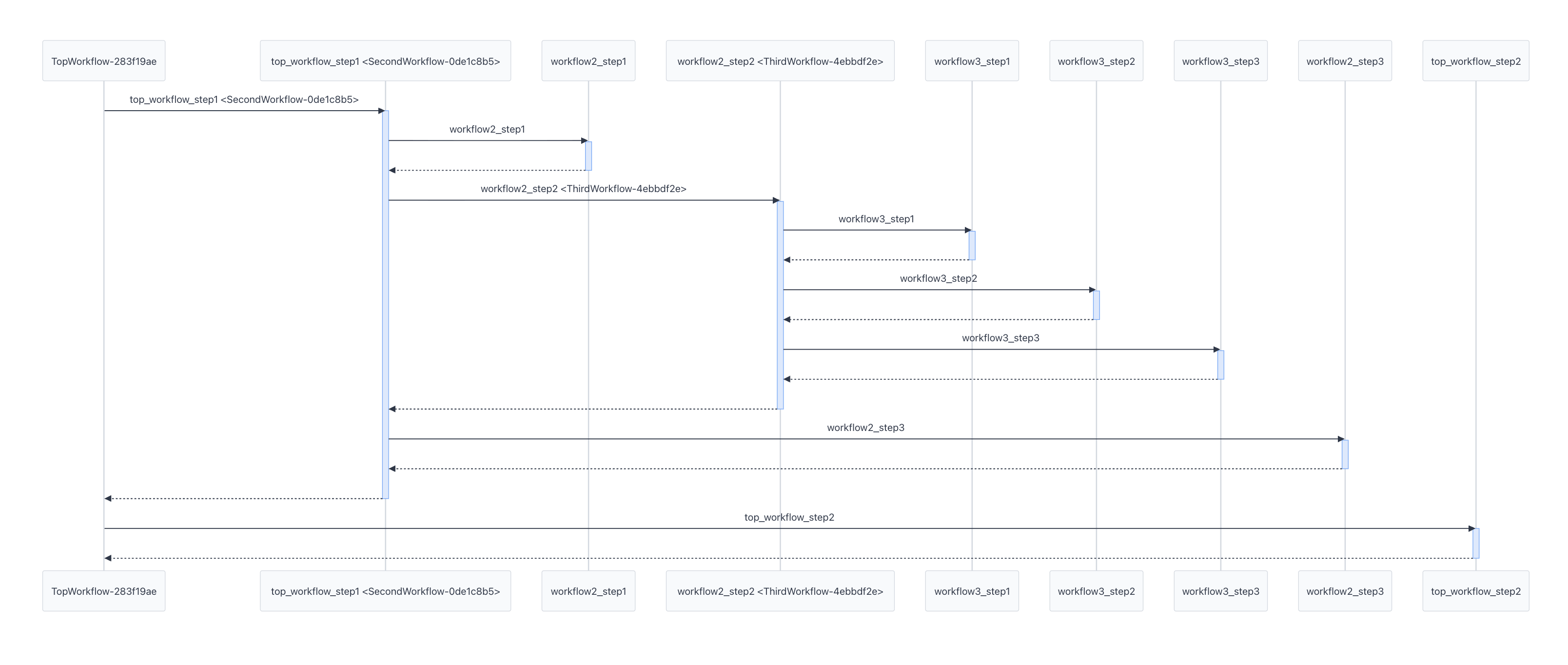
这个例子用于展示,使用Bridgic实现的一个嵌套组合的workflow(也可以是自主程度更高的agentic系统),是怎样在链路追踪上对应到一个trace tree上的。
先开启LangWatch的追踪:
from bridgic.traces.langwatch import start_langwatch_trace
start_langwatch_trace()
创建最内层的workflow:ThirdWorkflow。
class ThirdWorkflow(GraphAutoma):
@worker(is_start=True)
async def workflow3_step1(self, x):
return f"workflow3_step1 output"
@worker(dependencies=["workflow3_step1"])
async def workflow3_step2(self, x):
return f"workflow3_step2 output"
@worker(dependencies=["workflow3_step2"], is_output=True)
async def workflow3_step3(self, x):
return f"workflow3_step3 output"
# Create a ThirdWorkflow instance.
workflow3 = ThirdWorkflow()
创建中间一层的workflow:SecondWorkflow。前面创建的workflow3实例,被嵌入到SecondWorkflow实例的第2个worker的位置。
class SecondWorkflow(GraphAutoma):
...
workflow2 = SecondWorkflow()
@workflow2.worker(is_start=True)
async def workflow2_step1(x):
return f"workflow2_step1 output"
workflow2.add_worker(
key="workflow2_step2",
worker=workflow3,
dependencies=["workflow2_step1"],
)
@workflow2.worker(dependencies=["workflow2_step2"], is_output=True)
async def workflow2_step3(x):
return f"workflow2_step3 output"
创建顶层的workflow:TopWorkflow。它内部包含两个worker,其中第1个worker是前面创建的workflow2。
top_workflow = TopWorkflow()
top_workflow.add_worker(
key="top_workflow_step1",
worker=workflow2,
is_start=True
)
@top_workflow.worker(dependencies=["top_workflow_step1"], is_output=True)
async def top_workflow_step2(x):
return f"top_workflow_step2 output"
最后,执行top_workflow:
await top_workflow.arun(x="top_workflow input")
在LangWatch平台上,显示出来的trace详情和时序图,分别如下面两个图所示:
例子2:一个ReAct Agent
还是先开启LangWatch的追踪,并创建LLM:
from bridgic.llms.openai import OpenAILlm, OpenAIConfiguration
from bridgic.traces.langwatch import start_langwatch_trace
start_langwatch_trace()
llm = OpenAILlm(
api_base=_api_base,
api_key=_api_key,
configuration=OpenAIConfiguration(model=_model_name),
timeout=20,
)
使用ReActAutoma,创建一个旅行规划的Agent:
travel_planner_agent = ReActAutoma(
llm=llm,
system_prompt="You are a travel planner. You are given a city and a number of days. You need to plan a trip to the city for the given number of days.",
tools=[get_weather, get_flight_price, get_hotel_price],
)
执行它:
await travel_planner_agent.arun(
user_msg="Plan a 3-day trip to Tokyo. Check the weather forecast, estimate the flight price from San Francisco, and the hotel cost for 3 nights."
)
在LangWatch平台上,显示出来的trace详情和时序图,分别如下面两个图所示:
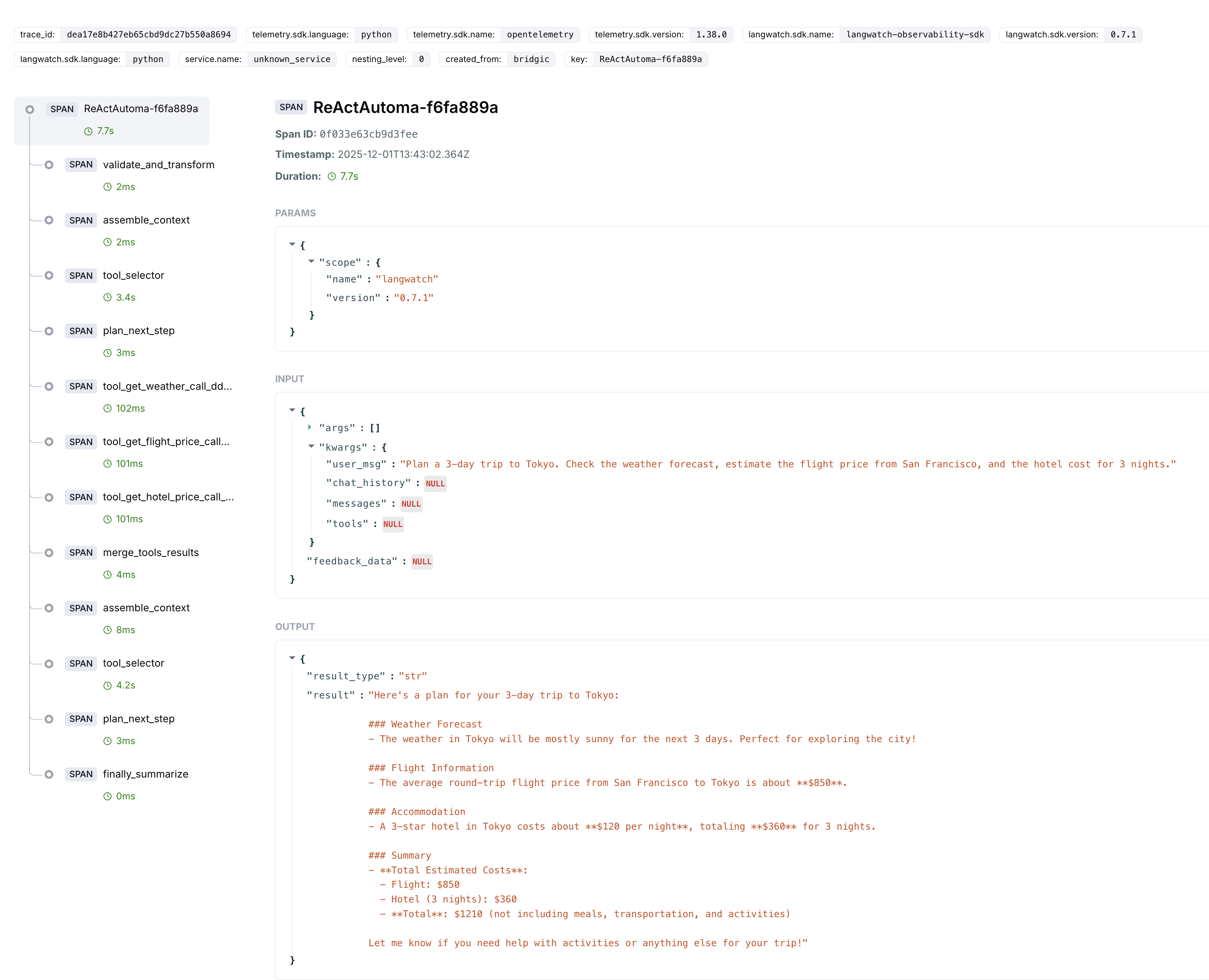
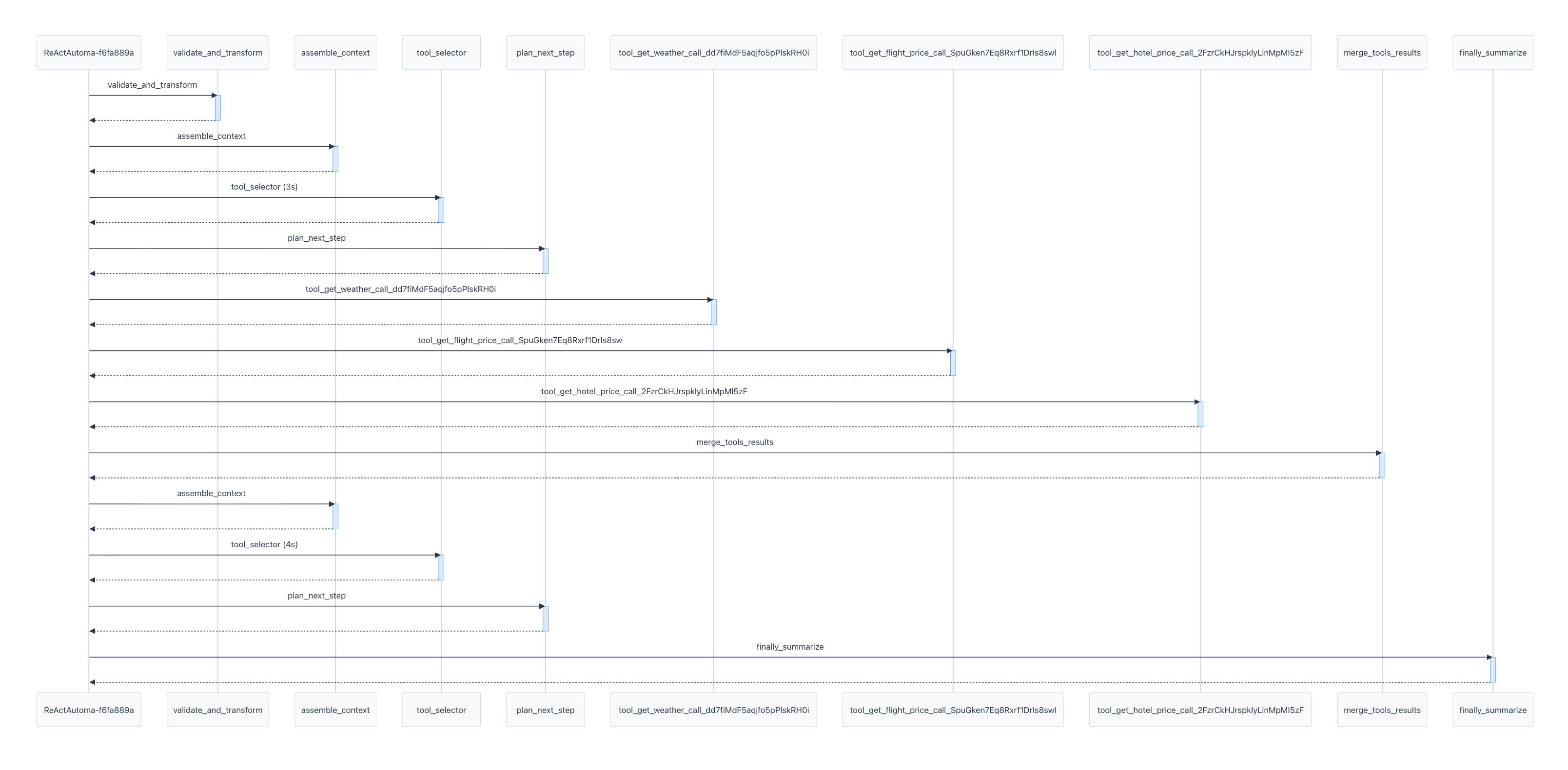
从上面两图中,我们可以看到ReActAutoma内部对于三个工具的调用(get_weather、get_flight_price、get_hotel_price)。这三个工具其实是并发调用的,它们被调用的起始时间几乎是同一时刻。但是,这种并发关系在上面的时序图中并没有体现出来。这说明,一些tracing系统对于并发执行关系的可视化,还没能够处理得特别精细。
源码下载
Bridgic源码地址 ➜ https://github.com/bitsky-tech/bridgic
Bridgic文档地址 ➜ https://docs.bridgic.ai/
本文第1个例子代码 ➜ https://github.com/bitsky-tech/bridgic-examples/blob/main/trace/workflow_nested_tracing.py
本文第2个例子代码 ➜ https://github.com/bitsky-tech/bridgic-examples/blob/main/trace/react_tracing.py
Bridgic可观测性的教程 ➜ https://docs.bridgic.ai/latest/tutorials/items/observability/
一句话,Bridgic是一个支持动态拓扑、强调组件化编程的开源AI智能体框架,也是学习AI编程、学习Python编程和异步编程的一份参考代码,很值得一读。觉得好的朋友可以给个star ^-^
加入技术交流群
我新建了一个“Bridgic开源技术交流群”,后面会在群里发布项目的开发进展及计划,并讨论相关技术。感兴趣的朋友可以扫描下面的二维码进群。如果二维码过期,请加微信ID: zhtielei,备注“来自Bridgic社区”。

(正文完)
参考文献:
- [1] 周志明. 《凤凰架构:构建可靠的大型分布式系统》.
- [2] Google Technical Report. Dapper, a Large-Scale Distributed Systems Tracing Infrastructure.
- [3] Peter Bourgon. Metrics, tracing, and logging.
其它精选文章:
- 基于动态拓扑的Agent编排,原理解析+源码下载
- 【开源】我亲手开发的一个AI框架,谈下背后的思考
- 一文讲透AI Agent开发中的human-in-the-loop
- AI Agent时代的软件开发范式
- 从Prompt Engineering到Context Engineering
- AI Agent的概念、自主程度和抽象层次
- 技术变迁中的变与不变:如何更快地生成token?
- 科普一下:拆解LLM背后的概率学原理
- 分布式领域最重要的一篇论文,到底讲了什么?
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-bridgic-trace.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。

最新文章
- 为什么agent和workflow可以融合在同一个架构里?
- 万字长文!两栖模式构建Agent,与OpenClaw/Hermes不一样的解法——开源AmphiLoop
- Claude Managed Agents意味着什么?
- 【开源】专为「探路+编码」范式设计的全新浏览器工具集+Skills
- 不用手写一行代码,10分钟立等可取,爬取twitter和github动态
- 使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
- 过年了,聊聊AI和人文
- 使用Bridgic长程自主模块+MCP,控制你的浏览器
- AI智能体纪元或将从2026开始归零
- 从Python异步编程的剖析中体会智能体并发编程模式