一文讲透AI Agent开发中的human-in-the-loop
2025-10-28
前段时间确实有点忙,好久没有发文了。不过最近有好多AI技术方面的想法要跟大家分享:-)
今天我们主要聊一聊在AI Agent开发中非常重要的一个特性:human-in-the-loop。
为什么需要human-in-the-loop?
我们在以前的文章中曾经讨论过在AI Agent开发中确定性和自主性的关系问题。自主性带来智能的行为和新的可能性,但软件的交付需要为客户提供确定性。这两者可以说是一对矛盾。
于是,在Agent的执行过程中引入人工确认,就成了消除不确定性的一种思路。想象一个做自动化运维的Agent,它在决定往生产环境部署一个服务之前,很可能需要获得管理员的核准才能继续运行。再想象一个做客户关系维护的Agent,它自动阅读了客户邮件,然后撰写了一封回复邮件,这个时候它在真正发送这封邮件之前,可能也需要先经过人工审核才能发送。而且,审核人员如果觉得邮件内容有欠妥的地方,可能还会给出具体的修改建议。Agent就可以根据人类建议对邮件内容进行修改,然后再继续执行。
AI的产品形式早已不再局限于chat式的一问一答。很多Agent可以长时间运行,比如,在连续运行几分钟甚至几小时后向人类交付结果。在企业环境下,你可以把这种新型的AI Agent想象成一个数字员工。它在业务水平上可能只有实习生的水平,但明显的优势就是不怕累,可以不眠不休地干着重复性的工作。
当然,它在行为方式上也跟实习生类似。想象公司里来了一名实习生,领导让你带着他干活。于是你交给了他一项任务,他就跑到旁边默默地去干了。在干的过程中,他碰到了一个棘手的问题,卡住了。他就会来找你请教,这个情况应该怎么处理。这个时候,你只需要给他一些指导,他就又重新投入到工作中去了。你要做的,只是提供必要的指导,而不用亲自动手去完成所有的事情,负担果然减轻了不少啊。如果这名实习生是一个虚拟的AI Agent呢?那么,它主动来找你提供指导,就是一种human-in-the-loop。作为一名虚拟的“实习生”,这个AI Agent在运行过程中如果碰到棘手的问题,或者待决断的问题,它就会停下来,然后通过各种渠道(比如IM、邮件)来找你。等到你有空了,回复它一下,并提供必要的处理指令,它就继续干活儿去了。
从抽象层面来看,在这样的一个处理过程中,人类被AI Agent牵涉其中,成为了Agent为了完成其自主操作的其中一环。这也是为什么这个机制称为human-in-the-loop。人类在提供核准或者指导意见的时候,我们一方面可以看做是,人类为AI Agent的运行提供了更具体、更准确的上下文;另一方面也可以看做是,AI把人当做了“工具”,它在必要的时候(通常是比较难处理的时候),把人类当做一个工具来调用了(而且这个工具相当智能和权威)。
跟实现有关的技术因素
现在,我们来思考一下,如何在技术层面来实现这种human-in-the-loop的机制。有哪些关键的技术因素需要考虑?
根据上一节的描述,AI Agent需要在执行过程中“停下来”,然后在跟人类完成交互后,再继续运行。有人可能会说,很多编程语言都有await的机制,是不是用await就能实现“停下来再继续运行”的效果?
这当然不是问题的全部。我们需要到真正的生产环境中去考虑这个问题。在生产环境中,有一些复杂的系统架构方面的因素需要考虑。其中有两个因素,对于如何实现human-in-the-loop有关键的影响:
- 第一个是分布式。
- 第二个是用户和AI Agent之间的通道性质。
我们先来讨论第一个因素——“分布式”架构的影响。一般来说,生产环境都不止一台服务器,很可能是一个包含多个机器节点的Agent集群。如下图,左边是server端,右边是client端。
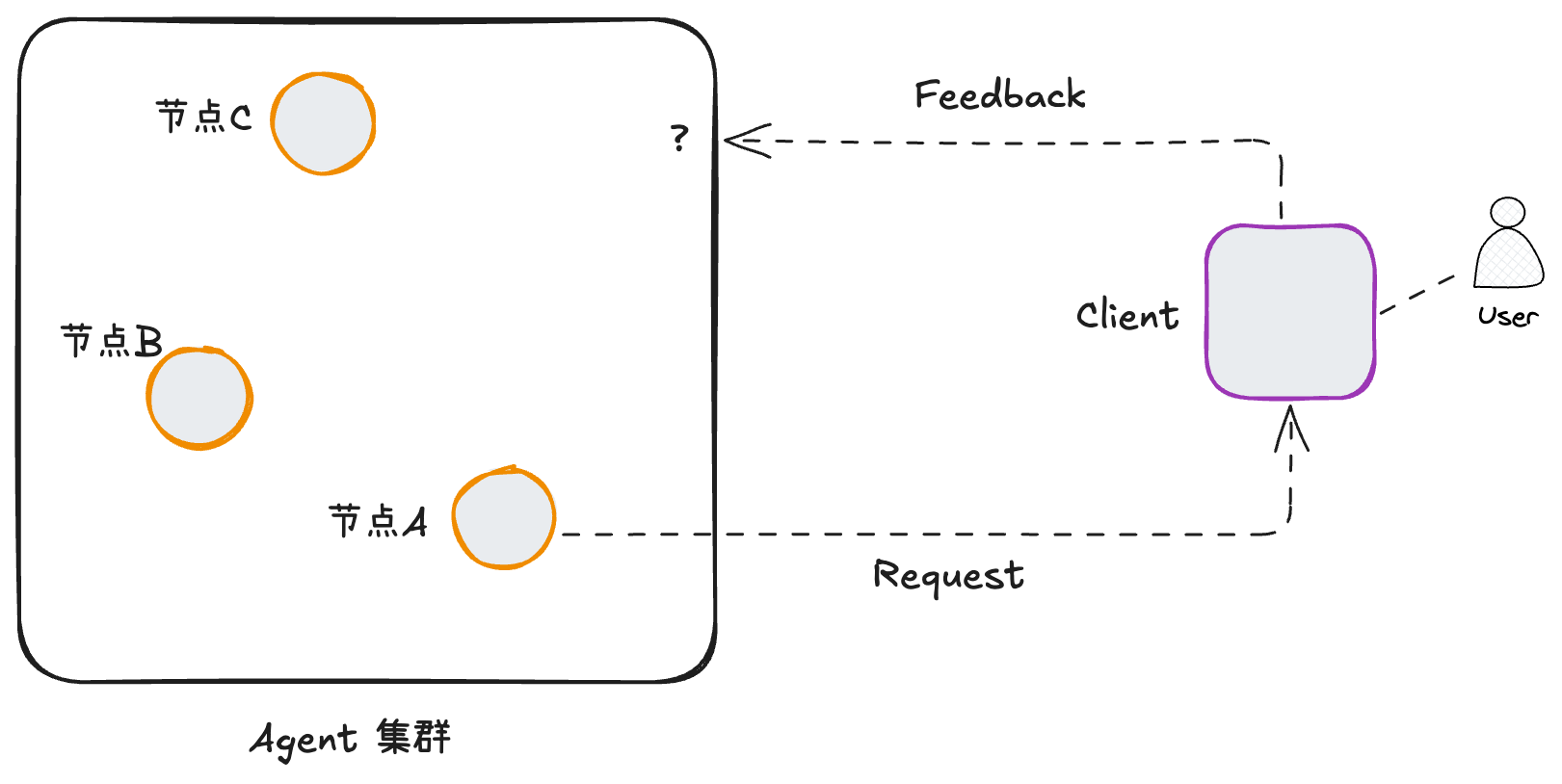
从上图我们发现,一个human-in-the-loop交互是由server端主动发起的。这跟传统的互联网应用开发不太一样。
假设一个AI Agent运行在节点A上。它在执行过程中发生了某种特殊事件,于是发起了一个human-in-the-loop的交互。也就是说,它通过某种通道向client端发送request,请求人类的介入。假设用户收到了来自Agent的这个请求,并给出了自己的反馈 (feedback) 。接下来,client端需要把这个feedback发送回server端。由于server端有多个服务器节点,一般来说,来自client端的网络请求会被随机分配到某个服务器节点上。这样就会导致,来自client的feedback信息,未必会落在当初发起human-in-the-loop请求的节点A上;同时,节点A由于收不到feedback而没法把human-in-the-loop继续下去。
之所以会出现上面的问题,除了分布式集群带来的影响之外,还有一个原因是,用户和AI Agent之间的通信通道没有能够做到会话保持 (session sticky) 。根据场景和运行环境的不同,用户和AI Agent之间的通道性质可能呈现很大的差异。下面是几种典型的情况:
- 第一种情况,client端和server端之间使用HTTP协议通信。这种情况下,请求必须由client端主动发起,server端才能够执行并做出响应。显然这种情况是没法支持上图中AI Agent主动向client端发起请求的。
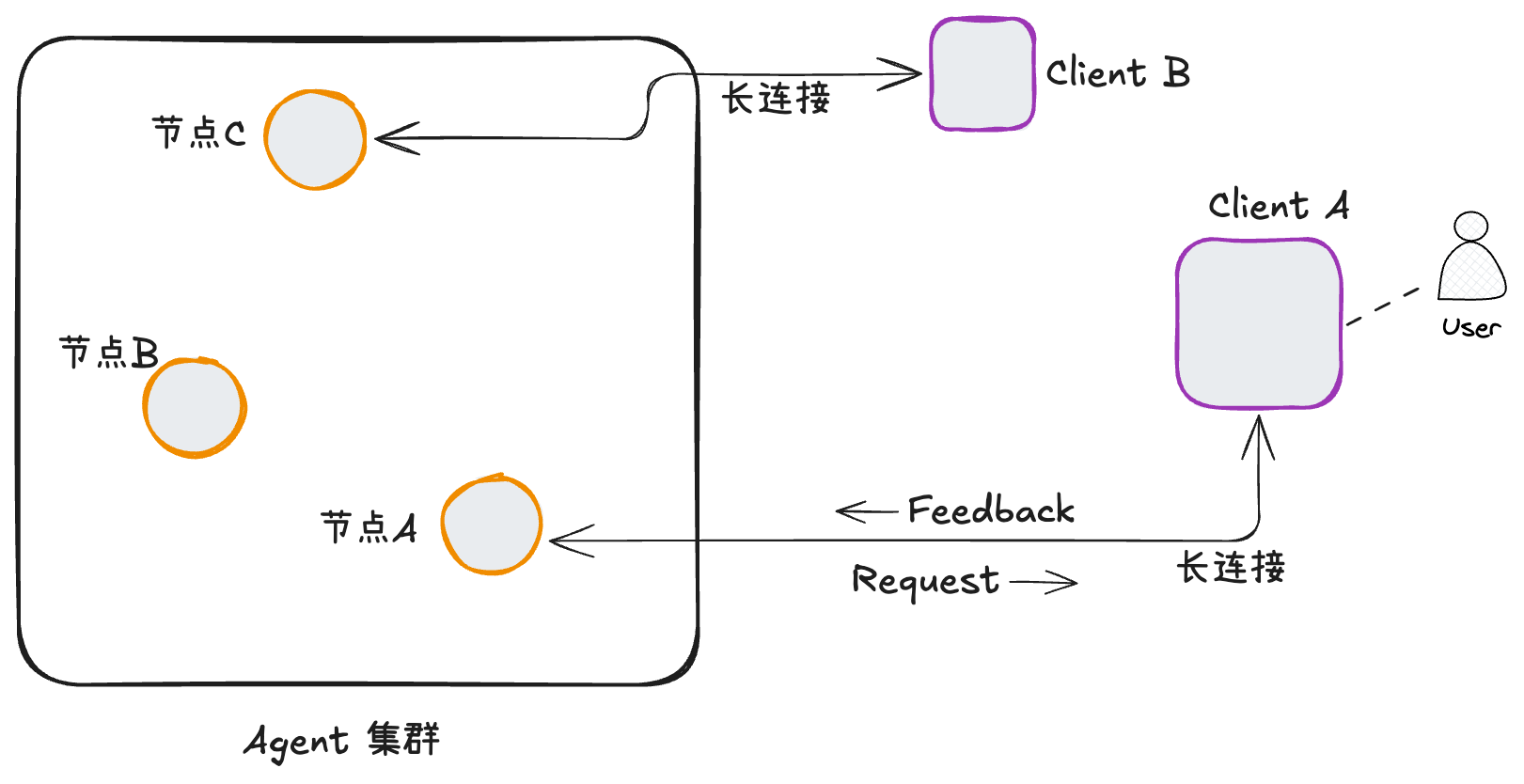
- 第二种情况,client端和server端之间使用某种长连接进行通信(比如WebSocket)。这种情况下,不管是client端还是server端,都可以随时向对方主动发起请求。而且,在上图中client端发回server端的feedback,仍然会沿着长连接发到节点A。用户和AI Agent之间,很容易在一条长连接上做到会话保持,也就比较容易支持human-in-the-loop这种由Agent主动发起的交互。下图展示了这种情况下的human-in-the-loop交互。
针对以上两种情况,还有一些技术实现上需要注意的地方。
首先对于第一种情况,我们在AI应用开发中经常使用的SSE技术 (Server-Sent Events) ,它属于HTTP协议,也具备一定的「server push」的能力,但仍然支持不了让AI Agent主动发起请求。原因在于,SSE依赖client端先建立起同server端的连接之后,server端才能向这个连接进行push。换句话说,SSE本质上其实还是由client主动发起交互的,用于实现一些流式的效果,但server端不能随时发起一个交互(至少在一个常规的实现中是这样的)。
还有一个需要注意的地方是,Agent集群外面可能存在一个网关,所有client都通过这个网关与后面的server建立连接。这时候,要实现server主动发起交互并且做到会话保持,首先要求client和网关之间是某种长连接,其次还要求网关具备会话保持的能力,有能力将server主动发起的request和来自client的feedback保持在一个会话内。这样,整个human-in-the-loop的流程才能由节点A来全部完成。
不管怎么说,在以上这两种情况下,用户和AI Agent之间的通信通道对于开发者来说,还是可控的。但还有第三种情况,这个通道是由第三方提供的,它的性质是开发人员控制不了的。如下图:
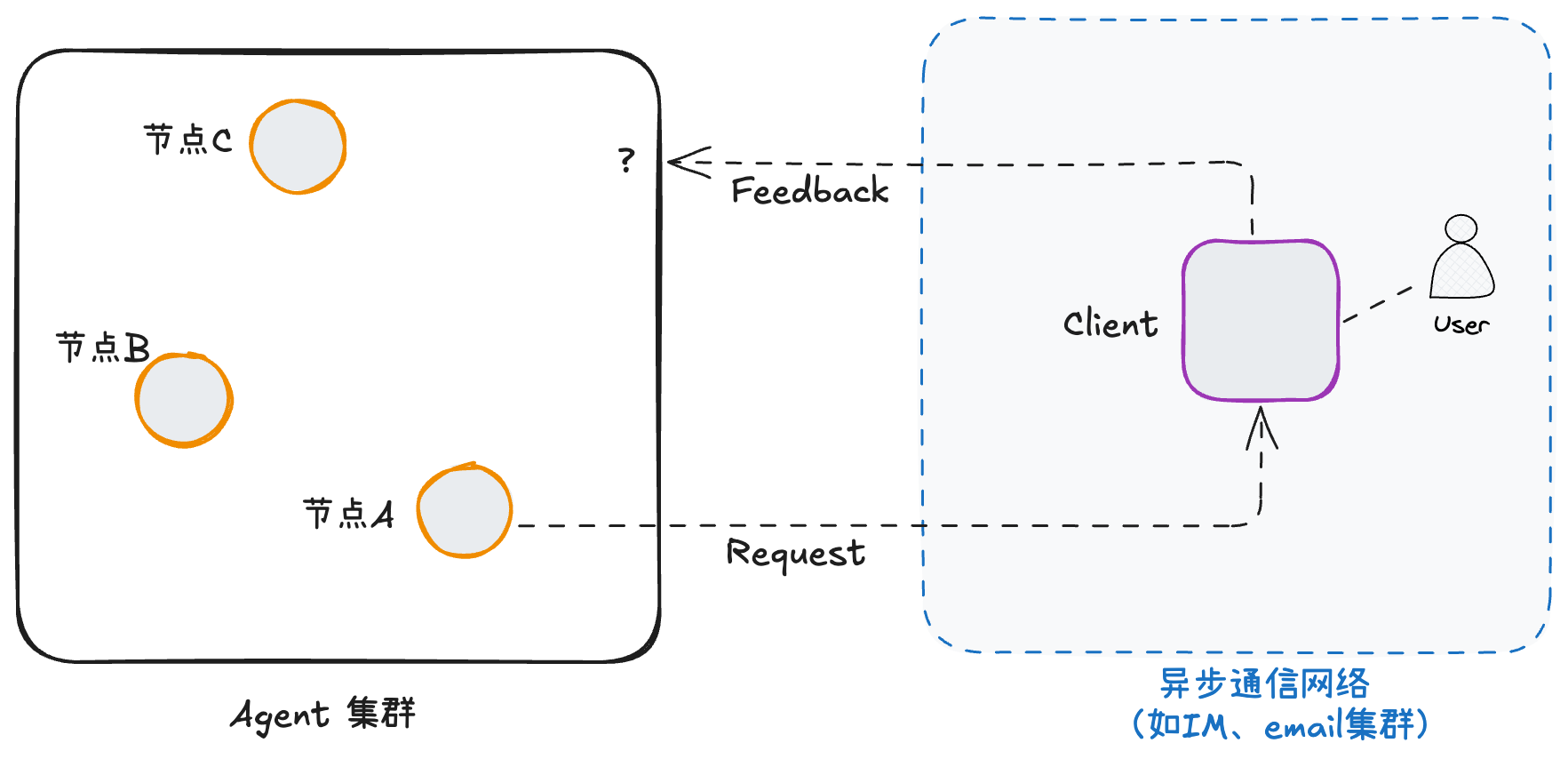
- 第三种情况,client端和server端之间通过某种异步通信网络进行通信。这种通信网络,一般来说是由第三方提供的。比如说,用户可能通过IM窗口跟Agent进行交互。这时候,client端和server端之间自然建立不起长连接。节点A发起的human-in-the-loop的request,其对应的feedback也大概率无法保证仍然由节点A接收到。
考虑到以上这些因素,服务端对于human-in-the-loop的实现,就需要不同的技术方案。
两种技术方案
我们把前面几种情况分成两类:
- (1)client端和server端之间具备长连接的条件,且能够做到会话保持的。主要是第二种情况。
- (2)client端和server端之间无法保持会话的。包括第一种情况和第三种情况。
对于(1),我们可以利用长连接和会话保持的优势,让server端的一个节点完成human-in-the-loop的整个交互过程。这样server端的实现就会简单很多。以Python语言为例,human-in-the-loop的机制可以这样实现:
- Agent通过长连接向用户发送一个交互请求。
- Agent使用await机制等待在一个future对象上,即,等待client端响应。
- 用户处理这个请求,给出核准或指导意见,client端以feedback的形式,通过长连接发回给Agent所在的server节点。
- server节点的上层代码为前面的future对象设置结果。
- Agent从等待future对象的状态中恢复,并从future对象中拿到用户的feedback。
- Agent基于用户的feedback继续执行。一个human-in-the-loop的过程结束。
当然,这种实现方式对于基础设施存在比较高的要求,维护长连接和保持会话,通常不是那么容易的事。而且,系统本身维持长连接也是有成本的。
对于(2),client端和server端无法保持会话,来自用户的feedback可能落在任意server节点上。这时只有一种办法:对Agent的整个运行状态进行序列化、持久化、反序列化。整个技术处理流程较复杂,如下:
- Agent向用户发送一个交互请求。
- Agent将内部运行状态进行序列化,并停止运行。
- server节点的上层代码将Agent序列化后的数据存入DB,完成持久化。同时,已经停止的Agent实例,不再需要保持在内存中。
- 用户处理这个请求,给出核准或指导意见,client端以feedback的形式,发回到server端任意一个节点上。
- 收到feedback的节点从DB中加载前面序列化的数据,并在内存中反序列化,重新创建出Agent实例。注意,这个Agent实例保持了运行状态,它知道自己下一步该从哪里继续运行。
- 反序列化后的Agent从之前中断的地方恢复,并拿到来自用户的feedback。
- Agent基于用户的feedback继续执行。一个human-in-the-loop的过程结束。
关于序列化和反序列化
有人可能会问,什么是序列化和反序列化呢?简单来说,序列化是把一个内存对象转成一串bytes或string的过程;而反序列化是从一串bytes或string中恢复一个内存对象的过程。
不得不说的是,把一个复杂对象进行序列化和反序列化,不是一件容易的事。为什么这么说呢?难度来源于对象之间的关系:
- 一个复杂的对象,可能引用了其他对象;而其他对象又引用了更多对象。
- 面向对象编程带来的method和对象实例之间的绑定关系,也为序列化和反序列化带来了诸多麻烦。
假设仅仅是对于某个数据对象进行序列化和反序列化,情况可能尚在可控范围内。数据对象通常只包含数据字段,数据对象之间的引用关系一般也呈现单向的引用关系。但让问题更复杂的是,Agent对象不仅仅是一个数据对象,它更是一个包含运行行为的运行时对象。运行时对象之间,可能存在错综复杂的引用关系。
总之,我们必须谨慎地选择,把哪些信息放到序列化的数据之中,哪些不放。通常来说,应该只序列化那些必要的、动态的数据,而其他信息可以尽量保留在代码中。以后有机会了我们再仔细展开这个话题。
小结
今天我们探讨了human-in-the-loop这种机制,它出现的技术背景、两种不同的实现思路,以及中间的成本和难点。下一篇,我尝试通过代码来展示这两种实现方案。敬请期待。
(正文完)
其它精选文章:
- AI Agent时代的软件开发范式
- 从Prompt Engineering到Context Engineering
- 开发AI Agent到底用什么框架——LangGraph VS. LlamaIndex
- AI Agent的概念、自主程度和抽象层次
- 技术变迁中的变与不变:如何更快地生成token?
- 科普一下:拆解LLM背后的概率学原理
- 从GraphRAG看信息的重新组织
- 企业AI智能体、数字化与行业分工
- 分布式领域最重要的一篇论文,到底讲了什么?
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-ai-agent-human-in-the-loop.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。

最新文章
- 为什么agent和workflow可以融合在同一个架构里?
- 万字长文!两栖模式构建Agent,与OpenClaw/Hermes不一样的解法——开源AmphiLoop
- Claude Managed Agents意味着什么?
- 【开源】专为「探路+编码」范式设计的全新浏览器工具集+Skills
- 不用手写一行代码,10分钟立等可取,爬取twitter和github动态
- 使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
- 过年了,聊聊AI和人文
- 使用Bridgic长程自主模块+MCP,控制你的浏览器
- AI智能体纪元或将从2026开始归零
- 从Python异步编程的剖析中体会智能体并发编程模式