人类在环智能体源码展示:企业报销工作流举例(附源码下载)
2025-11-01
在上篇文章中,我们讨论了AI智能体开发中「人类在环 (human-in-the-loop)」机制的一些重要方面。今天,我给出一些示例代码来展示其中核心部分的实现过程及注意事项。文末附上源码下载链接。
本文的目标:
- 通过一个企业报销工作流的案例,来清晰地说明整个交互过程。
- 原理解析以及其他问题讨论。
一个企业报销工作流
根据我们在上篇文章的分析结论,如何实现human-in-the-loop取决于两种主要的技术场景:
- (1)client端和server端之间具备长连接的能力,且系统能够以某种方式做到会话保持。
- (2)client端和server端之间不需要保持会话。系统架构只需要跟普通的互联网web应用一样。
为了让本文的内容尽量精简,我接下来仅针对第(2)种场景给出代码示例和解释。这种方案对于基础设施没有太特殊的要求,所以使用范围更广。当然,针对第(1)种场景的代码链接也会给出。
我们假设要开发一个做企业报销自动化的智能体。每当公司内有员工提交了报销流程后,它就会自动运行,进行各种合规性检查,并最终完成自动化地打款。由于打款这一步是敏感操作,所以需要在真正打款前获得管理员的审批意见,也就是在这一步过程中需要一个human-in-the-loop交互。
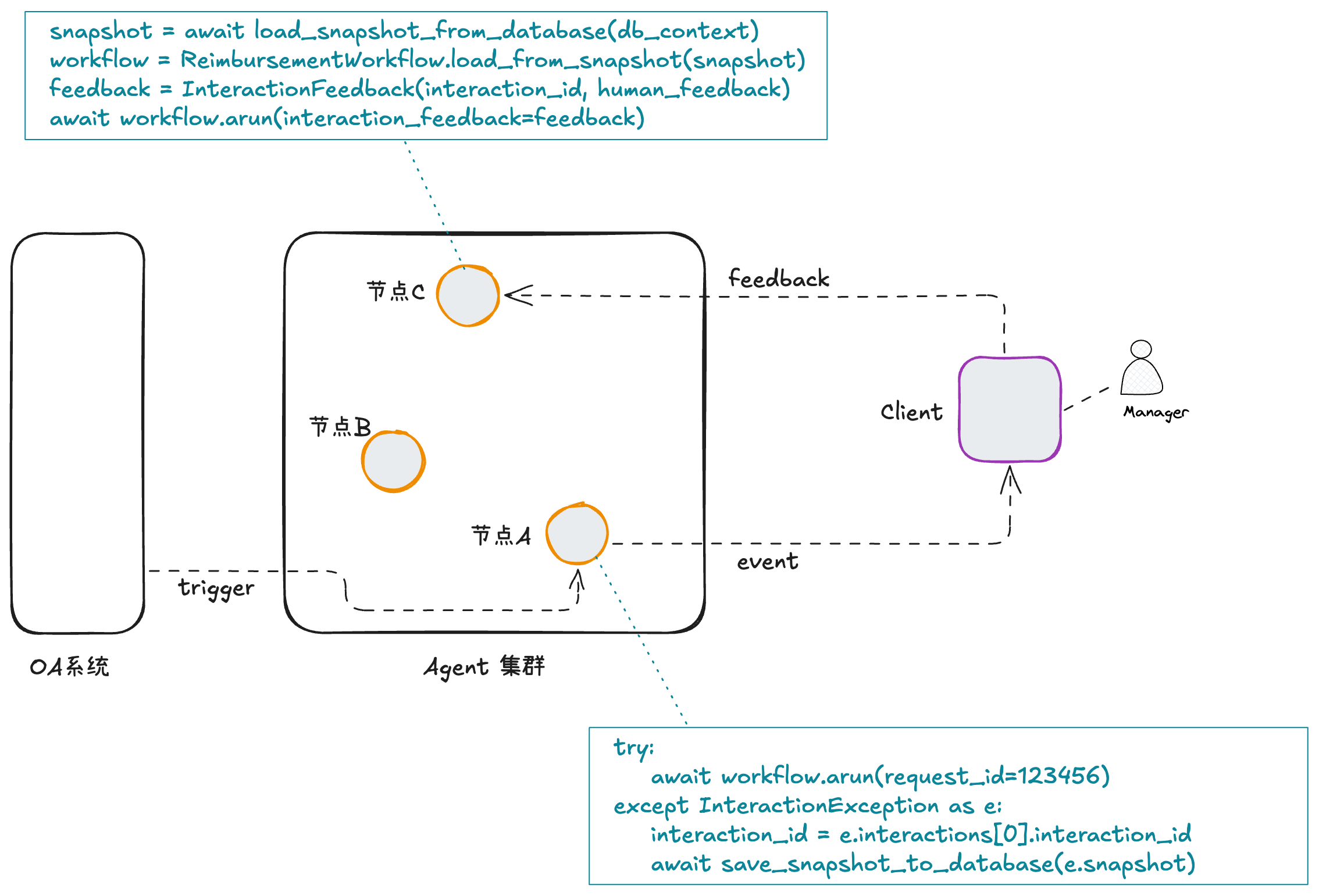
根据以上架构图,我们逐步来拆解一下整个过程。
最开始,有员工在公司OA系统中提交了报销流程(上图左侧),这个流程的提交会产生一个trigger消息,可能是通过消息队列、回调或者其他系统机制。总之,这条消息会触发Agent集群自动调度执行一个「企业报销工作流」。这里需要注意的是,我们讨论的这个工作流是由系统消息触发的,而不是由用户通过类似chat的界面直接发起的。它代表了某种数字员工的运行模式,更详细描述可以参见前一篇文章。
如上图 ,假设这个「企业报销工作流」是调度到了节点A上执行。为了实现它,我们使用一个新的AI框架:Bridgic框架。这是我们团队刚刚开源的一个项目,使用Python语言编写,代码非常精简,很适合学习AI编程。
首先,创建一个GraphAutoma的子类,来表示这个「企业报销工作流」:
class ReimbursementWorkflow(GraphAutoma):
...
这个工作流经过精简之后,至少要包含三个步骤:
- 第一步,加载报销记录。
- 第二步:自动审计。
- 第三步:执行打款。
我们把这三步分别实现成ReimbursementWorkflow的method。下面是流程第一步的代码:
class ReimbursementWorkflow(GraphAutoma):
...
@worker(is_start=True)
async def load_record(self, request_id: int):
return await self.load_record_from_database(request_id)
装饰器@worker的is_start参数表明,load_record这个方法是流程的第一步。方法的参数request_id,来自OA系统的trigger消息,指明当前报销记录的ID。在这个方法中,根据request_id从数据库中获取到待处理的报销记录数据,作为方法的返回值,用于传给下一步处理。
第二步,自动审计,指的是根据业务规则进行自动化合规审计。下面的代码模拟了这一过程。
class ReimbursementWorkflow(GraphAutoma):
...
@worker(dependencies=["load_record"])
async def audit_by_rules(self, record: ReimbursementRecord):
if record.reimbursement_amount > 2500:
return AuditResult(
request_id=record.request_id,
passed=False,
audit_reason="The reimbursement amount {record.reimbursement_amount} exceeds the limit of 2500."
)
# Add more audit rules here.
...
return AuditResult(
request_id=record.request_id,
passed=True,
audit_reason="The reimbursement request passed the audit."
)
这段代码从前一步拿到报销记录,用record参数表示。做了报销金额的判断,单次报销金额不能超过2500元,再经过一系列业务规则判断后,返回自动审计结果(用一个AuditResult对象来表达)。
第三步,执行打款。这一步调用interact_with_human发起了一个human-in-the-loop的交互。
class ReimbursementWorkflow(GraphAutoma):
...
@worker(dependencies=["audit_by_rules"])
async def execute_payment(
self,
result: AuditResult,
record: ReimbursementRecord = From("load_record")
):
if not result.passed:
return False
event = Event(
event_type="request_approval",
data={
"reimbursement_record": record,
"audit_result": result
}
)
feedback: InteractionFeedback = self.interact_with_human(event)
if feedback.data == "yes":
await self.lanuch_payment_transaction(record.request_id)
return True
return False
这一步稍微有点复杂,我们来详细解读一下。
execute_payment方法接收两个参数:一个是result,表示前一步的自动审计结果;另一个是record,表示流程第一步查出来的报销记录(这里使用了Bridgic框架提供的参数注入机制)。
interact_with_human是Bridgic框架提供的一个API,调用它会产生两个效果:
- 工作流的执行会立即暂停。
- 工作流实例会被序列化。也就是把工作流的运行状态表示成一串bytes。
interact_with_human传入的参数是一个Event对象,它描述了这次human-in-the-loop交互的相关信息,在这里包含了报销记录的数据和系统自动审计的结果。这些信息在后面会发送到client端并展示给人类管理员。
这里需要注意的是,interact_with_human调用后,这个「企业报销工作流」就停止运行了,相关的内存资源也会被释放掉。根据前面的架构图,在节点A上的运行资源会释放出来,确保在等待用户反馈的这段时间内(可能很长),工作流是不占用运行资源的。interact_with_human方法返回之后的流程,我们下面再说。
至此,企业报销工作流ReimbursementWorkflow的实现代码,核心部分就讲解完了。然后就是如何运行和恢复这个工作流的问题。
在节点A上,受到来自OA系统消息的trigger,下面的代码会被触发执行:
workflow = ReimbursementWorkflow()
try:
await workflow.arun(request_id=123456)
except InteractionException as e:
# The workflow instance has been paused and serialized to a snapshot.
interaction_id = e.interactions[0].interaction_id
record = e.interactions[0].event.data["reimbursement_record"]
audit_result = e.interactions[0].event.data["audit_result"]
# Save the snapshot to the database.
db_context = await save_snapshot_to_database(e.snapshot)
调用workflow.arun会执行工作流。但由于工作流执行到第三步的时候发起了一个human-in-the-loop的交互,导致工作流执行暂停了。在代码的表现上就是,workflow.arun会抛一个异常,从异常里面能够解出几个关键信息:
interaction_id:一个用于唯一标识这次human-in-the-loop的ID。record:从前面interact_with_human传入的报销记录。audit_result:从前面interact_with_human传入的审计结果。e.snapshot:表示工作流当前运行状态的快照。可以用于持久化到外存里。
包含interaction_id、record和audit_result的事件,会通过某种消息通道(IM、email或HTTP都有可能)发送给client端,并根据需要展示给管理员用户,等待管理员的审批。
管理员可能批准通过,也可能拒绝该报销请求,总之,产生了一个反馈。这份反馈数据由client端通过网络请求提交给Agent集群。假设这次处理反馈请求的是节点C(如前架构图所示),那么在节点C上执行的代码如下:
# Load the snapshot from the database.
snapshot = await load_snapshot_from_database(db_context)
# Deserialize the `ReimbursementWorkflow` instance from the snapshot.
workflow = ReimbursementWorkflow.load_from_snapshot(snapshot)
feedback = InteractionFeedback(
interaction_id=interaction_id,
data=human_feedback
)
await workflow.arun(interaction_feedback=feedback)
运行在节点C的这段代码,先从数据库中取回持久化后的bytes串,并从中反序列化出一个工作流ReimbursementWorkflow的实例。然后,来自管理员的反馈数据被包装成一个InteractionFeedback对象,作为参数传入workflow.arun。
值得注意的是,这个反序列化后的工作流实例,保存了之前在节点A上的运行状态。这里重新调用workflow.arun后,这个工作流会从原来中断的第三步接着执行。等到interact_with_human返回时,它会返回用户的反馈数据,这样工作流的代码就可以基于这个反馈数据进行后面的操作。
feedback: InteractionFeedback = self.interact_with_human(event)
if feedback.data == "yes":
await self.lanuch_payment_transaction(record.request_id)
return True
return False
这段代码前面已经展示过。feedback.data中包含了来自管理员的反馈,如果是”yes”,那么就可以进行真正的打款操作了。
实现原理解析
一些复杂的操作,比如工作流的暂停、重启,运行状态的序列化、反序列化,全部由Bridgic框架完成。
当interact_with_human被调用时,它会:
- 先检查当前的这次交互是不是已经匹配到了反馈数据,如果有的话,就返回反馈数据。否则,
- 它会标记一个待处理的交互请求。
- 通过抛异常的方式,中断当前执行过程。
当初次执行workflow.arun时(未传入interaction_feedback参数),Bridgic框架会调度工作流的执行。在执行过程中:
- 收集
interact_with_human抛出的异常。 - 把异常信息沿着组件嵌套关系逐层向上抛出(Bridgic框架支持组件嵌套复用)。
- 调用底层的序列化模块,将所有必需的运行动态序列化。
- 将序列化后的数据(连同一个序列化版本号)封装成一个
Snapshot对象。 - 将Snapshot对象封装在一个
InteractionException对象中,并抛给上层。
当重新执行workflow.arun时(传入了interaction_feedback参数):
- 根据传入的用户反馈数据,去匹配待处理的交互标记。
- 沿着组件嵌套关系逐层向下进行匹配。
- 为匹配上的交互标记关联反馈数据并记录下来。
其他相关问题讨论
有读者可能会说,前面的「企业报销工作流」似乎没有用到LLM。这是因为本文的主要目的是为了讨论human-in-the-loop功能,为了演示简单一些才如此。在实际中,跟大模型的结合有很多种可能性。比如,在征求用户反馈之前,可以调用LLM对于审计结果和相关报销信息进行总结;或者在用户反馈之后,可以让LLM继续分析用户反馈(自然语言的反馈),决定下一步的动作。
另外一个问题是自定义对象的序列化问题。也就是说,你可能在工作流的实现中包含了自定义字段,如何对这些字段进行序列化?这其实涉及到两个问题:
- 第一,哪些字段需要序列化。我们在上篇文章中曾提到,最好只序列化那些必要的数据。
- 第二,如果一个字段是自定义类型(非常见的Python基础类型),那么框架如何知道怎么序列化它?
在Bridgic框架中,可以在需要的时候进行精细化的控制。我们后面有机会再展开。
源码下载
本文引用的完整代码,参见:https://github.com/bitsky-tech/bridgic-examples/blob/main/human_in_the_loop/reimbursement_automation.py。可以下载下来动手执行。
另外,在上篇文章中我们还提到了另外一种技术方案(要求长链接和会话保持的)。本文没有展示代码,但我也准备了一个例子,感兴趣的话也可以下载代码执行:https://docs.bridgic.ai/latest/tutorials/items/core_mechanism/human_in_the_loop/。
Bridgic框架中关于human-in-the-loop的实现代码,参见:
interact_with_human方法:https://github.com/bitsky-tech/bridgic/blob/main/bridgic-core/bridgic/core/automa/_automa.py#L421。arun方法:https://github.com/bitsky-tech/bridgic/blob/main/bridgic-core/bridgic/core/automa/_graph_automa.py#L948。- 数据结构定义:https://github.com/bitsky-tech/bridgic/blob/main/bridgic-core/bridgic/core/automa/interaction/_human_interaction.py。
(正文完)
其它精选文章:
- AI Agent时代的软件开发范式
- 从Prompt Engineering到Context Engineering
- 开发AI Agent到底用什么框架——LangGraph VS. LlamaIndex
- AI Agent的概念、自主程度和抽象层次
- 技术变迁中的变与不变:如何更快地生成token?
- 科普一下:拆解LLM背后的概率学原理
- 从GraphRAG看信息的重新组织
- 企业AI智能体、数字化与行业分工
- 分布式领域最重要的一篇论文,到底讲了什么?
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-coding-example-human-in-the-loop.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。

最新文章
- 为什么agent和workflow可以融合在同一个架构里?
- 万字长文!两栖模式构建Agent,与OpenClaw/Hermes不一样的解法——开源AmphiLoop
- Claude Managed Agents意味着什么?
- 【开源】专为「探路+编码」范式设计的全新浏览器工具集+Skills
- 不用手写一行代码,10分钟立等可取,爬取twitter和github动态
- 使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
- 过年了,聊聊AI和人文
- 使用Bridgic长程自主模块+MCP,控制你的浏览器
- AI智能体纪元或将从2026开始归零
- 从Python异步编程的剖析中体会智能体并发编程模式