基于动态拓扑的Agent编排,原理解析+源码下载
2025-11-13
上篇文章发出来之后,不少朋友说想看看「动态拓扑」的代码长什么样子。当然,代码怎么写只是问题的一个方面,是一个表现形式。关键问题在于,上篇文章讨论的那些所谓的「思考」,是如何从抽象的概念变为实实在在的代码的,以及这些代码的结构是如何组织起来的。这是一个有趣的过程(相信你也会这么认为)。
对编排的表达
在一个AI框架的底层,编排仍然占据核心的基础地位。甚至可以说,它决定了一个AI框架描述能力的上限。在Bridgic框架中,基于动态有向图 (Dynamic Directed Graph - DDG) 的编排,提供了最强的编排动态性。
为了对编排的动态性有更全面的理解,我们仍然依照动态性从弱到强的顺序,来依次展示不同的情景:
- 静态编排。
- 动态编排。
- 自主编排(对动态拓扑的要求,出现在这个地方)。
这几个概念最初来源于《AI Agent的概念、自主程度和抽象层次》一文。如果你当前是初次见到它们,也没有关系,下面我会分别通过代码来进行直观的展示。
第一种:静态编排。
执行路径的每一步都是提前确定好的。在Bridgic中,我们有两种方式来实现这种静态编排。
假设我们要执行如下的拓扑。

第一种方式,使用Core API来实现。代码如下:
from bridgic.core.automa import GraphAutoma
async def worker_1(x: int) -> int:
return x + 1
async def worker_2(x: int) -> int:
return x + 2
async def worker_3(x: int) -> int:
return x + 3
async def worker_4(x1: int, x2: int) -> int:
return x1 + x2
class AdderAutoma(GraphAutoma):
...
adder = AdderAutoma()
adder.add_func_as_worker("worker_1", worker_1, is_start=True)
adder.add_func_as_worker("worker_2", worker_2, dependencies=["worker_1"])
adder.add_func_as_worker("worker_3", worker_3, dependencies=["worker_1"])
adder.add_func_as_worker(
key="worker_4",
func=worker_4,
dependencies=["worker_2", "worker_3"],
is_output=True
)
以上代码定义了一个叫做AdderAutoma的类,它继承自GraphAutoma(具体实现了DDG的类)。然后我们使用了GraphAutoma的add_func_as_worker API,将各个function转变为一个worker对象,并添加到这个AdderAutoma的实例中。同时,各个worker之间的依赖关系也通过dependencies参数指定好。
注意,这个时候AdderAutoma的实例adder还没有真正开始运行。所以我们说,以上对于这4个worker的编排,属于静态编排。因为在执行之前,执行路径的每一步都已经提前确定好了:worker_1先执行;然后是worker_2和worker_3并发执行;最后是worker_4执行。这里需要补充的一点是:worker_2和worker_3都依赖同一个worker_1,这种表达方式在Bridgic中就意味着「并发执行」。
第二种方式,使用声明式的API来实现。代码如下:
from bridgic.core.automa import GraphAutoma, worker
class AdderAutoma(GraphAutoma):
@worker(is_start=True)
async def worker_1(self, x: int) -> int:
return x + 1
@worker(dependencies=["worker_1"])
async def worker_2(self, x: int) -> int:
return x + 2
@worker(dependencies=["worker_1"])
async def worker_3(self, x: int) -> int:
return x + 3
@worker(dependencies=["worker_2", "worker_3"], is_output=True)
async def worker_4(self, x1: int, x2: int) -> int:
return x1 + x2
adder = AdderAutoma()
既然静态编排的依赖关系是提前确定好的,那么用声明式的方式来定义,就是很自然的。
好了,你现在已经看到了两种代码调用方式。当然,它们都只是表现形式。那背后发生了什么呢?
就像在上一篇中我们所讨论的,Bridgic的一个核心设计原则就是,将系统建立在一套统一的概念基础之上。这当然也会体现在API的设计上。
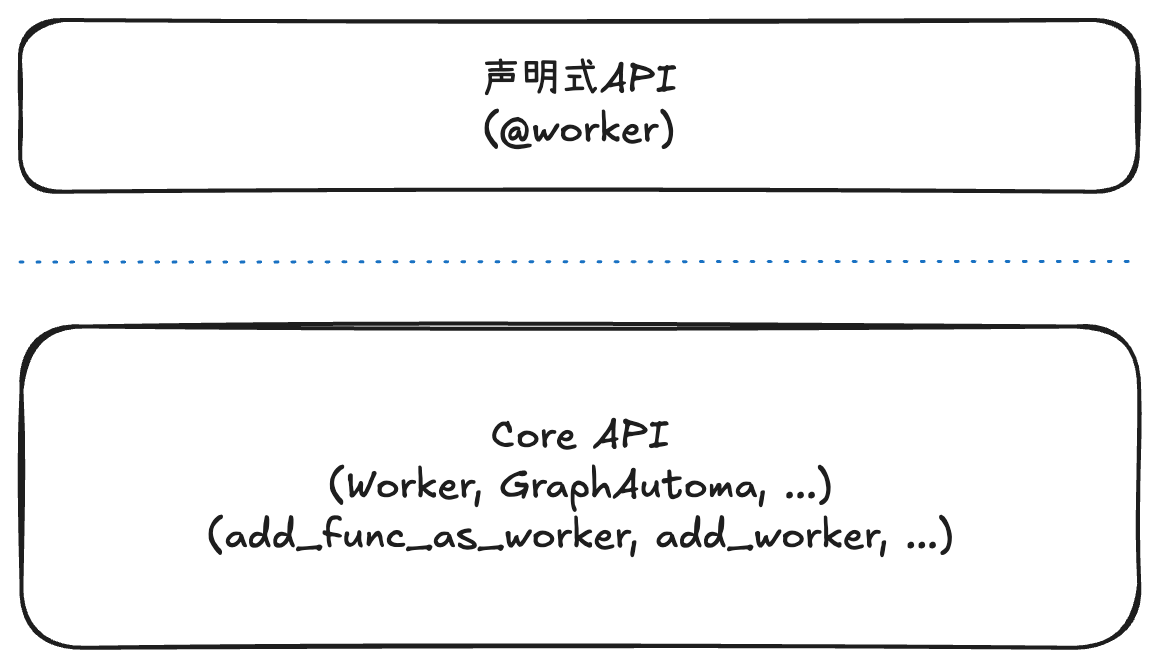
在Bridgic框架的软件架构中,Core API是底层暴露的最基础的一个API层次(代码对应bridgic.core这个package)。Bridgic框架的其他功能特性,都是构建在Core API之上的。当然,上层应用开发者也可以在需要的时候调用这一层API。
如上图:
@worker这样的声明式API,是建立在Core API之上的。具体来说,@worker的底层实现,是调用了add_func_as_worker的。- 底层的基本执行单元是
Worker,这是Bridgic的核心概念之一(具体分析参见上篇文章)。所以说,虽然在前面两段代码中,一个worker的具体表现形式是一个function或method,但它们在底层会被转成一个Worker对象。具体来说,@worker的实现是建立在add_func_as_worker之上的,而add_func_as_worker的实现则最终把function或method封装成一个框架可以调度执行的Worker对象。当然了,你也可以直接继承Worker创建子类和实例,放到GraphAutoma中进行编排(具体代码这里就不举例了)。
最后,我们实际运行一下前面创建的AdderAutoma实例,看看执行结果:
y = await adder.arun(x=10)
结果应该是y等于27。
接下来,我们来看一下第二种编排:动态编排。
具体执行时的路径只能根据输入数据动态确定。但是,所有可能的执行路径和每一步可能的执行逻辑,是提前确定好的。
具体到Bridgic的框架实现当中,这个情景相当于,动态有向图中包含哪些worker是提前固定好的,不会随着Agent的执行而增加或减少。但是,worker之间的依赖关系并不是提前定死的,而是可以根据输入数据来动态决定下一个要执行的worker是谁。
下面我们通过一个小例子来说明。如下图:

代码如下:
from bridgic.core.automa import GraphAutoma, worker
from bridgic.core.automa.args import System
class Sum100Automa(GraphAutoma):
@worker(is_start=True)
async def start(self, x: int) -> int:
return x
@worker(dependencies=["start"])
async def accumulate(self, x: int, rtx = System("runtime_context")):
local_space = self.get_local_space(rtx)
local_space["sum"] = local_space.get("sum", 0) + x
if x < 100:
self.ferry_to("start", x + 1)
else:
self.ferry_to("end", local_space["sum"])
@worker(is_output=True)
async def end(self, x: int) -> int:
return x
这段代码的逻辑很简单:先执行start这个worker,再执行accumulate这个worker。到此为止,这个编排逻辑还是静态的,使用dependencies参数来指定。而从accumulate开始,下一步调度哪一个worker,就是动态的了。下一步可能执行start,也可能执行end。如果下一步执行的是start,就开启一个新的循环;如果下一步执行的是end,就执行结束输出结果。
Bridgic在这里提供了一个API,称为ferry_to,允许像调用一个普通函数一样,来调度下一个执行的worker。这个API的设计哲学是:当需要表达动态逻辑的时候,直接使用代码或表达式,才是最自然的、也是能力最强的表达方式。它既能实现动态的路由,又能实现灵活的参数传递。由ferry_to触发的执行路径,在前面的拓扑图中,使用虚线箭头来表示。顺便说一句,ferry_to这个API名字的由来:ferry是「摆渡」的意思,当有向图的节点之间没有直接的边相连的时候,象征着从一个「孤岛」摆渡到下一个「孤岛」。
accumulate的代码实现了一个不断累加的逻辑,其中还用到了Local Space的特性,用于存储worker本地的状态(在这个例子中用于存储累加的和)。不过这个特性不是我们今天讲述的重点,先暂时略过。
虽然ferry_to看起来像个函数,但由于Bridgic是一个以异步编程为主线的框架(可以享受异步编程的好处),accumulate代码中对于ferry_to的调用,并不会真的在当前函数栈上去调用下一个worker的代码。实际上,对ferry_to的调用只是先创建一个延迟任务 (Deferred Task);等到event loop的下一次迭代,它所指定的worker才会真正被调度执行。这是Bridgic框架在实现编排调度时内部所采用的一个机制,保证了调度过程中发生的各种动态行为得以有序进行(在下面介绍动态拓扑时还会展开讨论)。
最后,我们把前面的Sum100Automa执行一下看看结果:
accumulator = Sum100Automa()
y = await accumulator.arun(x=0)
这个例子的代码,相当于执行0+1+2… 一直加到100。结果是y=5050。
在讨论真正的动态拓扑之前,我们先把动态编排这一部分的关键点总结一下:
- 声明式的
@worker和动态的ferry_to,这两种API可以配合使用。 - 借助
ferry_to,我们可以在图的编排层面实现出分支逻辑和循环逻辑。比如,在前面例子中,从accumulate动态ferry_to到start或end,就是个分支逻辑;而从accumulate动态ferry_to到start,然后再经由一个dependencies重新执行到accumulate,就形成了一个循环。 ferry_to的语义和静态的dependencies有很大不同。dependencies表示当前worker依赖的所有前置worker都执行完,当前worker才会执行;而ferry_to则表示,在event loop的下一次迭代中,它所指定的worker一定会执行(不管那个worker还有没有其他静态依赖)。正是这两种不同的语义相互配合,才呈现出一个动态编排的图景。
第三种:自主编排。
没法提前设想所有的可能情况,执行路径也需要根据执行动态现场确定。当软件开发来到了LLM时代,传统的确定性的编程与LLM带来的自主性特性相碰撞,对于程序的控制流带来了高度的动态性要求。在一个真正agentic的系统中,首先,LLM可以对任务进行规划,规划出来的步数和具体子任务的内容,都是提前不知道的;其次,一个agentic system在按照规划的步骤执行时,在执行过程中也会产生意外,从而改变后续的子任务列表。
具体到Bridgic的框架实现当中,自主编排这个情景相当于,有向图的拓扑是需要在执行过程中动态改变的。程序可能根据LLM的规划随时增删worker,甚至调整worker之间的依赖关系。
在未来的agentic system中,类似的自主编排的场景应该是非常多的。因为只有如此,LLM的潜力才能够最大限度地发挥出来,达到提高整个社会生产率的目的。在这里,为了讲解清楚,我先选择一个常见的动态工具选用的例子,来展示Bridgic对于动态拓扑的支持。
对于工具的选用,是任何一个agent loop的必不可少的一步。为了简单,下面的代码只展示其中最关键的工具选用这个子流程。如果你想参考一个完整的agent loop的实现,请到文末给定的链接下载ReActAutoma的代码。
在这个例子中,我们假定正在开发一个「旅行规划」智能体。我们提供给这个智能体以下三个工具可供调用:
get_weather(city: str, days: int):获取指定城市最近若干天的天气。get_flight_price(origin_city: str, destination_city: str):查询两个城市之间的航班机票价格。get_hotel_price(city: str, nights: int)::查询指定城市酒店住宿价格。
工具的实现代码先略过,假设这三个工具已经保存到了tool_list这个变量中(下面代码会用到)。
具体的工具选用过程,我们拆分成4步:
- 调用模型:把备选工具列表提供给LLM,让LLM输出工具调用信息
tool_calls。 - 动态创建worker:为前一步选出来的工具(可能是多个)创建worker。每个工具创建一个worker,并动态加入到DDG的拓扑中。
- 调用工具:由Bridgic框架自动调用这些工具(工具可以作为worker被调度执行)。
- 收集执行结果:工具执行的结果,由一个专门的worker来收集。这些结果只要转成
ToolMessage类型,就能发给模型做进一步的处理了,从而驱动一个agent loop的下一步得以执行。
为了介绍核心能力,下面仅贴出关键代码片段。TravelPlanner的完整可执行代码,请参考文末的下载链接。
class TravelPlanner(GraphAutoma):
@worker(is_start=True)
async def invoke_llm(self, user_input: str, tool_list: List[ToolSpec]):
tool_calls, _ = await llm.aselect_tool(
messages=[
Message.from_text(text="You are an intelligent AI assistant that can perform tasks by calling available tools.", role=Role.SYSTEM),
Message.from_text(text=user_input, role=Role.USER),
],
tools=[tool.to_tool() for tool in tool_list],
)
return tool_calls
@worker(dependencies=["invoke_llm"])
async def process_tool_calls(
self,
tool_calls: List[ToolCall],
tool_list: List[ToolSpec],
):
matched_list = self._match_tool_calls_and_tool_specs(tool_calls, tool_list)
matched_tool_calls = []
tool_worker_keys = []
for tool_call, tool_spec in matched_list:
matched_tool_calls.append(tool_call)
tool_worker = tool_spec.create_worker()
worker_key = f"tool_{tool_call.name}_{tool_call.id}"
self.add_worker(
key=worker_key,
worker=tool_worker,
)
self.ferry_to(worker_key, **tool_call.arguments)
tool_worker_keys.append(worker_key)
self.add_func_as_worker(
key="aggregate_results",
func=self.aggregate_results,
dependencies=tool_worker_keys,
args_mapping_rule=ArgsMappingRule.MERGE,
)
return matched_tool_calls
async def aggregate_results(
self,
tool_results: List[Any],
tool_calls: List[ToolCall] = From("process_tool_calls"),
) -> List[ToolMessage]:
tool_messages = []
for tool_result, tool_call in zip(tool_results, tool_calls):
tool_messages.append(ToolMessage(
role="tool",
content=str(tool_result),
tool_call_id=tool_call.id
))
# `tool_messages` may be used as the inputs of the next LLM call...
return tool_messages
def _match_tool_calls_and_tool_specs(
self,
tool_calls: List[ToolCall],
tool_list: List[ToolSpec],
) -> List[Tuple[ToolCall, ToolSpec]]:
matched_list: List[Tuple[ToolCall, ToolSpec]] = []
for tool_call in tool_calls:
for tool_spec in tool_list:
if tool_call.name == tool_spec.tool_name:
matched_list.append((tool_call, tool_spec))
return matched_list
agent = TravelPlanner()
await agent.arun(
user_input="Plan a 3-day trip to Tokyo. Check the weather forecast, estimate the flight price from San Francisco, and the hotel cost for 3 nights.",
tool_list=tool_list,
)
以上代码在执行过程中拓扑的变化,如下图所示:
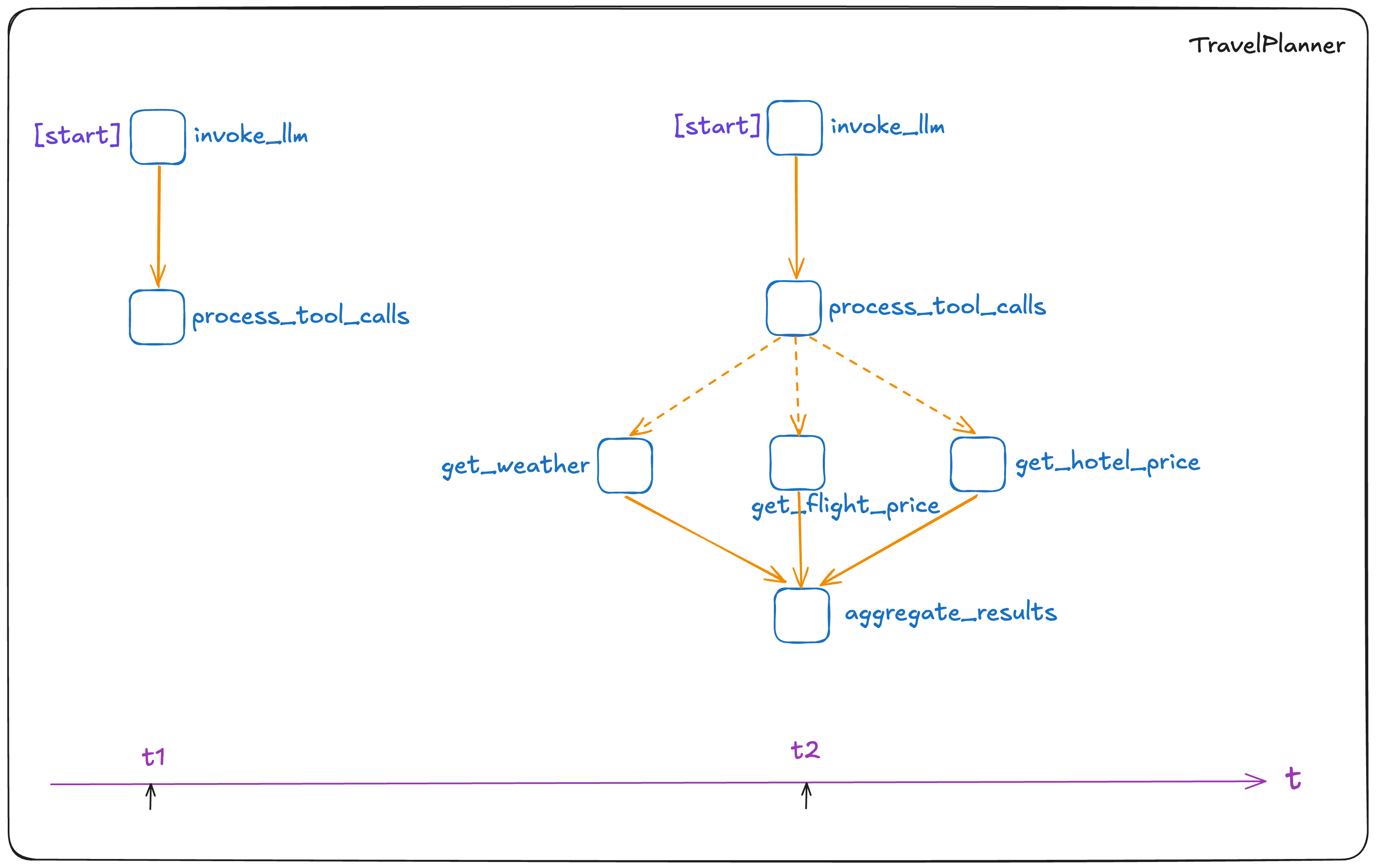
这次的代码片段比前面要复杂一些。我对其中的一些关键点做一下说明:
- 首先,动态拓扑是通过调用
add_worker和add_func_as_worker来实现的。在前面静态编排的部分,我们已经见过add_func_as_worker这个API了,但当时是在automa执行之前调用的。这里的调用时机就不同了,是在process_tool_calls这个worker的执行过程之中调用的。这就使得automa的拓扑可以随着运行过程动态改变了。 - 在
TravelPlanner的这段代码中,我们同时使用了静态编排的dependencies、动态编排的ferry_to,以及支持动态拓扑的add_worker和add_func_as_worker。所有这些API结合起来,得以将不同的自主性成分纳入到一个系统中。 - 执行动态拓扑操作的代码,都在
process_tool_calls这个worker中。它先是根据LLM返回的tool_calls信息匹配到了即将调用的工具列表,然后通过tool_spec.create_worker()为每个工具创建worker,调用add_worker把每个worker加入到DDG的拓扑中来。然后,它多次调用ferry_to,将这些worker在event loop的下一个迭代中调度起来。最后,它调用add_func_as_worker将aggregate_results这个worker也添加进拓扑中,并通过指定依赖关系让这个worker负责收集所有工具worker的执行结果。
另外,以上TravelPlanner的代码中还用到了Bridgic的一些其他特性,由于跟编排和动态拓扑没有直接关系,这里就简要说明一下(详细用法请参阅Bridgic官方文档):
- 各个worker的参数的值,如
tool_calls、tool_list、tool_results,由Bridgic特有的Parameter Binding机制来控制传递。 invoke_llm调用的llm.aselect_tool,涉及到Bridgic对LLM的抽象。这里采用了一种Facade设计模式,对于千差万别的模型特性(如StructuredOutput、ToolSelection)进行了更通用、也更简化的抽象。
综上,Bridgic在底层的Core API中提供了add_worker和add_func_as_worker等一系列API。这些API在初始建图时和运行时修改拓扑时保持了同样的行为,完全取消了建图后不必要的「编译」操作。这些API,再加上动态调度的ferry_to以及静态的dependencies依赖关系,让Bridgic在最底层的架构上就能够与各种不同动态性的编排模式相适应,向上提供了一种统一的编程视图。
DDG的调度原理
前面我们已经通过代码展示了Bridgic编排调度的能力。这些能力是由GraphAutoma所实现的动态有向图 (DDG) 在背后作为支撑的。现在我们就来拆解一下DDG背后的调度原理。
当GraphAutoma.arun()被调用的时候,内部就会开始调度worker执行。整个过程被分成若干个动态步 (Dynamic Step) ,简称为DS。Bridgic是一个以异步编程为主线的框架,就很自然地在event loop的每一次迭代中执行一个DS。具体参见下面的流程图。
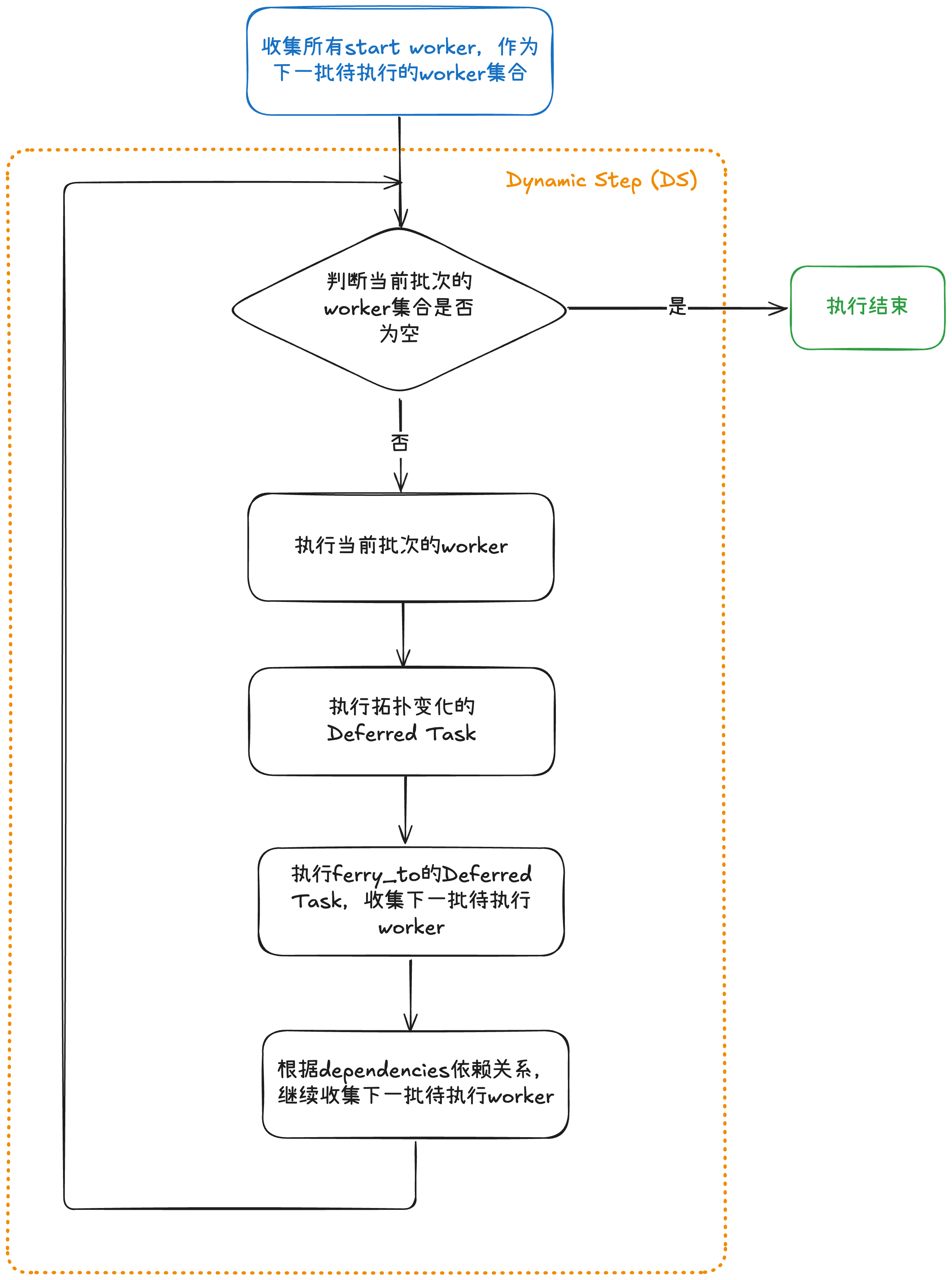
注意,为了方便理解,这个流程图只画出了最关键的部分。图中橙色虚线框的部分,就表示了一个DS内部的执行流程。
在“执行当前批次的worker”这一步,worker代码被执行,里面可能调用了ferry_to或add_worker。这些调用会创建出对应的延迟任务 (Deferred Task) 。这些Deferred Task在DS的末尾会被执行,它们的执行结果会在下一个DS的调度中生效(也就是对下一批执行的worker可见)。
正是异步编程、Dynamic Step、Deferred Task所有这些机制配合起来,使得DDG的动态拓扑和动态调度成为可能。
那些不美观的东西
软件架构和API的设计,也是一项美学。有时候,不同的设计原则会彼此矛盾,比如完备性和便利性。
看完上面的代码,可能有些对代码审美有要求的朋友会发现,在worker代码中穿插add_worker等调用,难免会有些「不自然」。至少没有调用ferry_to显得自然一些。
底层原理性的东西,不管它如何深入本质,也都需要在编程语言层面找到某种恰当的承载形式。但是,在使用编程语言所赋予给我们的便利时(比如Python的异步编程、decorator机制等),我们的表达能力,也受限于它的能力。不管怎么说,自主编排的特性是LLM时代带给我们的新的课题,传统的编程范式和编程语言可能目前还没有调整到最佳的姿态去应对。
这里我先做个预告,近期我们会在Core API的上层推出一个新的编程特性,尝试对Agent开发中的动态性、组件化有一个更好的描述。敬请期待。
源码下载
Bridgic源码地址 ➜ https://github.com/bitsky-tech/bridgic
Bridgic文档地址 ➜ https://docs.bridgic.ai/
ReActAutoma文档地址 ➜ https://docs.bridgic.ai/latest/reference/bridgic-core/bridgic/core/agentic/#bridgic.core.agentic.ReActAutoma
ReActAutoma源码地址 ➜ https://github.com/bitsky-tech/bridgic/blob/main/bridgic-core/bridgic/core/agentic/react/_react_automa.py
TravelPlanner源码和教程地址 ➜ https://github.com/bitsky-tech/bridgic/blob/dev/docs/docs/tutorials/items/core_mechanism/dynamic_topology.ipynb
一句话,Bridgic是一个支持动态拓扑、强调组件化编程的开源AI智能体框架,也是学习AI编程、学习Python编程和异步编程的一份参考代码,很值得一读。
觉得好的朋友可以给个star,表达下鼓励^-^
加入技术交流群
我新建了一个“Bridgic开源技术交流群”,后面会在群里发布项目的开发进展及计划,并讨论相关技术。感兴趣的朋友可以扫描下面的二维码进群。如果二维码过期,请加微信ID: zhtielei,备注“来自Bridgic社区”。

(正文完)
其它精选文章:
- 【开源】我亲手开发的一个AI框架,谈下背后的思考
- 一文讲透AI Agent开发中的human-in-the-loop
- AI Agent时代的软件开发范式
- 从Prompt Engineering到Context Engineering
- AI Agent的概念、自主程度和抽象层次
- 技术变迁中的变与不变:如何更快地生成token?
- 科普一下:拆解LLM背后的概率学原理
- 企业AI智能体、数字化与行业分工
- 分布式领域最重要的一篇论文,到底讲了什么?
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-bridgic-dynamic-topology.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。

最新文章
- 为什么agent和workflow可以融合在同一个架构里?
- 万字长文!两栖模式构建Agent,与OpenClaw/Hermes不一样的解法——开源AmphiLoop
- Claude Managed Agents意味着什么?
- 【开源】专为「探路+编码」范式设计的全新浏览器工具集+Skills
- 不用手写一行代码,10分钟立等可取,爬取twitter和github动态
- 使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
- 过年了,聊聊AI和人文
- 使用Bridgic长程自主模块+MCP,控制你的浏览器
- AI智能体纪元或将从2026开始归零
- 从Python异步编程的剖析中体会智能体并发编程模式