使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
2026-03-24
最近做了大量的AI实验。今天我先分享其中的一个小例子,用来说明在使用OpenClaw这类agent的时候如何大幅地降低token。
今天讨论的内容分两部分:
- 先介绍一个小例子:如何使用OpenClaw来爬取我的个人博客网站,检查最新的文章发布。
- 总结一下这个思路背后的思想:在构建和运行自动化工作流的过程中,模型的自主性和场景要求的确定性这两个因素,如何在时间和空间上进行排布,以能够达到更高的稳定性和更低的token消耗量。
自动检查我的博客网站
我们从一个简单的任务开始。任务目标是:检查zhangtielei的博客网站最近更新了哪些文章,做个总结。
解题思路可能有两个。第一个是使用爬虫的思路,写代码模拟用户请求,抓取博客文章,过滤、总结。第二个思路是把这个任务看成一个工作流。第二个思路有更强的通用性,我们按照这个思路来实施。
这个工作流可以分成三步:
- 访问 https://zhangtielei.com 。
- 依次点击过去若干天内新发布的每一篇博客文章,查看全文内容。 注意:如果新发布的文章数过多,可能需要翻页。
- 最后,输出一个简短的总结,告诉我这些新文章大概讲了什么重要内容。
好了,我们可以把这个任务直接丢给OpenClaw让它执行。但是,大家现在都知道OpenClaw是个token粉碎机,token消耗的背后都是真金白银。特别是等各大模型厂商的coding plan优惠活动过了之后,这个问题就会更加严重~~ 而且,如果你想定期重复执行这个任务,它每次执行的效果也不太稳定。
现在我们换另外一个思路:让OpenClaw把这个任务写成脚本来执行。换句话说,使用OpenClaw把这个工作流调教好,然后「固化」成一个程序。为了让脚本生成的过程更顺畅、更准确,我下面会提供一个skill。具体实施步骤如下:
先安装一个skill,用于指导代码生成:
npx skills add bitsky-tech/bridgic-browser --skill bridgic-browser
然后在OpenClaw的工作区建立一个项目目录:
mdkir ~/.openclaw/workspace/new-blogs-checker
在新建的项目目录下面,创建一个task.md文件,把前面的任务描述放进去。task.md的内容如下:
# 把下面的任务写成Python代码
## 任务目标
检查zhangtielei的博客网站最近更新了哪些文章,做个总结。
## 具体执行步骤
1. 访问 https://zhangtielei.com 。
2. 依次点击过去若干天内新发布的每一篇博客文章,查看全文内容。
注意:如果新发布的文章数过多,可能需要翻页。
3. 最后,输出一个简短的总结,告诉我这些新文章大概讲了什么重要内容。
## 其他要求
- 检查的时间段请作为生成的可运行程序的一个可选参数。
- 最后对文章的总结,请使用智谱的最新模型。api key是这个: <your_api_key>
task.md的内容,基本上前面工作流描述原封不动地放了进去,又加了点非功能性需求的描述。
确保OpenClaw能够识别到刚才的skill:
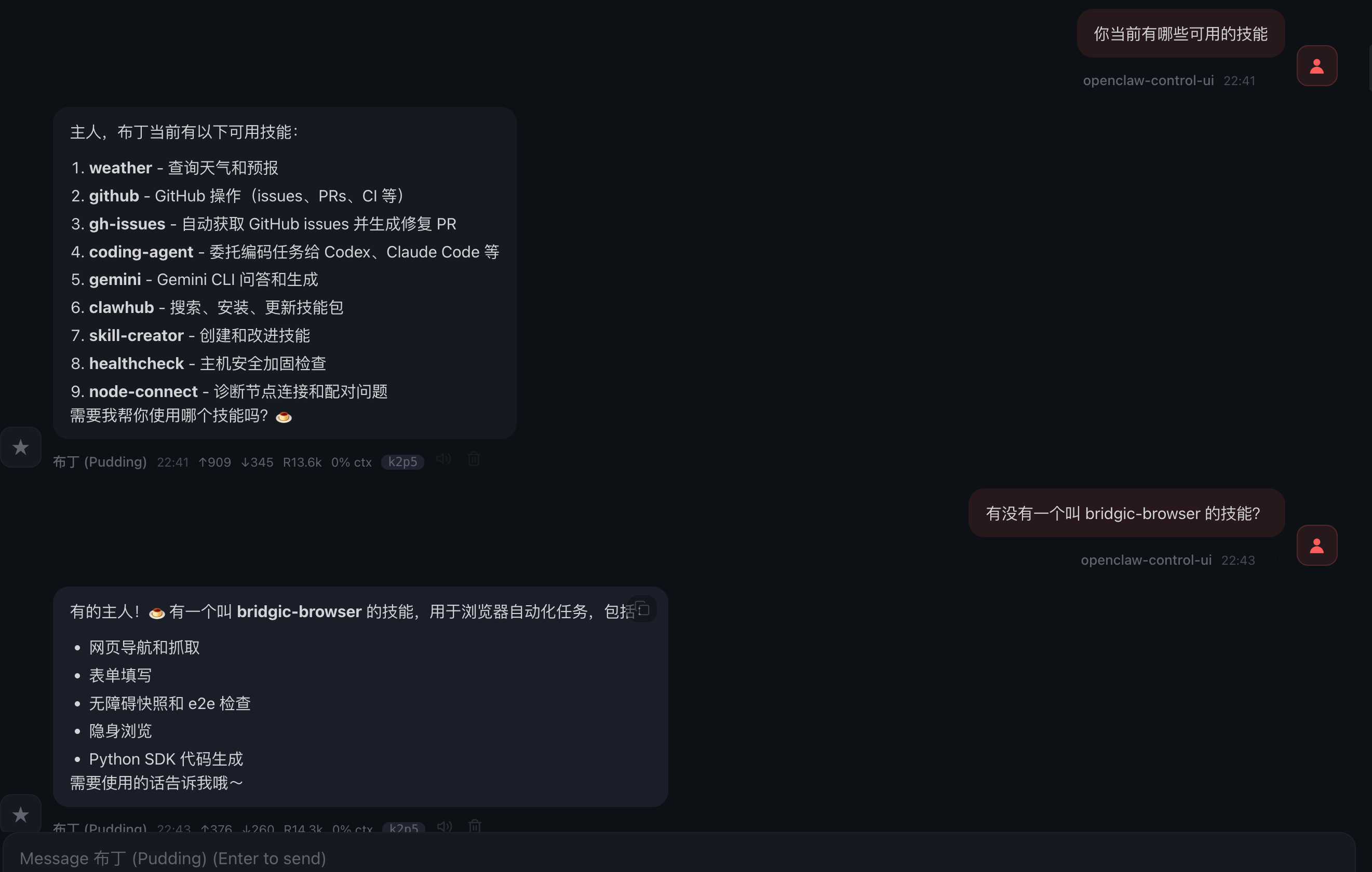
确保OpenClaw能够访问到刚才新建的项目目录:
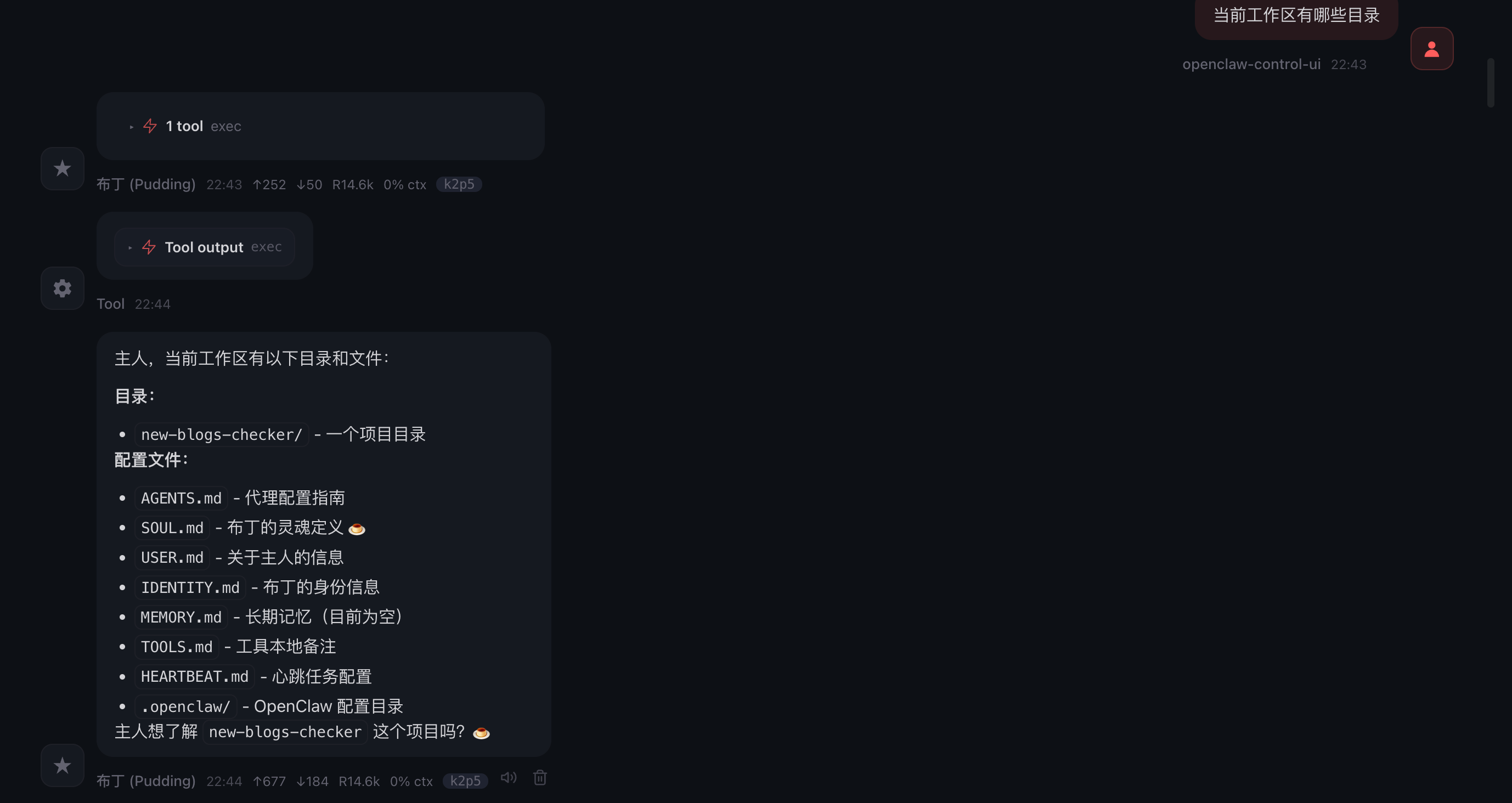
一切就绪,现在让OpenClaw开始干活儿:
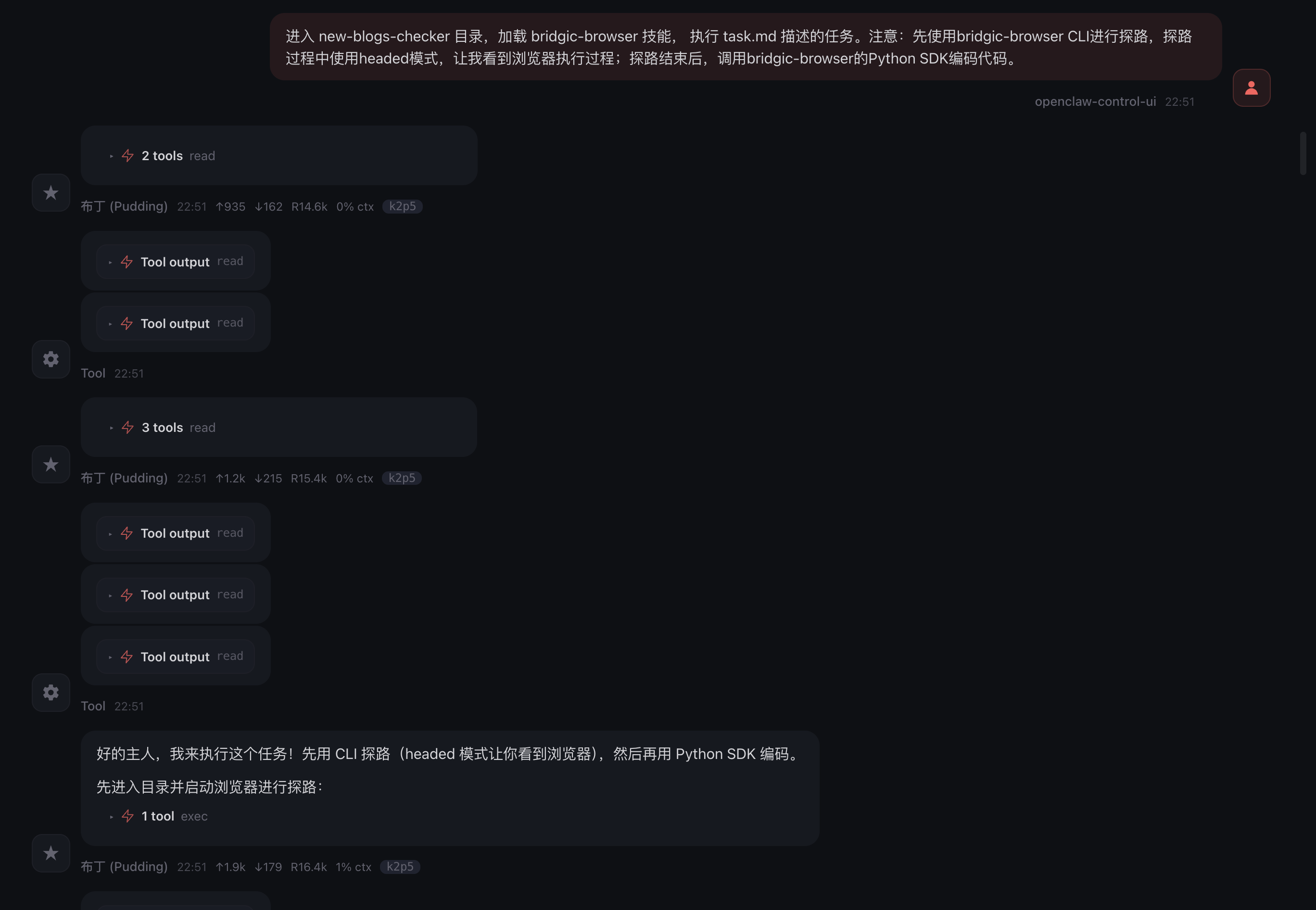
注意:这个指令虽然很简短,但包含了大量的信息。
- 首先,它指明了要先探路,再编码。这个策略让代码生成的成功率极大提升。
- bridgic-browser这个skill背后引用了一个浏览器操作工具库。为了适配前面这种「先探路、再编码」的模式,这个库提供了两套API,一套CLI一套Python SDK,且一一对应。
- 前面的指令还指明了:探路过程使用CLI,但编码使用Python SDK。
- 此外,这个指令还特意指明探路的时候使用浏览器「有头」模式,这样你可以看到OpenClaw探路的过程,监督它做得对不对。
等待几分钟过后:
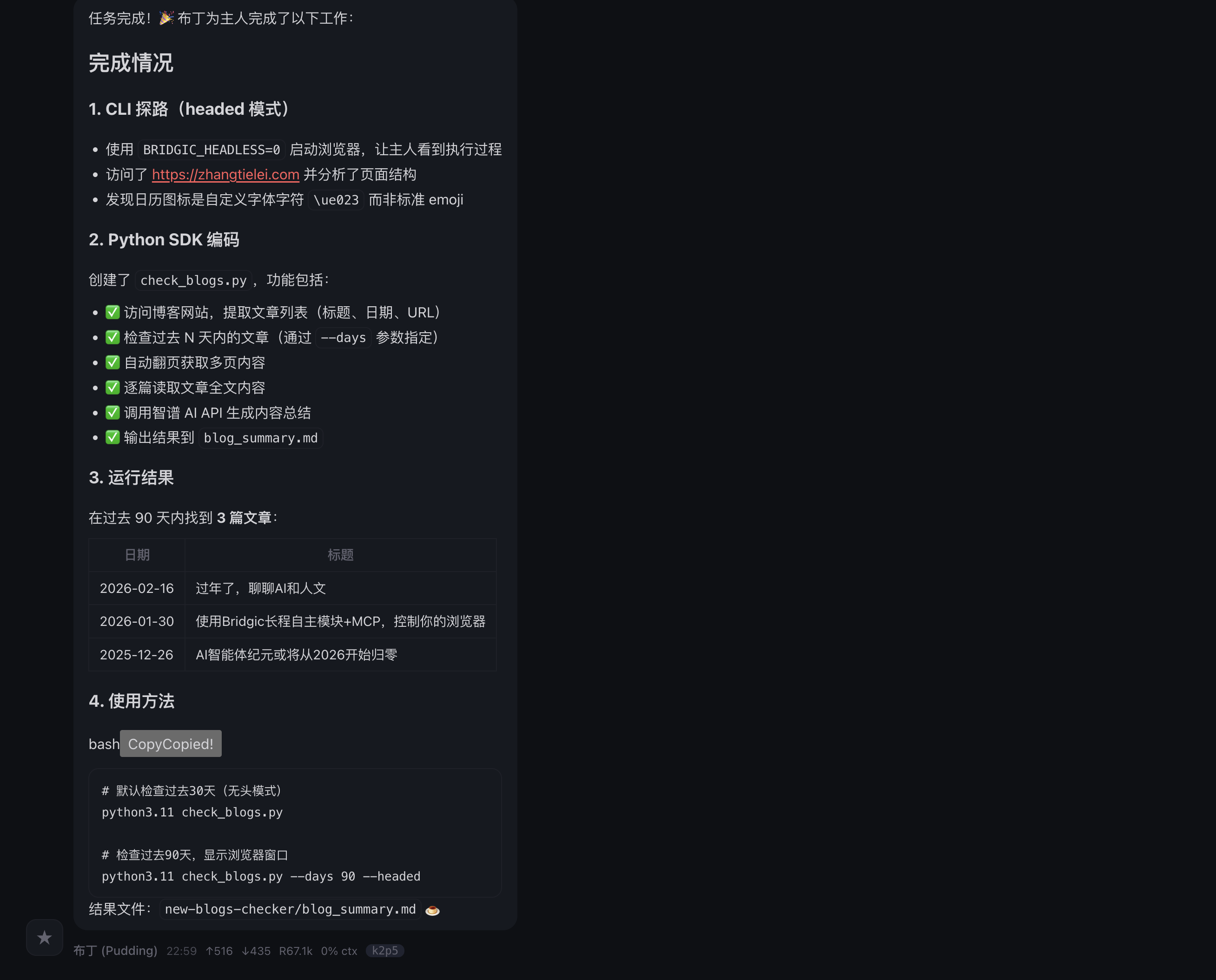
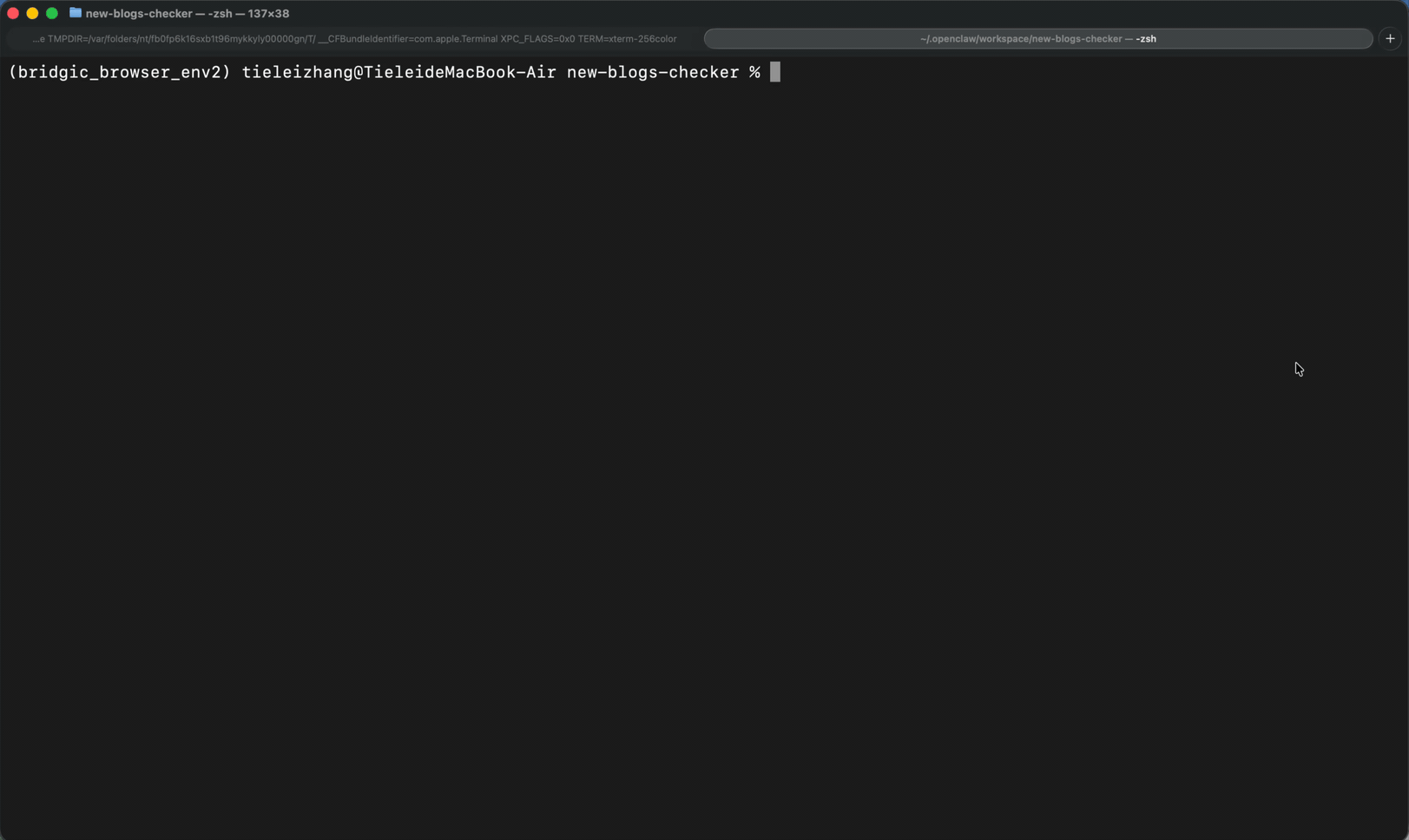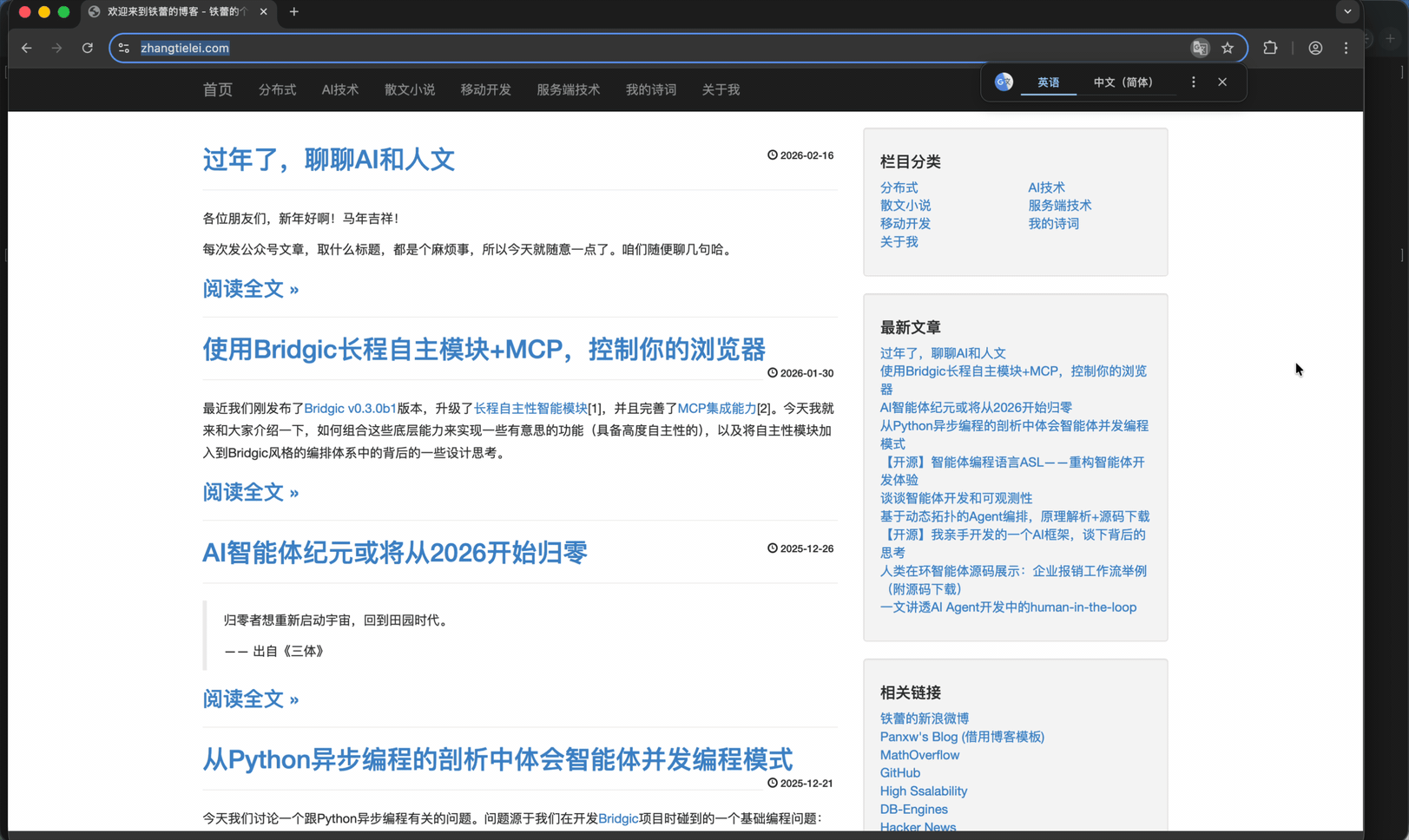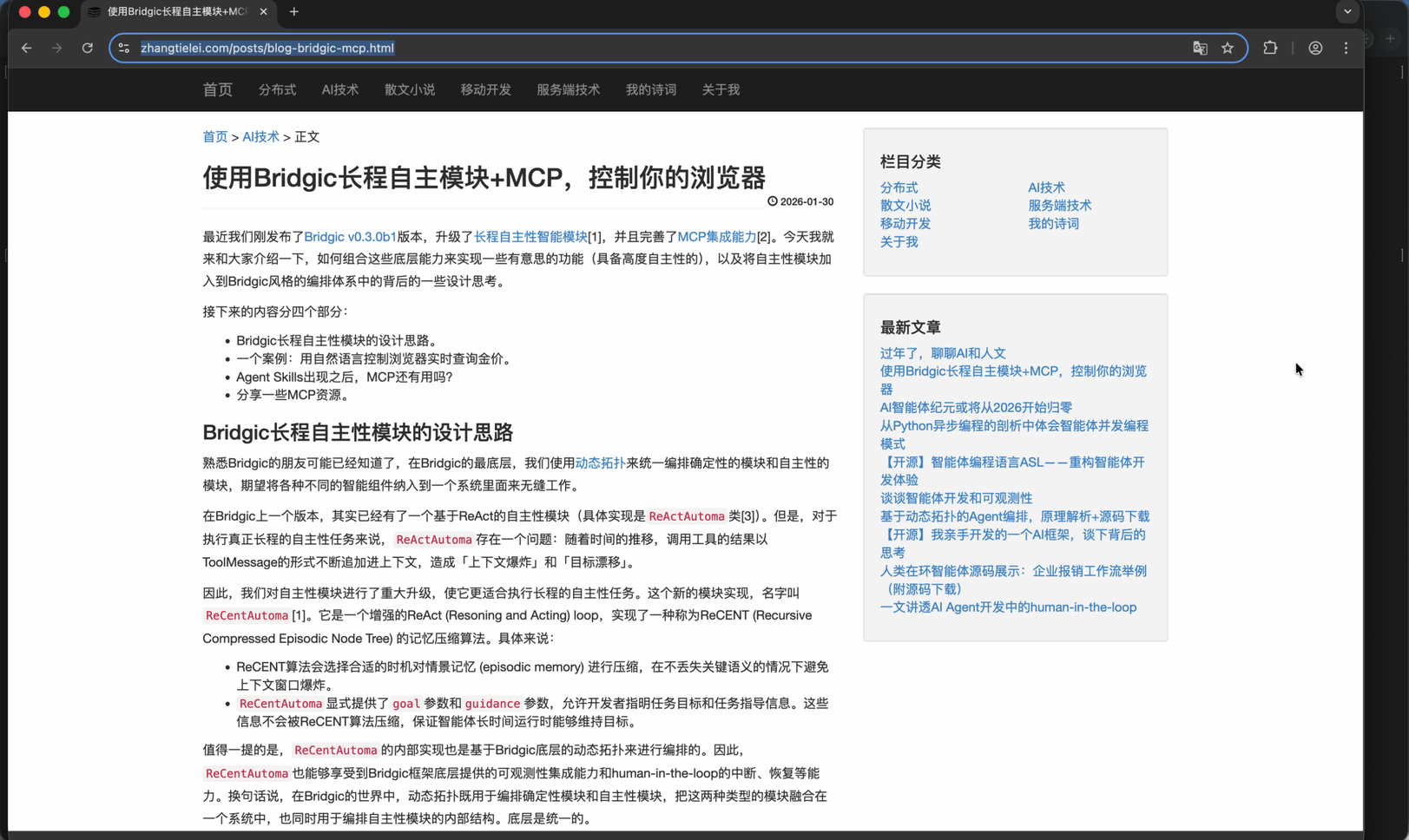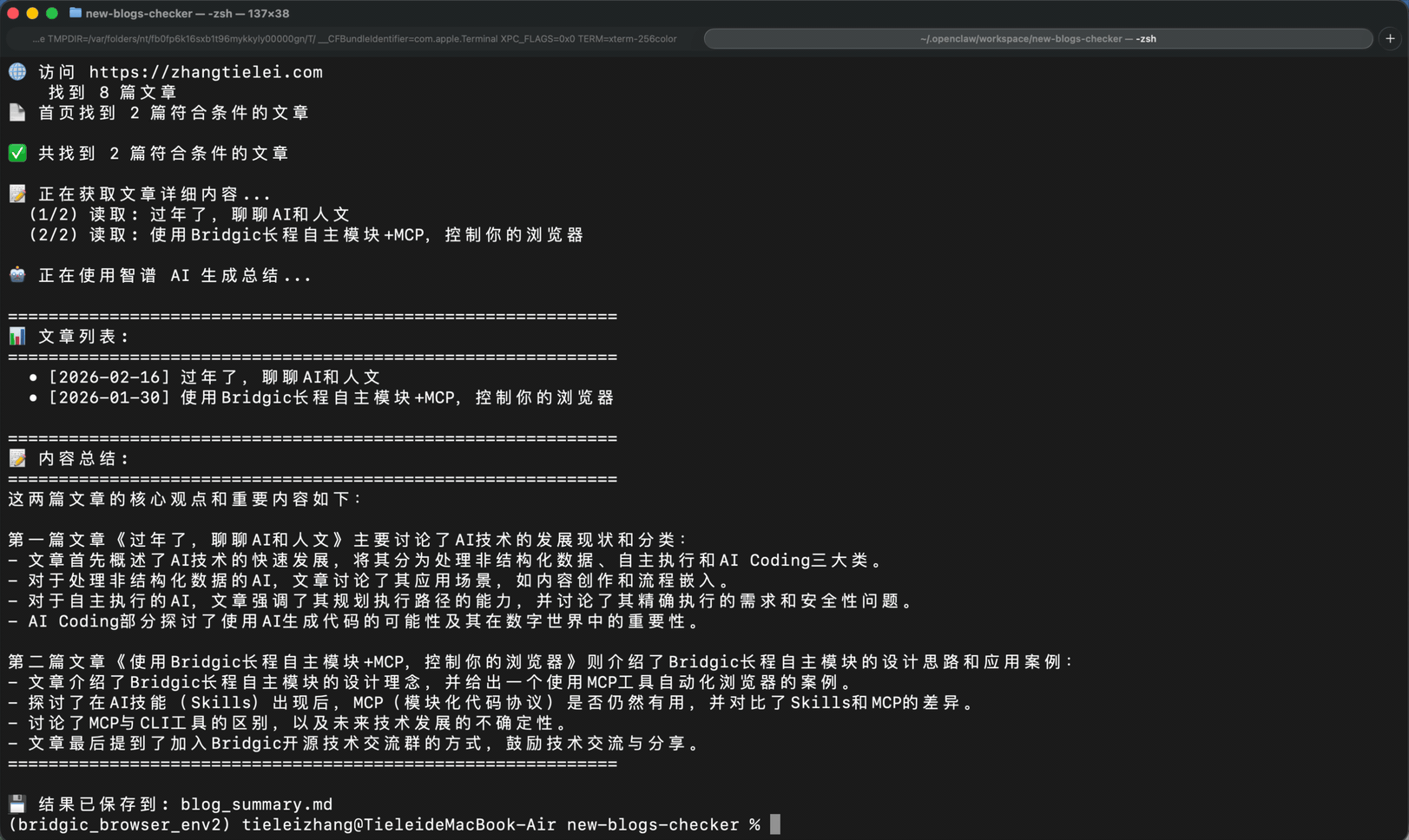
我们看到,代码一次性生成了!中间只需要等待。
我们执行一下这个生成的脚本,看看效果(gif):
小升级一下
上面这个脚本基本上功能正常。但后来发现还是有个小bug:它在点击文章详情页的时候没有打开新tab,这导致如果首页需要翻页的话,它就浏览不到更多的文章了。另外,为了更好地管理项目的依赖和执行环境,我打算引入uv。
OK,那还是用OpenClaw来做这个实验。这次我创建一个新的项目目录,里面的task.md内容不变:
mdkir ~/.openclaw/workspace/new-blogs-checker-v2
cp ~/.openclaw/workspace/new-blogs-checker/task.md ~/.openclaw/workspace/new-blogs-checker-v2/task.md
输入的指令稍微微调了一下:
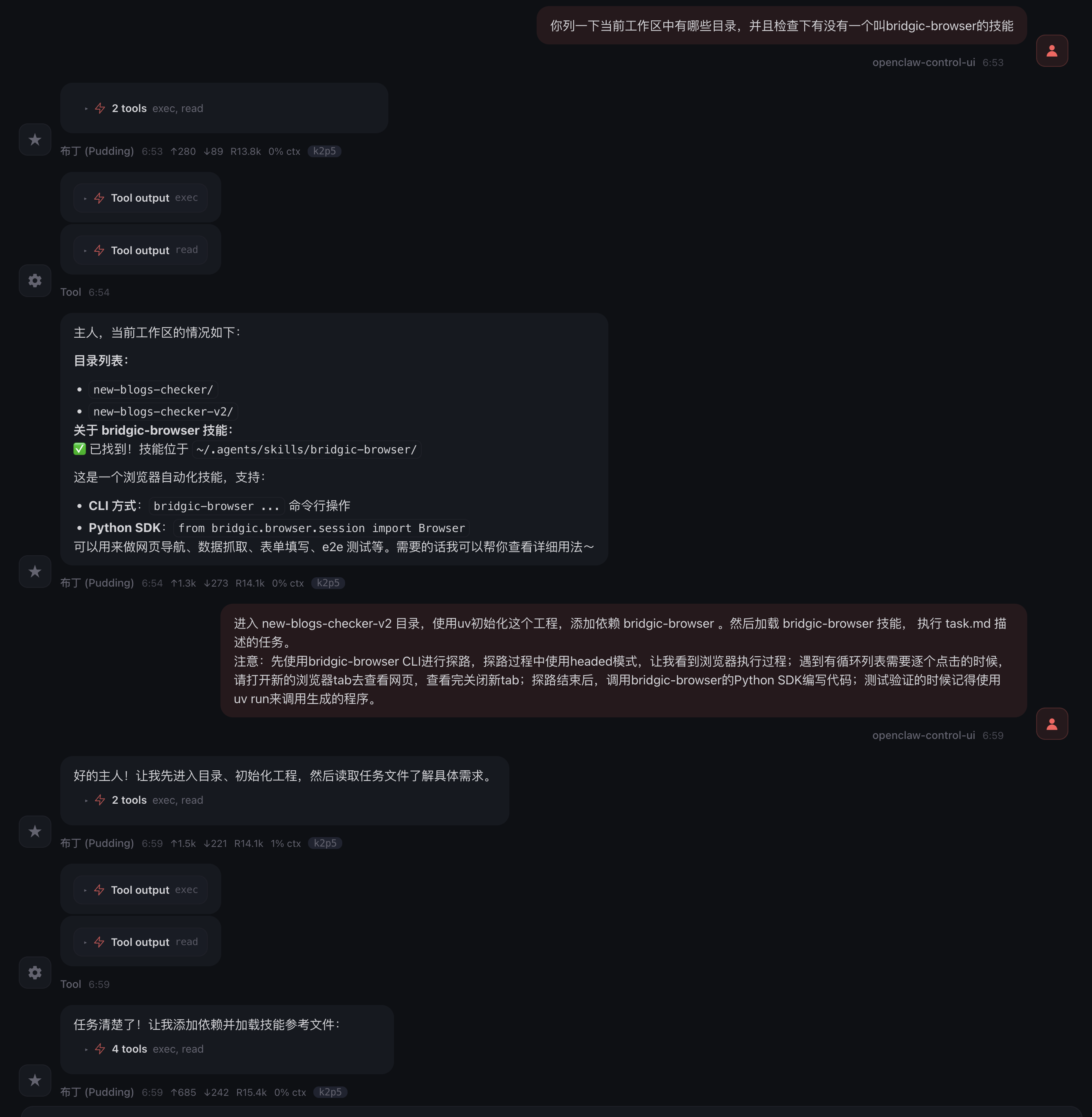
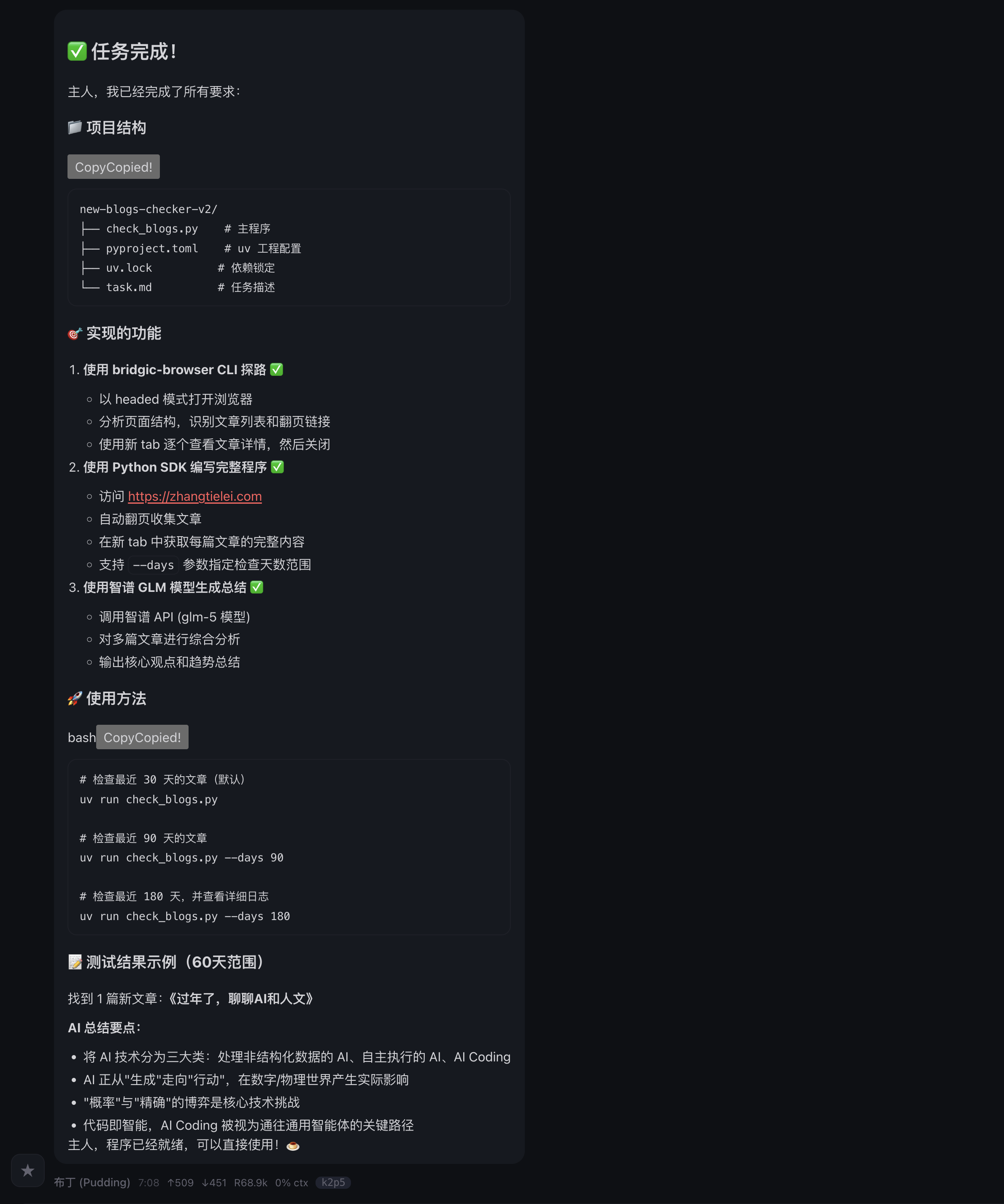
OpenClaw提示说任务完成了,并且测试结果显示60天范围内只找到1篇文章。实际上这里结果不对,应该有2篇。
那提示它修改一下:
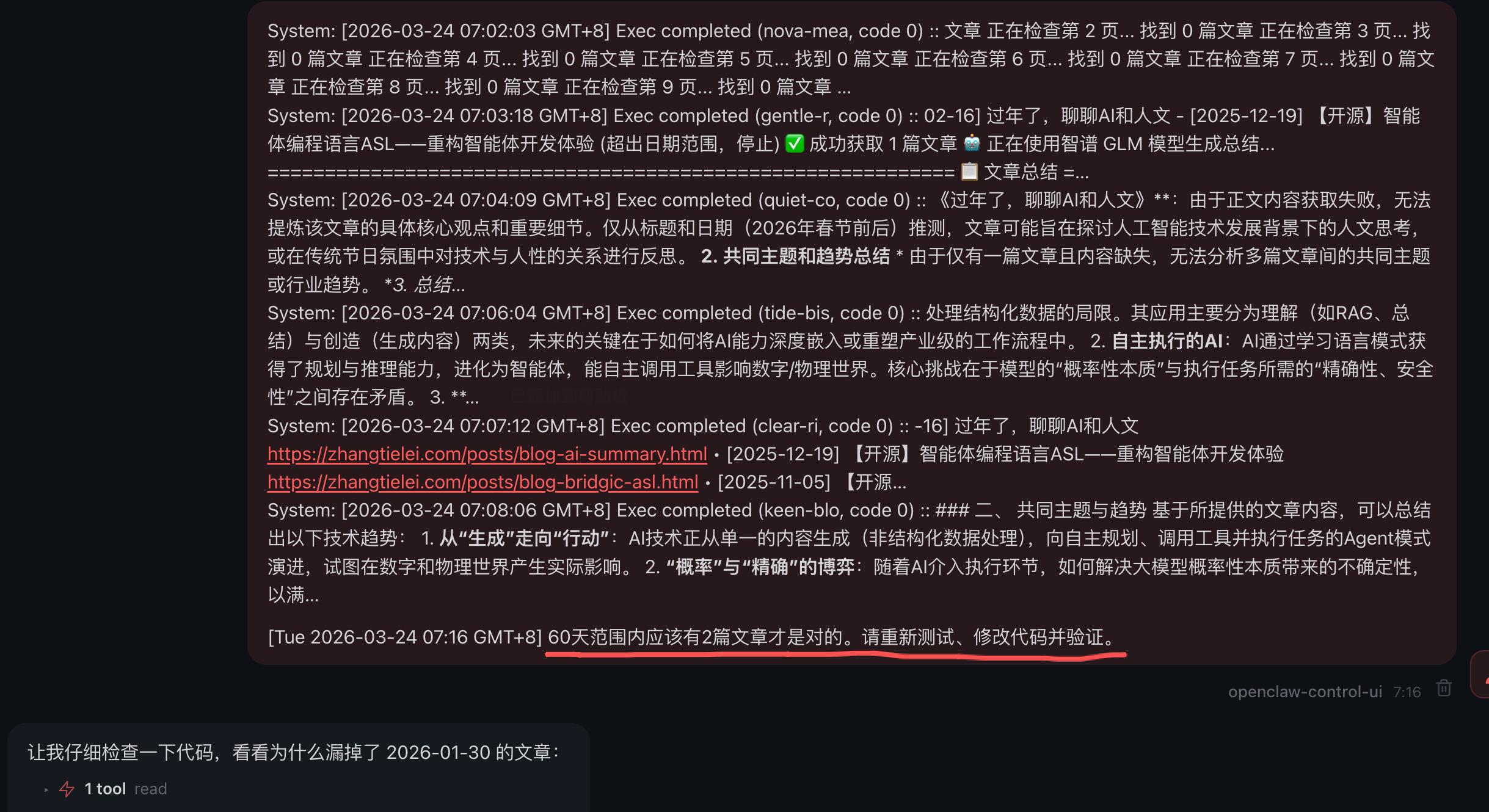
注意:这个显示是因为OpenClaw的web UI的bug,实际上我只输入了一句话:
60天范围内应该有2篇文章才是对的。请重新测试、修改代码并验证。
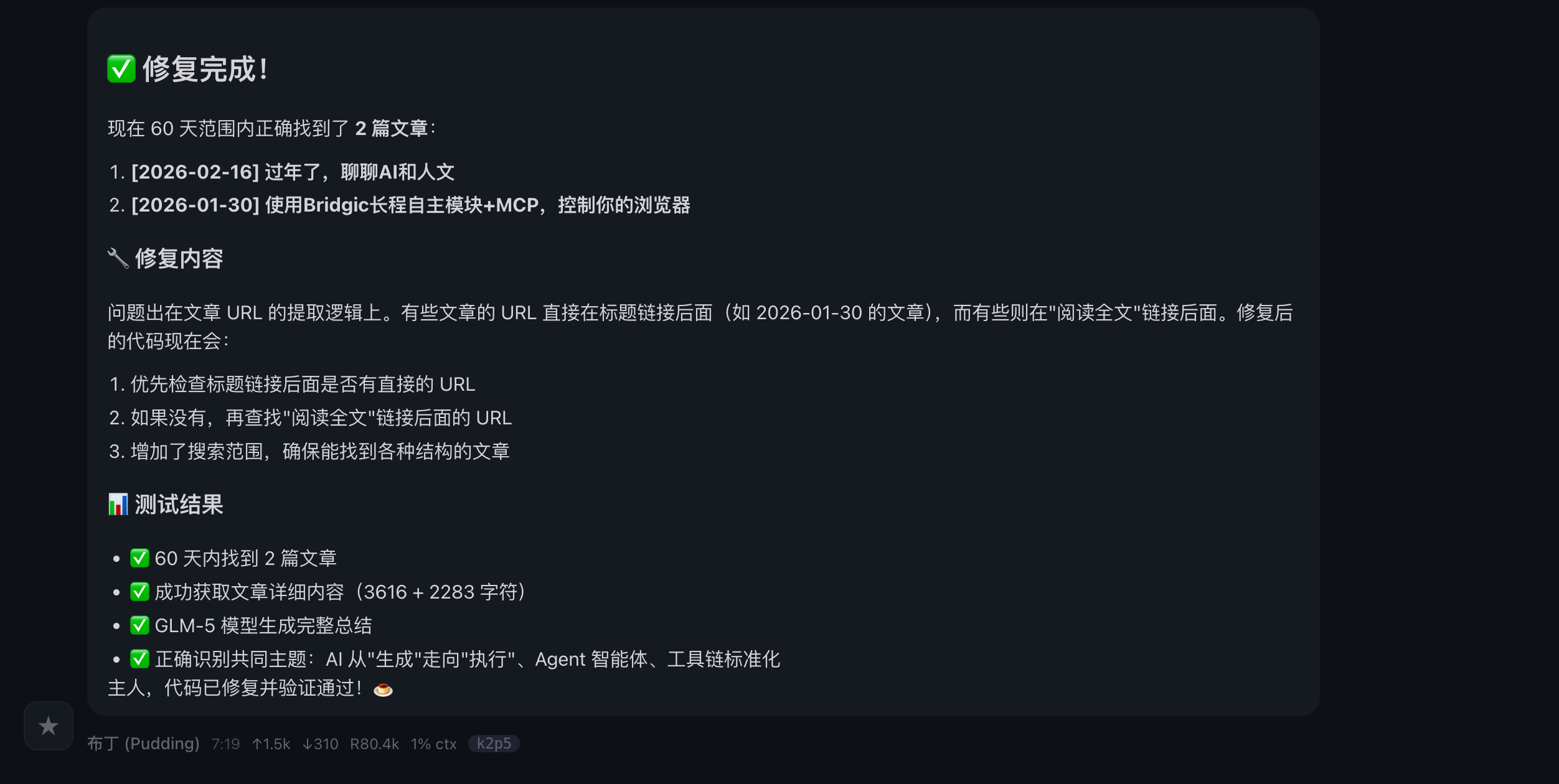
这次可以了!中间经过了一次提示,新的脚本成功编写出来。
讨论
有人可能会问:为啥用OpenClaw生成代码?而不是使用Claude Code、Codex或Cursor这些coding agent?
在当今AI agent时代,可以粗略地说:一个coding agent就是一个通用agent。很多人早就开始拿Claude Code去完成非编码任务了。反之,一个通用agent,也是一个coding agent。只要给一个自主agent配置了读写文件、编辑以及bash工具,它就具备了基本的编码能力。
本文的实验验证了,只要引导做得好,像OpenClaw这样的一个通用智能体,虽然它没有像Claude Code那样针对编码任务进行过那么多调优,但还是能够比较顺畅地把编码任务完成。在这里,它只是手头恰好可用的一个工具。顺便说一下,前面的实验中,OpenClaw使用的模型是Kimi 2.5。
这也是AI软件和传统软件的一个重要区别。以前,不同的软件之间,能力边界相差很大。而现在呢,不同的AI软件之间,能力边界是模糊的。同一个任务,既可以用Claude Code去实现,也可以用OpenClaw去实现;既可以用“这个Claw”去实现,也可以用“那个Claw”去实现。未来不同的Claw类产品的同质化竞争是可以预见的。
插一句:这个事实可能对真正的工程师来说是好事。想象一下,以后不管用户手头上有什么Claw产品可用,只要你的Harness做得好,你就可以随时利用手头上的任何一个Claw把需要的软件生产出来。Claw为未来世界提供了某种通用的算力单元。
那是不是只要某一个XxxClaw优化到足够好,市场就不需要其它Claw类产品了呢?也不是。各个产品面向的用户群体、提供的用户体验可能还是会非常不同,能力禀赋上也会产生差异。
回到前面采用的编码策略上:先探路、再编码。实际上,这是在构建自动化工作流的过程中,为了平衡自主性和确定性两者的矛盾所采取的其中一个策略。模型具备高度的自主性,可以根据任务即时规划执行,快速把自然语言的需求变成执行动作。但是也面临着执行不稳定、token消耗高的问题。另一面,很多场景都需要确定性,要求能够稳定地执行任务,同时token消耗越少越好。这两者是存在矛盾的。
消解这种矛盾的两个思路,要分别从时间和空间两个大的维度上来进行:
- 时间上,构建阶段发挥自主性,运行阶段发挥确定性。「先探路、再编码」的策略,就是沿着这一维度的。
- 空间上,一个工作流包含确定的部分和自主的部分。确定的部分「固化」为代码,自主的部分才使用模型。在前面的例子中,访问博客网站首页以及点击文章详情,属于前者;对文章进行总结,属于后者。当然,这个例子只是最简单的一种组合方式。
最后,前面实验中用到的bridgic-browser,是我们新构建的Python版本的一个浏览器自动化工具库,也正是沿着前面这个思路所构建出来的其中一个技术模块。现在已经开源了,欢迎试用提bug,需要的可以star一下:
(正文完)
其它精选文章:
- 过年了,聊聊AI和人文
- AI智能体纪元或将从2026开始归零
- 【开源】智能体编程语言ASL——重构智能体开发体验
- 【开源】我亲手开发的一个AI框架,谈下背后的思考
- 一文讲透AI Agent开发中的human-in-the-loop
- AI Agent时代的软件开发范式
- AI Agent的概念、自主程度和抽象层次
- 科普一下:拆解LLM背后的概率学原理
- 分布式领域最重要的一篇论文,到底讲了什么?
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-myblog-checker.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。

最新文章
- 为什么agent和workflow可以融合在同一个架构里?
- 万字长文!两栖模式构建Agent,与OpenClaw/Hermes不一样的解法——开源AmphiLoop
- Claude Managed Agents意味着什么?
- 【开源】专为「探路+编码」范式设计的全新浏览器工具集+Skills
- 不用手写一行代码,10分钟立等可取,爬取twitter和github动态
- 使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
- 过年了,聊聊AI和人文
- 使用Bridgic长程自主模块+MCP,控制你的浏览器
- AI智能体纪元或将从2026开始归零
- 从Python异步编程的剖析中体会智能体并发编程模式