不用手写一行代码,10分钟立等可取,爬取twitter和github动态
2026-03-30
把语言转变为行动。这是AI时代的一项超能力。
这次的AI技术革命,本质上是在解决长尾需求的。这也决定了AI工具不会像工业革命时代的电灯泡一样,只需要一个简单的「开关」就能控制。
目前市面上AI工具的产品设计,也呈现出两个极端。一个极端是Claude Code,它就像一台精密的仪器,光说明书就好几百页,只有专业人士才能操控。另一个极端是OpenClaw,它就像一把威力巨大的电锯,普通人也能拿过来挥舞两下子(有时候用起来还真不赖),但其中也隐藏着随时可能失控的风险。
因此,如何降低AI使用门槛,让这种新技术走近更多真实场景,在今天是一个前所未有的、崭新的问题。承接上一篇实验,今天我分享另一个实验,也是朝着这一思路迈进一步。
TL;DR
- 依照「直觉」,把原始任务拆解为适当长度的子任务。这个过程就像“把大象装冰箱总共分三步”一样简单和自然。
- 每个子任务的自动化程序,要能够在大约10分钟之内由Claude Code生成。
- 生成过程追求一气呵成,整个过程几乎不需要专业指令的引导。
- 跟OpenClaw不一样,生成的自动化程序几乎消耗零token,还能够重复稳定运行。
- 把Claude Code作为一种「通用的AI计算单元」,编排进自动化工作流中。复用你已经订阅的Claude Code算力,不额外多花token。
需求描述
在上一篇实验中,我介绍了如何制作一个脚本检查我的个人博客网站(zhangtielei.com)。今天的实验复杂一些:我们来追踪一下Andrej Karpathy的个人动态,首先看看他在中期的时间维度上(最近几个月)在研究什么方向,其次再看看最近几天(短期)他在关注什么、发表过什么言论。
【解题思路分析】
我们可以把这个问题直接扔给ChatGPT,但只能得到一个相对宽泛、既不及时也不完整的答案。实际上,要想比较精准地完成这个任务,就需要先做一下调查研究,然后量身定做我们的自动化程序。经过调查发现,Andrej Karpathy有一个个人网站,3个blog地址,还有一个YouTube channel,但是这些至少半年都没有更新了。Karpathy保持频繁活跃的地方,主要是两个:一个是twitter (x.com), 一个是GitHub。
容易想到,我们的解题思路大概是这样的:
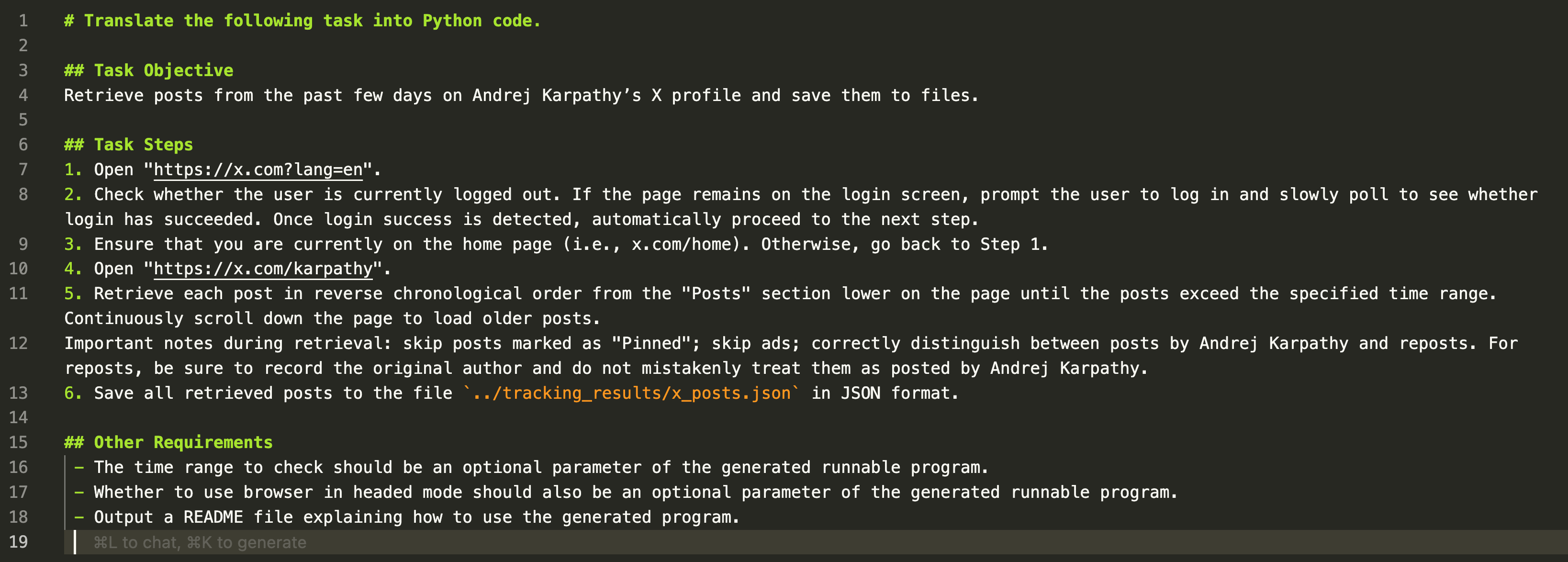
- 翻看Karpathy在X上的个人主页(需要登录才行)。
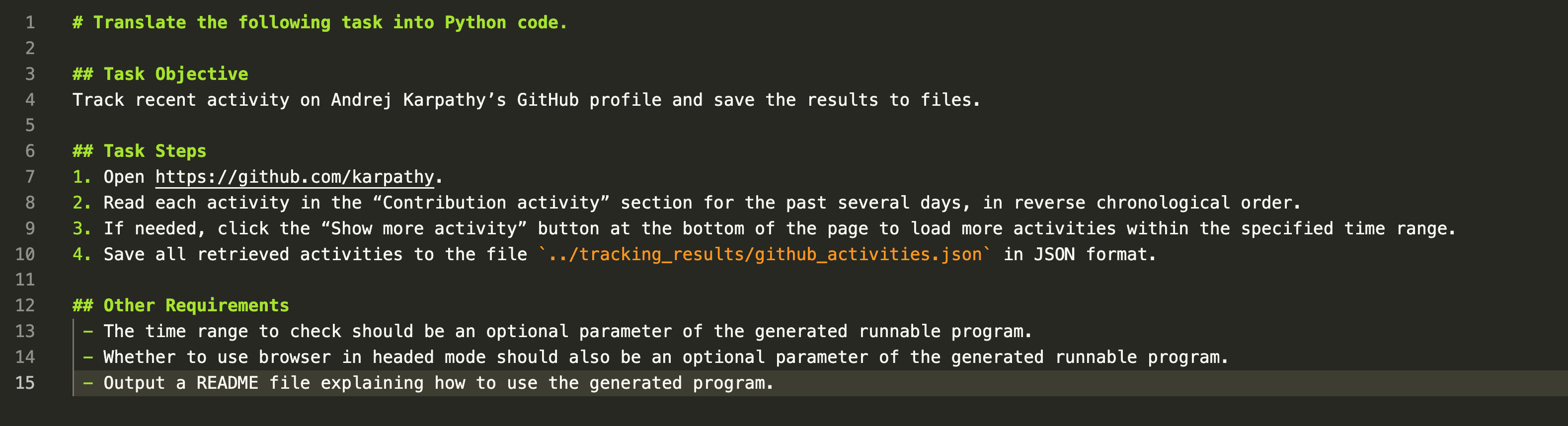
- 翻看Karpathy在GitHub上的个人动态。
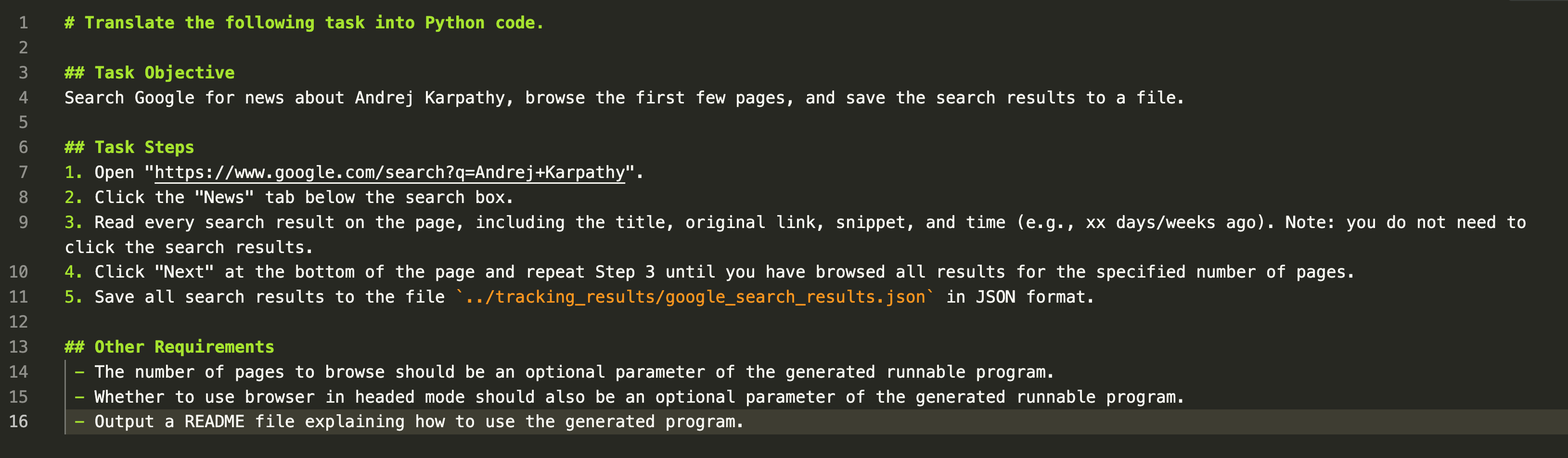
- 使用Andrej Karpathy作为关键词在Google的News频道进行搜索(作为信息补充)。
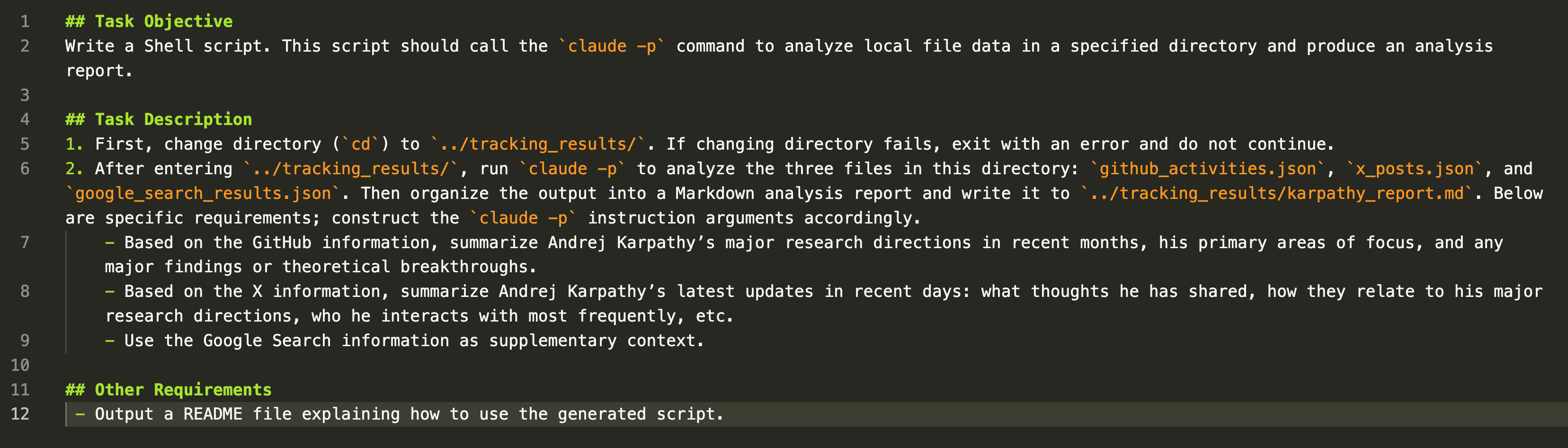
- 基于前三步获取到的信息写一个分析报告。这一步可以直接调用Claude Code来完成(使用
claude -p)。
【X主页截图】
![]()
【GitHub主页动态截图】
![]()
【Google新闻搜索截图】
![]()
根据这个解题思路,原始任务也自然地拆解成了4个子任务。我们分别把这4个子任务用自然语言细化描述出来,并各自写在一个名叫task.md的文件里。
【追踪X主页的task.md】
【追踪GitHub动态的task.md】
【追踪Google搜索动态的task.md】
【调用Claude Code写报告的task.md】
每个task.md单独放在一个目录里。目录结构如下:
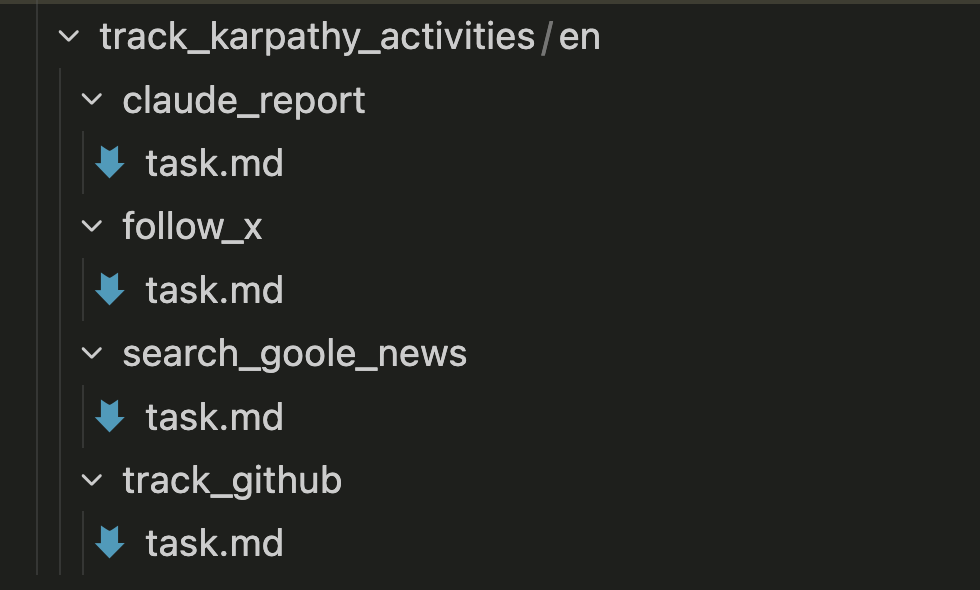
源文件下载链接:
https://github.com/bitsky-tech/bridgic-examples/tree/main/browser-automation-examples/track_karpathy_activities/en
实现方法
【安装Skill,引导代码生成】
npx skills add bitsky-tech/bridgic-browser --skill bridgic-browser
【执行各个task.md】
分别进入各个task.md所在的目录,执行如下命令(对每个任务都一样):

然后只需要跟着Claude Code提示,一路按1或2,放行各种执行权限即可。中途不需要做任何的主动指令输入。Claude Code会在Skill的引导下安装环境、探索网站结构、编码脚本代码、测试验证,并初步修复bug。大概等待10分钟左右,基本整个过程就能结束:
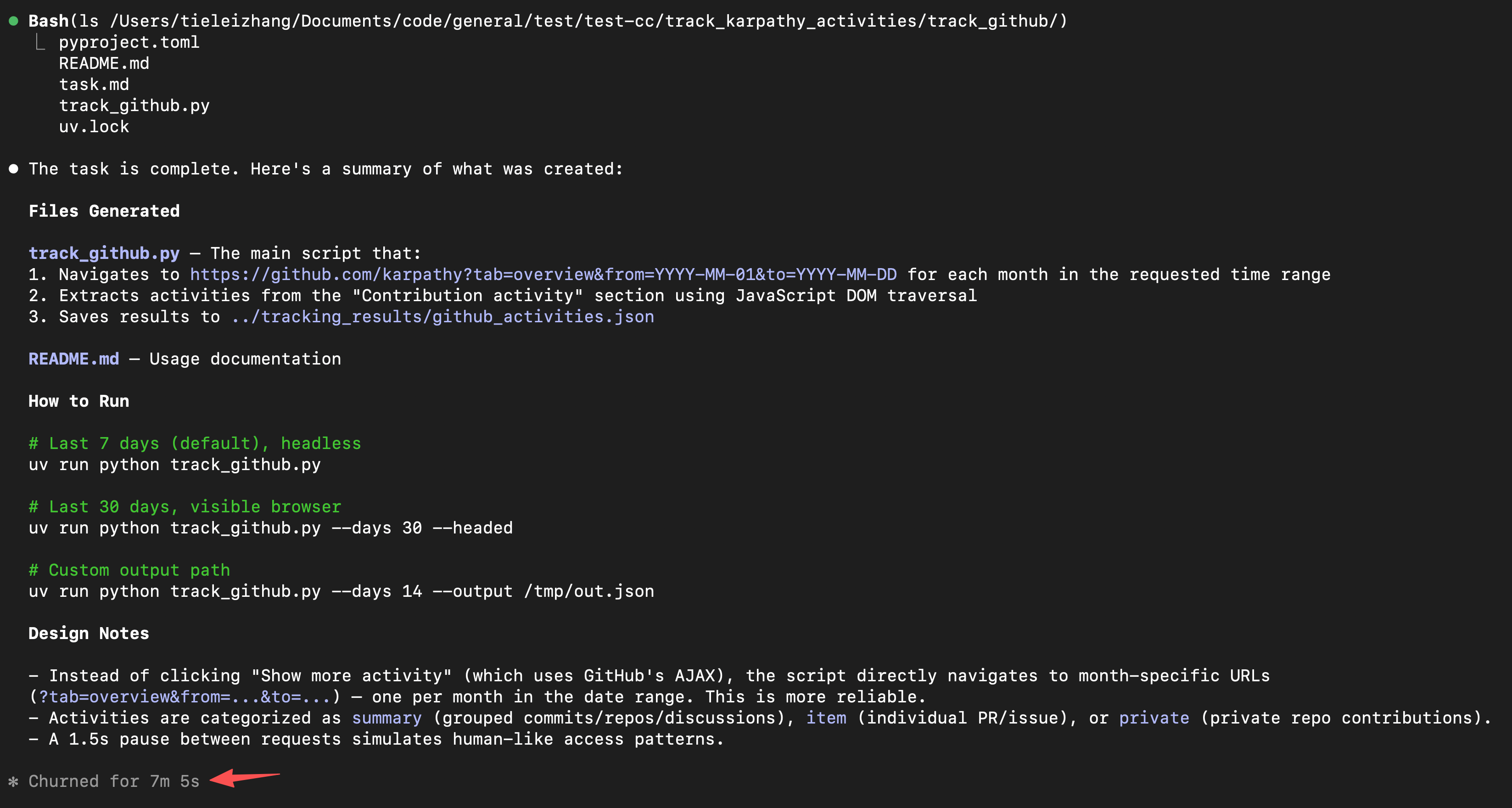
针对每一个子任务,都如法炮制(注意claude_report这个程序最后生成)。最后claude_report目录下生成的脚本,会调用本机上的Claude Code去写一个分析报告。写出来的报告类似下面的样子(一个全方位的解读):
小结
把语言转变为行动。这是AI时代的一项超能力。
这项能力要想让大众获得,并没有想象得那么简单。把话讲明白,本来也不是一件简单的事儿。有人说,得靠好的「Harness」。说实话,我不太喜欢这种宽泛的概念。把无处安放的东西,一股脑塞进一个概念里,这本来就起到了制造混乱的效果。
本文继承了上一篇「先探路、再编码」的思想,主要展示了如何针对复杂的任务以自然语言的形式进行拆解。这是解决复杂问题的第一步。
子任务拆解的粒度,很多时候都是「显而易见」的。在浏览器的自动化任务中,一个子任务基本对应了一个真实人类用户去完成某个有意义的操作所需要的步骤。它一般不会太长,个位数的操作步骤一般都能完成(排除列表循环),否则只能说明网站本身的产品设计过于晦涩。这也大致说明了为什么一个「自然拆分」的子任务能够使用Claude Code在8~12分钟内完成所有生成动作(且是一次性、一个session搞定)。这个例子是针对浏览器自动化的,但我们相信对于其他的自动化场景也同样适用。
最后,前面实验中用到的bridgic-browser,是我们新开源出来的Python版本的一个浏览器自动化工具库,也正是沿着前面这个思路所构建的其中一个技术模块。目前正在飞速迭代中(昨天刚发布了v0.0.2版),欢迎试用提bug,需要的可以star一下:
(正文完)
其它精选文章:
- 使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
- 过年了,聊聊AI和人文
- AI智能体纪元或将从2026开始归零
- 【开源】我亲手开发的一个AI框架,谈下背后的思考
- 一文讲透AI Agent开发中的human-in-the-loop
- AI Agent时代的软件开发范式
- AI Agent的概念、自主程度和抽象层次
- 科普一下:拆解LLM背后的概率学原理
- 分布式领域最重要的一篇论文,到底讲了什么?
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-karpathy-tracker.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。

最新文章
- 为什么agent和workflow可以融合在同一个架构里?
- 万字长文!两栖模式构建Agent,与OpenClaw/Hermes不一样的解法——开源AmphiLoop
- Claude Managed Agents意味着什么?
- 【开源】专为「探路+编码」范式设计的全新浏览器工具集+Skills
- 不用手写一行代码,10分钟立等可取,爬取twitter和github动态
- 使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
- 过年了,聊聊AI和人文
- 使用Bridgic长程自主模块+MCP,控制你的浏览器
- AI智能体纪元或将从2026开始归零
- 从Python异步编程的剖析中体会智能体并发编程模式