给普通人看的机器学习(一):优化理论
2020-01-18
我们要想把一件事情做好,最首要的是有一个明确的目标。比如,很多公司都会给员工制定KPI (Key Performance Indicator),这就是为了给人们的工作指明方向和目标。这个目标不仅是明确的,而且很可能是量化的(即包含具体的数字指标)。
从逻辑上讲,达成任何事,都可以分成两个步骤:
- 制定目标;
- 执行。
第1步,关键是保证目标正确(方向错了一切都白搭);第2步,关键是找到正确的执行策略,也就是目标的解法(光有目标却实现不了,也是白搭)。
上面的逻辑步骤,如果放在机器学习领域,仍然成立:
- 制定目标。任何实际的问题,如果想用机器学习的思路来解,那么首先要把这个实际问题转述成一个机器学习问题。一个机器学习问题,是有非常明确且量化的求解目标的。从宏观来看,机器学习的目标可以表述成:让模型预测的结果与实际数据之间的差异最小化(即错误率最低)。这个目标必须达到能够用数学公式来表达的明确程度。
- 执行。也就是对于上面用数学公式表达出来的目标进行求解。通常来说,这个过程其实就是通过训练来确定模型参数的过程。
上面第1步中,类似这种「让XXX最小化」的问题,可以用数学上的「优化问题」来表述。也就是说,经过上面第1步,一个机器学习问题,就转化成了一个数学问题。而第2步,就是对这个数学问题求解的过程,这个求解过程,由一个完善的数学分支——优化理论来支撑。
本文的目标就是要解释清楚这个优化理论的大致脉络。
优化是普适行为
无论是在自然界和人类社会中,还是在人类建造的系统中,优化都是一种普遍存在的行为。下面是一些例子:
- 在一个隔绝的系统中,大量分子相互作用,最终会达到所有电子总势能最小化的状态[1]。物理系统总是趋向于向着能量最小的状态演化,这是自然界的优化过程。
- 投资者不断优化投资组合,以追求收益的最大化。
- 一个城域交通系统,追求的是整个城市交通输送效率的最大化。
- 线上广告系统,追求的是整个系统对于广告投放的ROI (收入减去成本) 的最大化。
在我们的日常工作中,也经常会碰到「优化」问题。比如,在项目中如何做到投入资源最少,却取得最大的收益?一个推荐系统,如何让转化率最大化?一个用户流量分发系统,如何让触达用户的效率最高?
所有这些例子,都可以抽象成数学上的优化问题来描述。按照维基百科的解释,下面这几个概念是等同的:
- 优化 (Optimization)
- 数值优化 (Numerical Optimization)
- 数学优化 (Mathematical Optimization)
- 数学规划 (Mathematical Programming)
在数学上,它们都可以表示成从备选集合中选出最佳元素的过程[2]。我们接下来统一使用「优化」这个词汇。
举一个简单的例子,假设我们有一个目标函数:
f(x) = 2x2 + 8x + 11
现在要求使 f(x) 最小,那么x取值应该是多少?这就是一个优化的例子。如果用公式来表达这个优化目标,应该表示成:
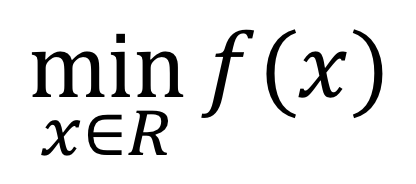 或
或 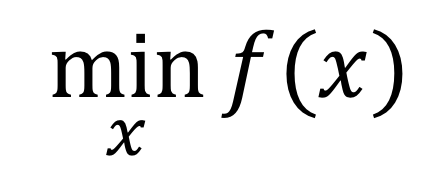
上面这个式子表示,x是自变量,取值可以在整个实数域R上变化。而问题的目标是:找到使得 f(x) 达到最小值的x的值是多少。
假设 x* 是该优化问题的解,那么可以表达成:

在这个例子中,f(x)的表达式比较简单,我们根据中学的数学知识就知道它是一个开口向上的抛物线。如下图所示:
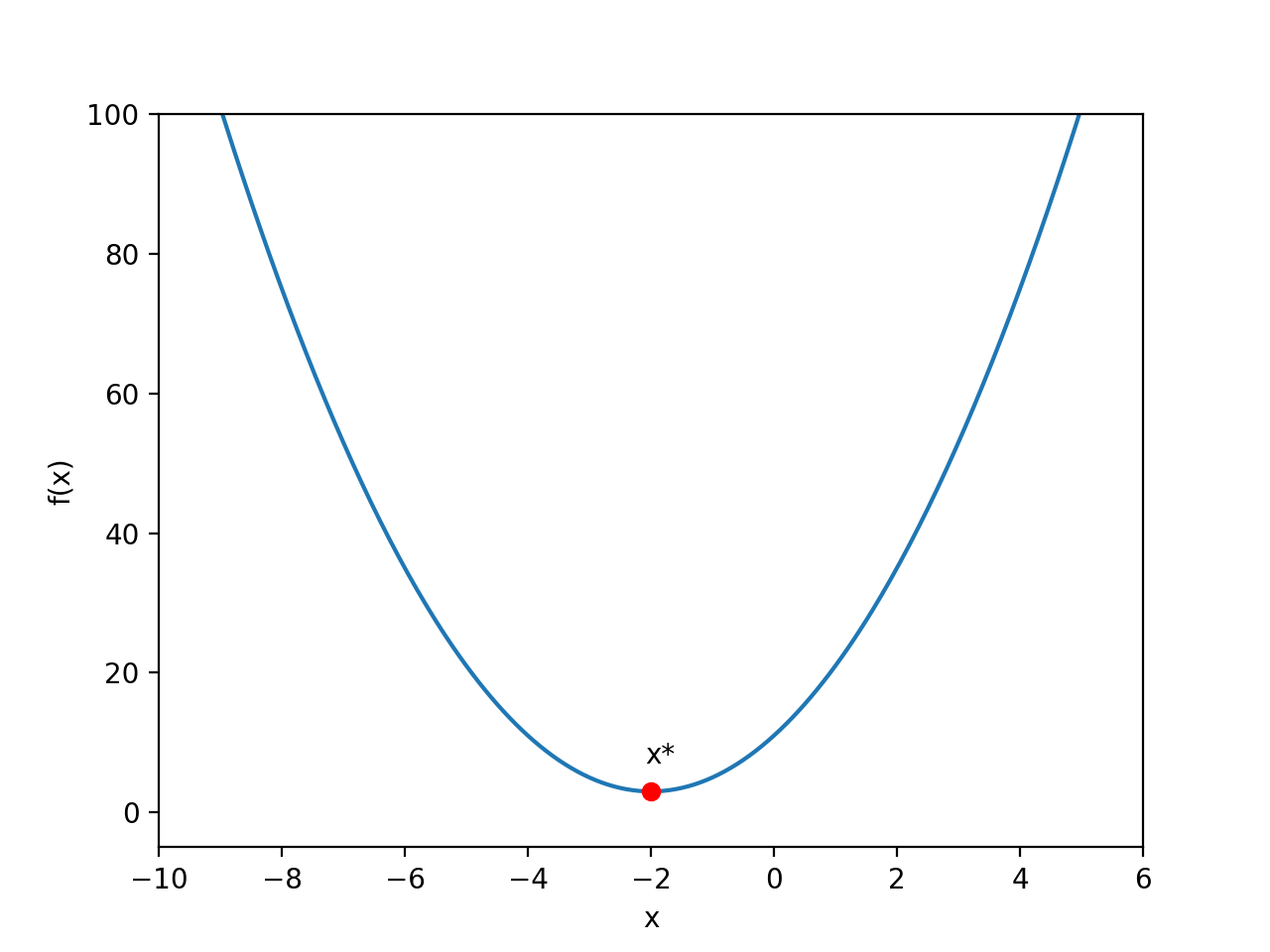
从上面的函数图像很容易看出来,使得 f(x) 取最小值的点就是图中的红点,即:
x* = -2
那么,这个解是通过怎样的计算过程得到的呢?我们知道,一个连续函数在极值点的导数为零,可以利用这个特性来求解:
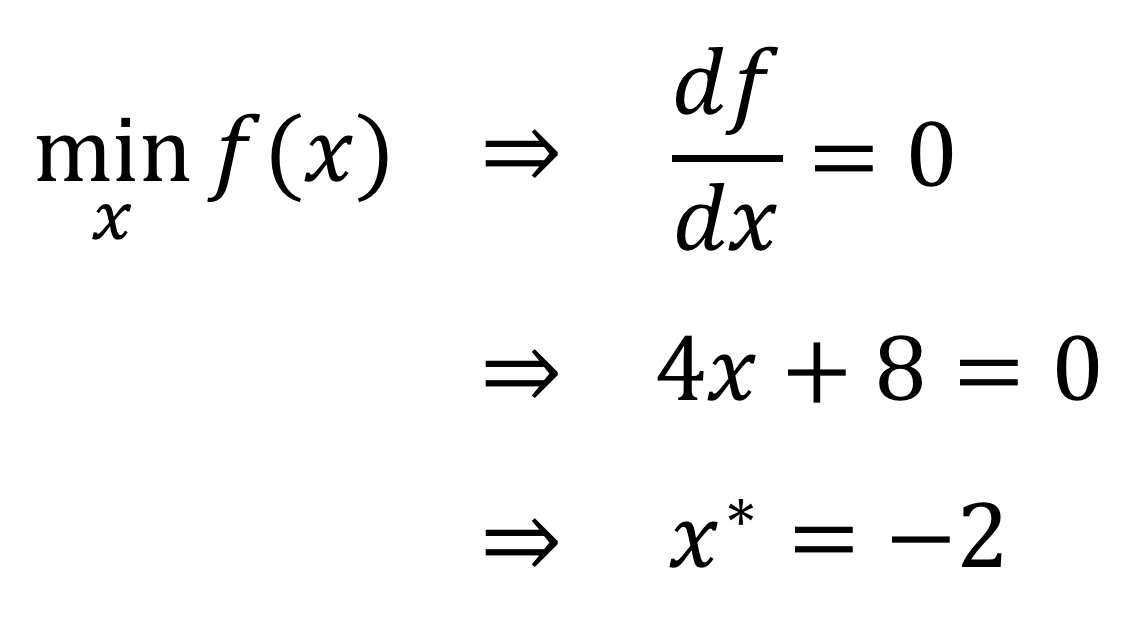
由于这个目标函数比较简单,所以我们很容易通过计算和推导得到了问题的解。这种通过严格的数学推导能够得到的解,可以称为解析解 (analytical solution)或闭式解 (closed-form solution)。
前面的抛物线只是一个例子。优化问题的一般形式[1],可以用下面的公式表达:
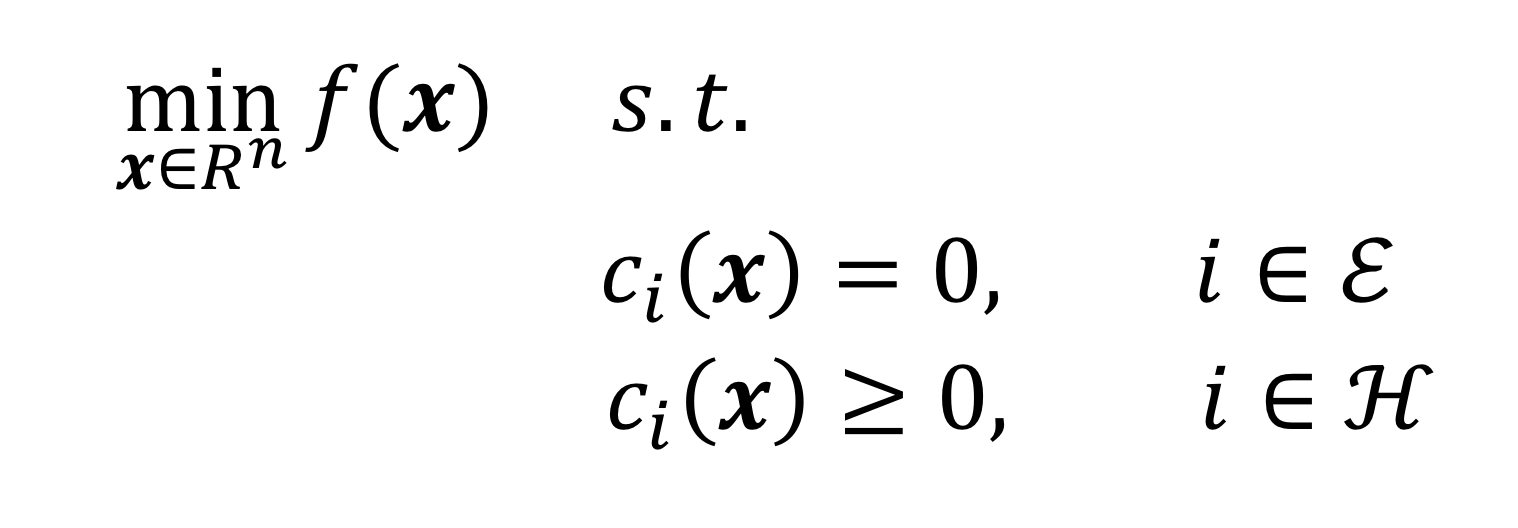
这个数学表达式的含义是:
- x是n维向量{x1, x2, …, xn}T,表示自变量;
- f(x)是优化的目标函数,它是n元函数的形式;
- ci表示约束函数,它们定义了自变量x必须遵守的等式条件或不等式条件。当然,一个优化问题也可以不包含任何约束条件。
迭代
对于实际中的优化问题,并不总是能得到闭式解。主要由于两个原因:
- 实际中的目标函数通常都非常复杂,根本求不出闭式解;
- 优化问题通常是需要借助计算机来求解的,而计算机虽然善于做数值计算,却不善于做公式推导。
因此,解决优化问题的通用算法一般都是基于「迭代」的思路,通过一步一步的近似计算,逐步逼近真实的解。
迭代算法一般都是类似这样的过程:
- 给定自变量的一个初始值x0;
- 从初始值出发,算法一步一步地迭代,每次都在n维空间中移动一小步。这样就形成了一系列迭代的变量值:x1, x2, …, xk, xk+1, … 最终逐渐接近真实的解x*。
(注意这里的每个迭代值xk,都是一个n维向量,所以用黑体字型来表示)
在迭代算法中,有一个关键的问题需要解决:在从第k步向第k+1步迭代的时候,如何决定往哪个方向移动?显然,根据前面我们对优化问题的定义,应该往目标函数变小的方向移动,即:
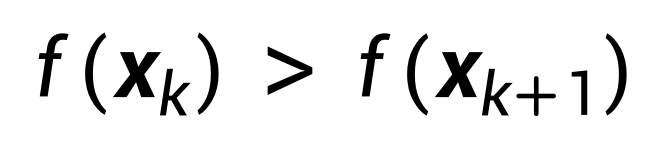
回到前面抛物线的目标函数,这时自变量x退化到一维(标量)。假设根据迭代算法我们当前走到了第k步,如下图:
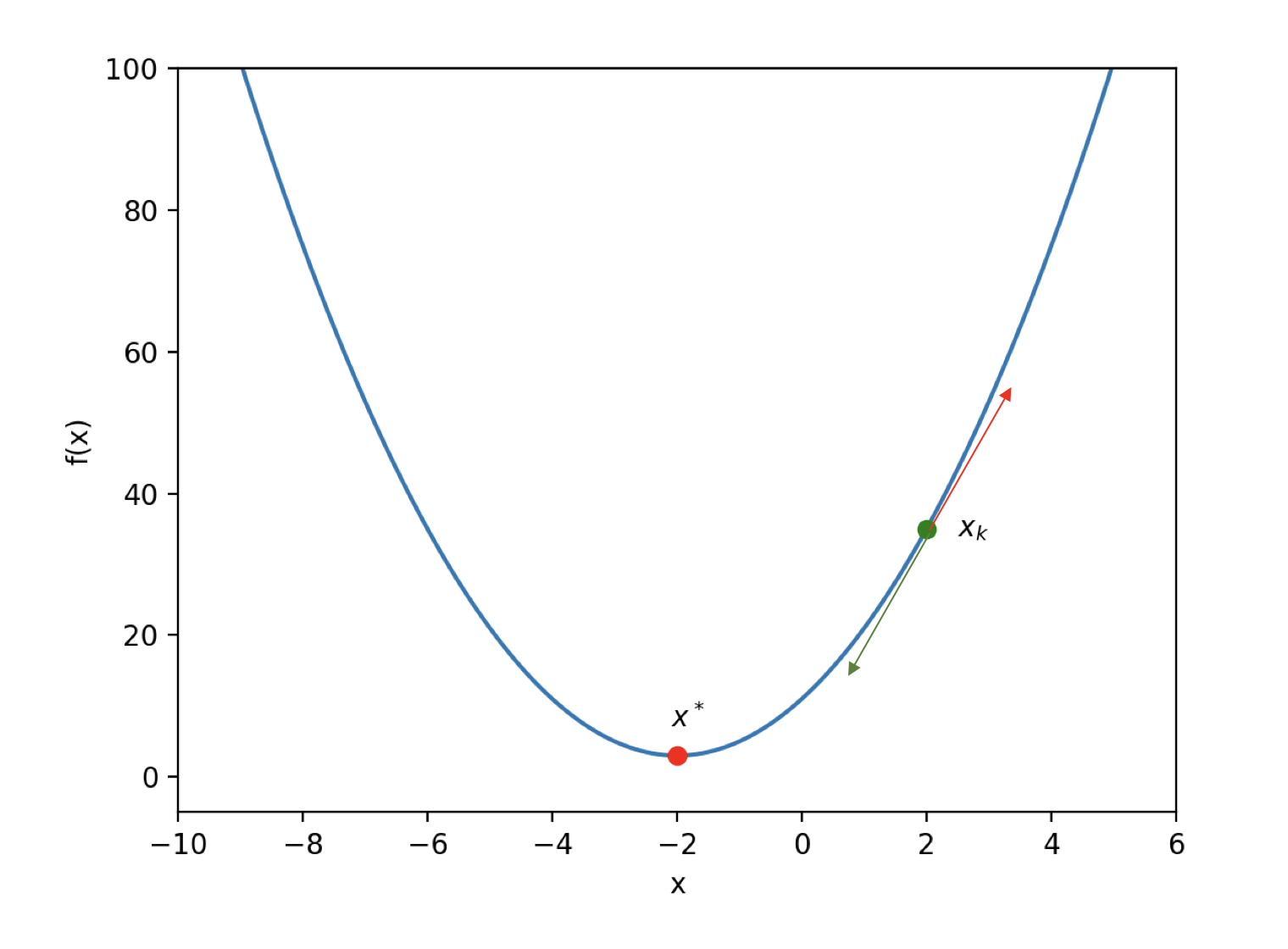
图中红色箭头是xk点的切线方向,绿色箭头则是切线的相反方向。显然,下一步(第k+1步)应该沿着切线的相反方向迭代,去寻找xk+1的位置。这样,就能让目标函数f(x)的值越来越小,最终抵达最优解x*。
而对于一般的目标函数,自变量x是一个n维向量,对应一个n维空间。由于在多维空间中函数的图像是无法在视觉上体现的,所以我们先考虑x是二维向量的情况(也就有两个自变量),这时函数的图像是三维空间中的一个曲面。如下图:
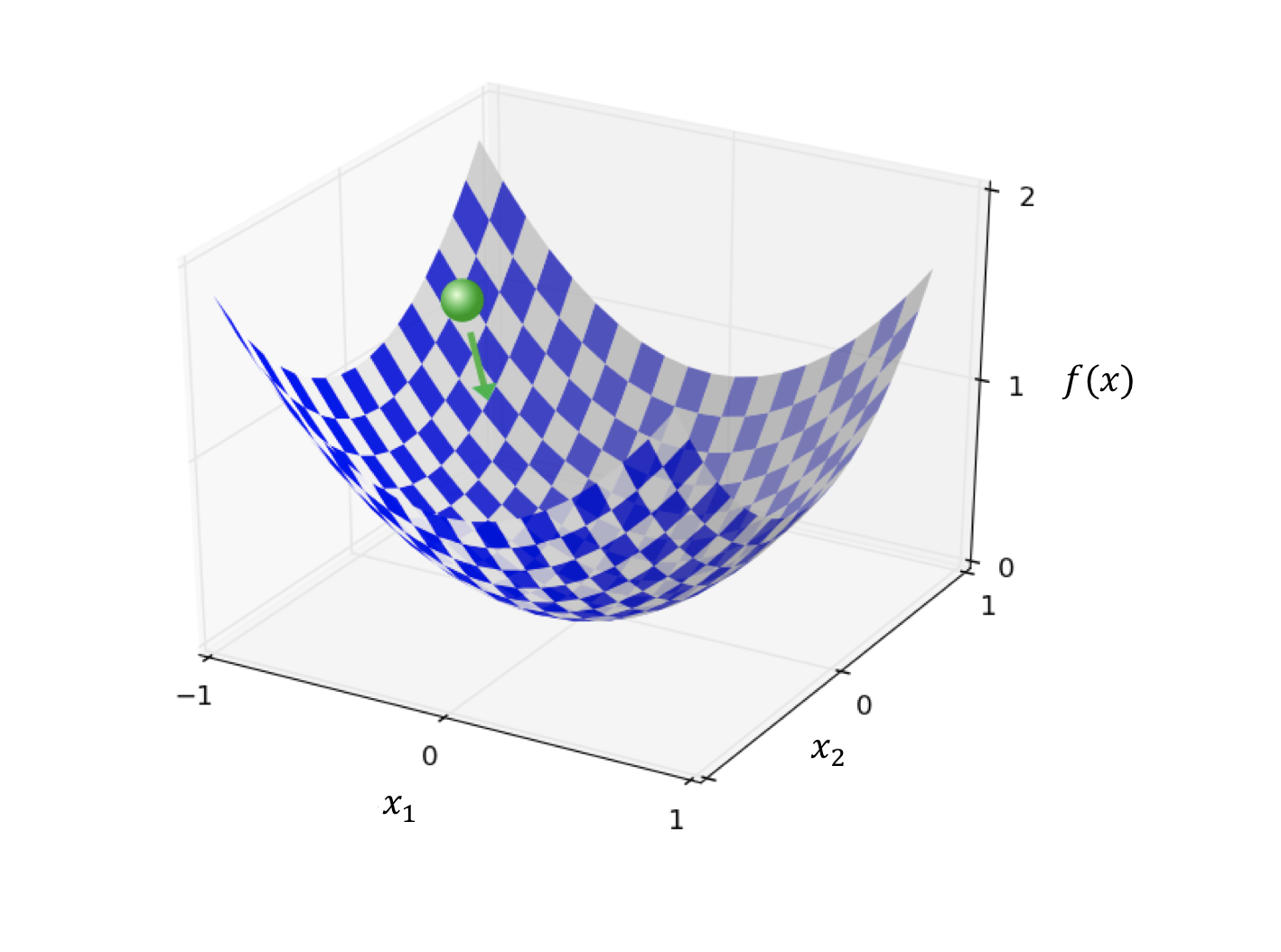
与前面抛物线图像的情况类似,一次迭代沿着图中绿色箭头的方向进行,就像一个小球在山谷的斜坡上向下滚动,最终到达谷底(最优解)。
前面的两个例子比较形象地展示了迭代的方向。可以看出,迭代应该是向着与最优解不断接近的方向进行。但这个方向的选择在复杂的多维空间中并不容易。比如,在下图的函数图像中,曲面的「地形」比较复杂,每次的迭代方向就不是那么容易选择的了。
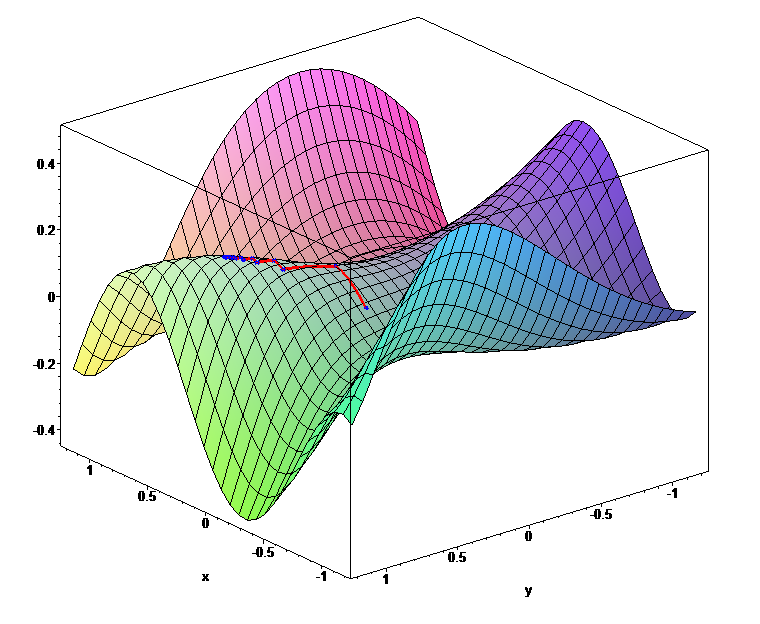
两种迭代策略
每一步迭代,都需要决定两个因素:
- 迭代方向:往哪个方向走。
- 迭代步长:这一步走多远。
在优化理论中,选择迭代方向和步长的策略有两大类:
- line search (线搜索);
- trust region (信赖域)。
Line search的策略是每一步迭代都选择一个固定的方向(通过近似计算使得目标函数变小的方向),然后沿着这个方向前进一个合适的步长。而对于前进方向的选择上,又可以细分成不同的方法,下面简要介绍一下:
- 梯度下降法 (Gradient Descent)。这个是在机器学习中经常用到的优化方法。这种方法会选择沿梯度(一阶导数)相反的方向作为下一步迭代的方向,然后沿着这个方向走尽量远的距离,直到目标函数的值不再下降为止。因此,这种方法也可以称为最速下降法 (Steepest Descent)。
- 牛顿法 (Newton method)。在选择迭代方向的时候考虑二阶导数的信息(计算过程依赖Hessian矩阵)。
- 拟牛顿法 (Quasi-Newton method)。在选择迭代方向的时候通过近似计算避免了直接计算Hessian矩阵。
而trust region这种策略与line search不同,它在每一步迭代时并不会选择固定的前进方向,而是根据当前迭代位置选择一个近似区域。这个近似区域就被称为信赖区域 (trust region),因为在这个区域内可以做一些与目标函数近似的计算,如果区域太大这种近似就不成立了。trust region这种策略会先固定住信赖区域的大小,然后在这个区域内选择一个使目标函数变小的前进方向和步长(基于近似计算);如果发现计算中使用的近似计算与目标函数差距太大了,就减小信赖区域的大小,重新进行计算。
总体来讲,由于实际中目标函数都比较复杂,对应多维空间中曲面的「地形」也非常复杂,我们没法直接利用目标函数的全局信息来找到最优解。因此,迭代的时候,我们只能根据当前迭代位置附近的局部信息来做近似计算。这些局部信息可能来自于一阶导数(梯度)或二阶导数(Hessian矩阵),而近似计算则是基于泰勒公式 (Taylor formula)。不管是line search还是trust region,它们都可能使用同样的这些局部信息和近似计算方法。不过在基于近似计算的结果选择迭代方向和步长的时候,line search和trust region采取了两种不同的策略:line search在每一步迭代中固定住前进方向,然后试探合适的步长;而trust region则在每一步迭代中尝试同时选择前进方向和步长大小,而一旦信赖区域大小发生变化,前进方向和步长也都发生变化。
我们用下面的概念图来做一个总结(本文贡献的最有价值的一张图,点击看大图):
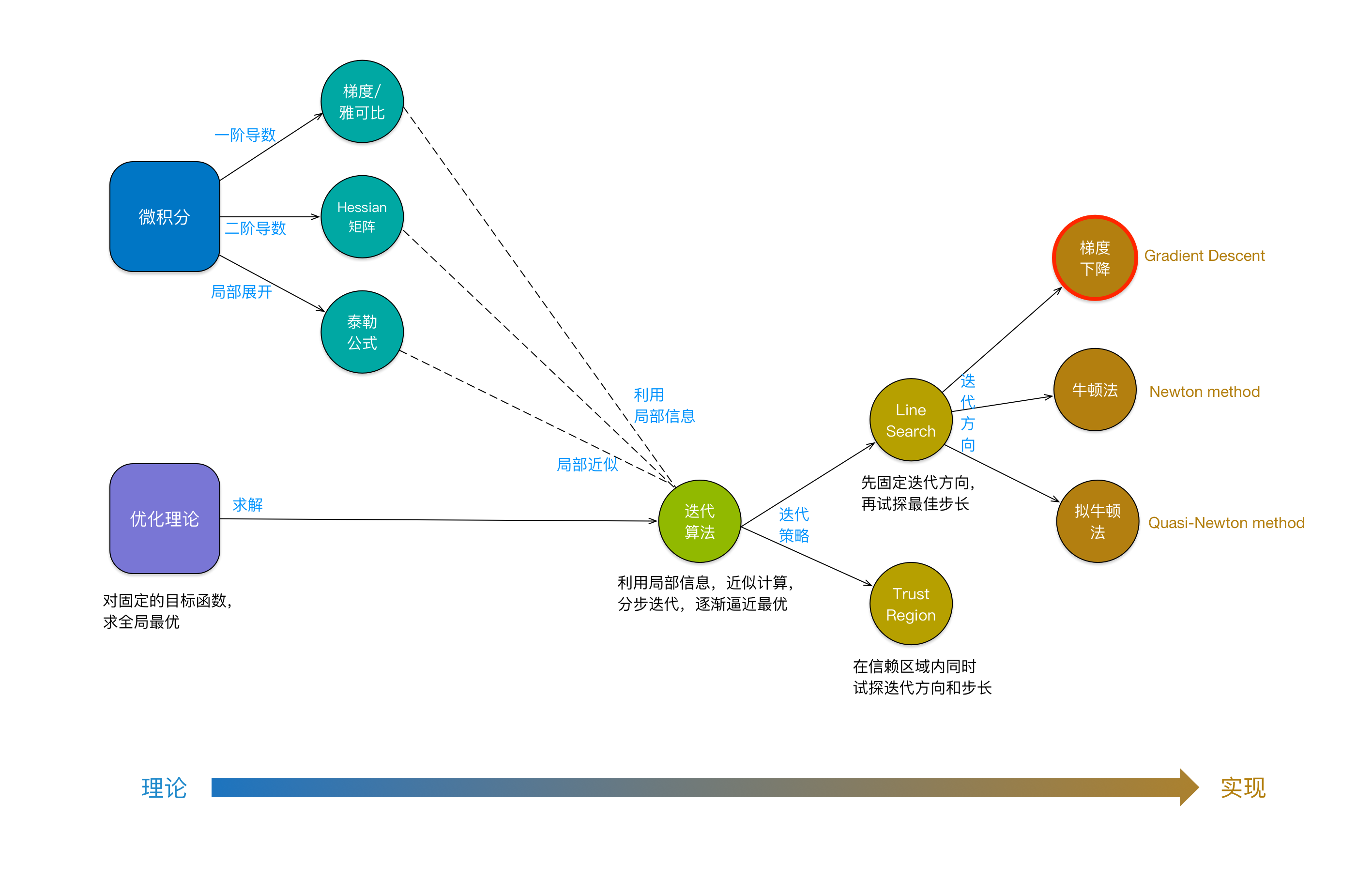
上图有一个有趣的现象值得注意:越是向左,越是偏理论;越是向右,越是偏实现。左边是数学理论,而右边则是可以在计算机上实现的算法。
总结
严格来说,优化并不属于机器学习的范畴。它们之间的关联在于:机器学习的模型训练(即模型的求解)会用到优化理论。所以,这里留给我们的一个课题,就是讨论清楚这个关联是怎么来的(也就是本文开头的步骤1,如何把一个机器学习问题转化成一个优化问题)。
把机器学习问题转化成一个优化问题的关键在于,优化的目标怎么表达。由于机器学习的整套理论是基于概率的,因此,机器学习模型求解的优化目标,也是基于概率来表达的。我们下次再讨论机器学习的概率表达问题。
(正文完)
参考文献:
- [1] Jorge Nocedal, Stephen J. Wright, “Numerical Optimization”, Second Edition.
- [2] https://en.wikipedia.org/wiki/Mathematical_optimization
后记:在公众号上写文章,有一个好处:可以比较完善、系统地表达一个观点。但是,写一篇文章是耗时费力的,特别是对于技术性的文章。要保证质量,就很难保证频率。因此,最近开始重新玩微博,可以把平常的想法随时分享出来,也可以以更快地频率与别人互动。欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。
其它精选文章:
- 卓越的人和普通的人到底区别在哪?
- 用统计学的观点看世界:从找不到东西说起
- 漫谈业务与平台
- 漫谈分布式系统、拜占庭将军问题与区块链
- 技术的正宗与野路子
- 三个字节的历险
- 做技术的五比一原则
- 知识的三个层次
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-ml-optimization.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。

最新文章
- 为什么agent和workflow可以融合在同一个架构里?
- 万字长文!两栖模式构建Agent,与OpenClaw/Hermes不一样的解法——开源AmphiLoop
- Claude Managed Agents意味着什么?
- 【开源】专为「探路+编码」范式设计的全新浏览器工具集+Skills
- 不用手写一行代码,10分钟立等可取,爬取twitter和github动态
- 使用OpenClaw时如何降低token消耗?分享一个浏览器自动化的skill
- 过年了,聊聊AI和人文
- 使用Bridgic长程自主模块+MCP,控制你的浏览器
- AI智能体纪元或将从2026开始归零
- 从Python异步编程的剖析中体会智能体并发编程模式