科学精神与互联网A/B实验
2019-08-18
我们先讲两个历史上真实发生过的小故事。
第一个故事是关于黄热病。
黄热病是一种严重的传染病,曾在1793年袭击美国费城。当时,费城有一位著名的人物,他叫本杰明·拉什[1]。拉什曾经签署过《独立宣言》,是美国的开国元勋之一。同时,他还是著名的教育家和出色的外科医生。在费城的黄热病爆发的时候,他坚信放血疗法可以治疗这种疾病。于是,他用手术刀或水蛭吸血的办法给病人放血。当拉什自己染上这种疾病的时候,他也采用同样的方法给自己治疗。
第二个故事是关于坏血病。
坏血病在历史上曾是严重威胁人类健康的一种疾病,尤其在远洋航行的水手中尤为严重。在18世纪,一位英国船长发现,在一些地中海国家的海军舰艇上服役的船员没有坏血病。他注意到,这些船员的食物配给中含有柑橘类(citrus)水果。于是,为了弄清真正的原因,这位船长将他的船员们随机分为两组:其中一组在日常饮食中加入酸橙(limes),而另外一组维持原来的食谱不变。结果通过对比发现,定期食用酸橙的一组船员,真的防止了坏血病的发生。后来,定期食用柑橘类水果就变成了英国水手必须遵循的一种规定。这种做法越来越普遍,以至于在后来的美国英语中产生了一个新的词汇——limeys[2],用来代指任何一个英国人。这个词翻译成中文称为「英国佬」。
现在让我们来比较一下这两个故事有什么不同。
在第一个故事中,本杰明·拉什坚信他的放血疗法可以治疗黄热病。实际上,他确实「治」好了一些病人。当然,也有一些病人死掉了。事情的解释就演变成这样:如果病人情况好转,那么就被作为放血疗法有效的证据;反之,如果病人死掉了,拉什就解释说是病情太严重,已经无药可救了。后来,有评论家指出,他的疗法甚至比疾病本身更加危险。
而在第二个故事中,船长将船员分成了两组,进行了对照实验 (controlled experiment)。现代医学已经证实,这位船长通过对照实验得到的结论确实是有效的。坏血病的致病原因是由于缺乏维生素C,而柑橘类水果中含有大量的维生素C。
在这两个故事中,当事人都试图在寻找事物之间的一种因果关系 (causal relationship)。本杰明·拉什相信放血疗法和治愈黄热病之间存在因果关系;而第二个故事中的船长则发现了食用酸橙和防止坏血病之间的因果关系。那为什么拉什没有找到真正的因果关系,而那位英国船长找到了?关键就在于对照实验。
进一步追问,为什么使用对照实验就能得到真正的因果关系?这本质上是一个哲学问题,涉及到「科学」之所以成为科学的本质原因。接下来,我们就先展开来聊一聊,什么是真正的因果关系以及这个问题所涉及到的科学本质;然后再回到现实,跟大家讨论一下在互联网的业务中关于如何进行对照实验的各种技术。
因果律的陷阱
每当我们得出一个因果性结论的时候,都应该倍加小心。比如,看到苹果落地,怎么就能得出万有引力是导致苹果落地的原因的?为什么不是其它原因导致的?想一想我们可以考虑的别的因素还有很多啊,比如天气啊,地理位置啊,苹果的品种啊,等等,它们为什么就不能是苹果落地的「原因」呢?为什么我们不能得出结论说:因为今天天气晴朗,所以苹果就落到地上了,而明天可能一下雨,苹果就自己飞到天上去了?为什么我们不能得出结论说:我们看到的这个苹果因为它生长在河北省,所以就落到地上了,而对于生长在湖南省的苹果,也许就未必了?
你肯定会说,这样想问题太荒谬了。没错,是很荒谬。但那是因为现在我们已经很清楚苹果落地的原因了,我们对科学给出的「万有引力」这个解释已经深信不疑了,所以才会认为这些想法很荒谬。试想一下,在人们发现「万有引力」之前,是不是考虑「天气」、「地理位置」这些现有的因素也许是更自然的想法呢?
上面苹果落地的例子表明,找到真正的因果关系,并不容易。在牛顿时代之前,人们对于苹果落地这一司空见惯的现象已经观察了成百上千年,也没能得出现象背后的真正原因到底是什么。而弄错了因果关系,就会得到很荒谬的结论。
实际上,这还不是最糟的。当我们在讨论苹果落地的「原因是什么」的时候,已经首先假定了苹果落地是「存在一个因」的。而在科学和哲学的发展史上,因果关系本身存在的合理性甚至都被怀疑过。苏格兰历史上有一位怀疑一切的哲学家,名叫休谟。他比较极端,认为世界上根本不存在因果律这种东西。还是以苹果落地为例,按照休谟的观点,就算你观察到苹果离开树枝后落到地上的这一事实发生了一万次,也不能说明第一万零一次苹果离开树枝就一定会落到地上。换句话说,他根本不相信苹果落到地上是存在某种「必然」的原因的,而只能看成是偶然事件,哪怕它发生了再多次也是一样。结论听起来仍然很荒谬。但哲学家都是聪明人,绝不是头脑混乱才胡言乱语(实际上休谟是个天才,人家12岁就上大学了)。休谟是沿着怀疑主义前后一贯的逻辑进行推论的。罗素就曾经评论说:“他把洛克和贝克莱的经验主义哲学发展到了它的逻辑终局,由于把这种哲学作得自相一致,使它成了难以相信的东西。”
《三体》小说中提到过一个「农场主假说」,跟休谟的这种观点类似。这个假说是这样描述的:
一个农场里有一群火鸡,农场主每天中午十一点来给它们喂食。火鸡中的一名科学家观察这个现象,一直观察了近一年都没有例外,于是它发现了自己宇宙中的伟大定律:“每天上午十一点,就有食物降临。”它在感恩节早晨向火鸡们公布了这个定律,但这天上午十一点食物没有降临,农场主进来把它们都捉去杀了。
这只可怜的火鸡认为自己发现了一个「因果律」:每天上午十一点(这是因),就有食物降临(这是果)。但最后事实证明,「上午十一点」和「食物降临」这两个事件之间并没有必然的因果关系,它们只是在过去一年内恰好同时发生(最后在感恩节这天发生了变化)。这个故事含有一丝神秘的意味,它暗示了,我们人类发现的一些「因果规律」,也许是某个更高等级的文明或者某个神秘力量随意设置的。
我们很快就发现了,按照这样的方式思考问题,完全不承认这个世界上有因果律存在,那么科学就没法玩了。科学研究要进行下去,就必须承认因果律是普遍存在的,因为科学定律基本都是对因果规律的总结。我们之所以应该承认和尊重科学,是因为科学「有用」,它在过去几个世纪内深入地影响了人类的生活。我们必须转向实用主义的观点,否则就会陷入虚无的诡辩。总而言之,我们应当及时放弃休谟的极端观点,回过头来相信因果规律的存在。
关键的一点是,科学必须有一套行之有效的方法和标准,来验证科学定律的正确性,来检验它是否真正反映了事物的因果关系。实际上,科学定律都不是「空中楼阁」,都是被实践验证过的理论。牛顿的三大定律,被无数的实验和观察验证过;爱因斯坦的相对论,也被很多天文观测所验证。这种「科学的」验证方法就是前面提过的「对照实验」。
什么是对照实验呢?通俗来说,对照实验就是将实验的物体或人群随机分成两个组,一个实验组 (treatment group),一个对照组 (control group)。对实验组人为地修改某个控制变量(也就是实施实验),而对照组只是用来做对比(维持它原来的状态)。以文章开头提到的坏血病故事为例,英国船长就是实施了一组对照实验。他将船员们随机分为两组:在日常饮食中加入酸橙的一组是实验组,食谱维持不变的一组是对照组。最终实验结果是:实验组的船员发生坏血病的比率减少了。这个结果的「因」,也就是在实验组和对照组之间有差异的那个因素——酸橙。至此,船长得到了结论:酸橙可防止坏血病。
我们再来看一个对照实验的例子。
《哲学家们都干了些什么》这本书中描写了一个案例。有人调查了大学生的体重和交友数据之后发现,越是胖的人,身边的朋友就越多。然后就得出了一个结论:身体胖是朋友多的原因,也就是说,身体越胖,越有魅力。这个调查其实也可以设想成一组对照实验:我们找两组大学生,一组体重超标(实验组),一组体重正常(对照组)。然后我们对比两个组的交友数据,发现实验组的学生朋友比较多。于是,我们这样分析,「朋友多」是一个结果,它的「因」就是在实验组和对照组之间有差异的那个因素——身体胖。
仔细的读者一定已经发现了这里的一个陷阱。在做对照实验的时候,一定要保证实验组和对照组除了实施实验所必需的那个控制变量之外,其它所有特征均相同。刚才这个案例的陷阱就在于,实验组和对照组的选择是有问题的,两个组除了体重不同之外,还可能有很多其它不同的特征。这些其它的不同特征,也都有可能是造成两组朋友多寡的原因。这个案例的真正答案可能是这样的,身体胖的人喜欢参加饭局,而喜欢参加饭局是因为他们社交范围比较广,社交范围比较广的表现就是朋友比较多。这是一个典型的「第三变量」问题。「身体胖」和「朋友多」都和第三变量「喜欢参加饭局」有关,所以「身体胖」和「朋友多」之间并不存在直接的因果关系,它们之间只是具有「相关性」。
统计学上有一个经典的结论:相关性不代表因果性。我们在做数据分析时,很容易发现两个变量之间的相关性,比如一个变量随着另一个变量的增大而增大,或者一个变量随着另一个变量的增大而减小,但具有相关性的两个变量之间是否具有因果关系,决不能草率地下结论。
我们再分析一下为什么会陷入把相关性当成因果性的陷阱。刚才提到,在分析大学生体重和交友数据的例子中,实验组和对照组的选择是有问题的,我们把这个问题称为「选择性偏差」。我们对于实验组(也就是胖子组)的选择,掺杂了太多人为的因素,导致实验组和对照组之间差异巨大,根本不存在可比性。也许,胖子组里面有钱的学生更多,或者胖子组里面女生比男生更多(或者反过来),照这样分析,我们也许会认为「有钱金多」或「性别」都是「朋友多」的原因呢。那为什么文章开头坏血病的对照实验是成功的呢?那是因为船长对于船员进行分组时有一个很关键的细节:是「随机」分组的。首先,两个组的船员都来自同一艘船,他们平常的生活条件大体相同。如果不是来自同一艘船,就会引入额外的干扰因素,比如船员的航线不同,出身不同,整体健康状况可能也不同,最终导致实验失败。其次,两个组是随机分派的,这样就避免了「选择性偏差」。
说了这么多,无非就是为了告诫我们自己,当我们设计实验来探索或验证因果律的时候,需要加倍小心。不管是科学实验本身就经常遭遇的相关性陷阱和选择性偏差,还是来自哲学意义上的对于因果律根本性的挑战,都说明对于事物之间因果关系的分析是一个非常棘手的课题。而科学正是由于它的这种「谨慎」,才让它在近现代历史的发展中大放异彩。
互联网业务中的A/B实验
互联网产品通常是逐渐迭代、慢慢进化的,而通常情况下选择都是比较多的。那么自然就产生了一个问题,产品在每一步到底应该选择向着什么方向迭代,才是最有利于业务发展的?在互联网业务的开发和运营当中,我们经常需要面对这样的问题进行决策。比如,对产品首页进行改版,可能有不同的方案,那么到底应该选择哪个方案?再比如,对推荐算法进行新版本升级,能不能保证提高数据指标?又比如,在商业化的过程中,想在产品中投放广告,怎样做能够收益最大而对用户体验的影响最小?
这些事情本质上也是在寻找事物之间的因果关系。我们发布了某个新的产品feature,或者对产品进行了优化,这是「因」;然后我们观察到了数据指标的变化,比如用户留存率或活跃度变高了,这是「果」。根据上一节的讨论,我们已经知道了,分析因果关系需要加倍小心,否则很容易陷入思维的陷阱。通常产品持续在迭代,当我们对产品进行某个更改之后,其它的变化也在发生(比如另一个团队也对产品进行了修改),周围的环境也在发生变化(比如节假日和社会热点事件的影响),我们就很难分析出最后数据指标变化的原因到底是来源于哪些变化因素。
在一个缺乏完善的对照实验机制的环境中,人们通常会对照不同的时间段进行数据分析。人们经常会这样宣称,你看,之前的某段时间内,用户留存率是这样的,但从某天开始,我们做了一个实验(发布了一个产品改动,或者改变了某个运营策略),结果留存率提升了1个百分点。这样的分析在很多情况下都是比较危险的。这相当于在时间维度上先后选取了「对照组」和「实验组」,它们未必就有可比性。首先,当产品每天都在迭代更新,甚至多个改动同时并存的时候,你很难将留存率的提升归因于某个具体的产品改变。其次,就算你在做实验的时候确定没有别的干扰因素了,但某些隐藏的因素的变化,你根本没办法识别出来,比如群体的统计特征也很可能在随着时间变化。这样得到的结论,未必反映了真实的因果关系,也许换一个时间、换一个环境就不适用了。这时候我们能做的,也只有对数据进行各种各样的解释,如果解释不通,就叠加更多的补充因素和假定条件来解释。
与科学实验类似,其实我们在互联网业务中也可以采取严格的对照实验。在程序开发的领域,我们一般称之为A/B实验。实际上,在不同的场合,它至少有半打以上不同的名字。下面的列表列出了这些名字:
- Controlled experiments (对照实验)
- Randomized experiments (随机实验)
- A/B tests (A/B测试,A/B实验)
- Split tests
- Control/Treatment tests
- MultiVariable Tests (MVT)
- Parallel flights
关于互联网业务中的A/B实验,有两篇论文做过详尽的论述:
- 《Overlapping Experiment Infrastructure: More, Better, Faster Experimentation》,作者是谷歌的Diane Tang, Ashish Agarwal, Deirdre O’Brien, Mike Meyer。
- 《Controlled experiments on the web: survey and practical guide》,作者是微软的Ron Kohavi, Roger Longbotham, Dan Sommerfield, Randal M. Henne。
现在我们就逐步展开来看看这两篇论文给出的A/B实验方案是怎样的。
假设,最开始整个系统里就只有两个实验(1个实验组和1个对照组)。注意,我们统一下词汇,不管是实验组还是对照组,我们都称为1个实验。虽然对照组只是用来做对比,分配到对照组的用户看不到任何产品或运营策略改动,但我们也把它称为1个「实验」。
我们随机分出了10%的流量作为对照组,又随机分出了10%的流量作为实验组。这时剩下了80%的流量是空闲的,没有进行任何实验。从用户的角度来看,在实验组内的这10%的用户,能够看到正在进行的实验(产品或运营策略改动),而在对照组和剩下的空闲流量中的用户(总共90%),是看不到产品或运营策略改动的。如下图:

一般情况下,我们需要保持用户体验的前后一致。也就是说,一旦一个用户被分到了实验组,那么他发起的后续请求应该都落到实验组的流量里面。我们需要一种会话保持(session sticky)的机制,而这有很多种可能不同的方案。如果用户是有登录状态的,我们可以拿用户ID来取模,如下:
mod = 用户ID % 1000
而如果用户是没有登录态的,就像谷歌的搜索服务一样,那么可以拿cookie变换成一个数值再取模,如下:
mod = f(cookie) % 1000
当然还有很多计算mod的方案(关键是达到随机的效果)。但不管是上面哪一种取模的方式,我们只需要将mod在[0, 99]之间的请求分配到实验组,将mod在[100, 199]之间的请求分配到对照组,就分别获得了10%的随机流量。
假设现在人们尝到了A/B实验的甜头,这种机制在公司内推广开来了,越来越多的项目开始进行A/B实验。于是我们将空闲的那80%流量也安排了实验。下图展示了10个实验(9个实验组和1个对照组)同时进行的情形:

这时,我们看到,所有的流量都被用光了。任何一个请求,都被分配到了某一个实验当中。假设我们现在要加入第11个实验,发现没有流量可用了。
当我们建立起这样一套A/B实验系统之后,当然希望尽可能多的产品迭代都先经过A/B实验验证过数据效果之后,再推广给全量用户使用。于是,这个系统能同时容纳的实验个数,就决定了产品迭代和创新的速度。而流量是宝贵的,一部分实验把流量全部占用之后,其它实验就没法同时进行了(这个现象叫starvation)。容易想到的一个方法是,我们减少每个实验的流量占比是不是就行了。比如前面10个实验,每个组改为占用5%的流量,就能够总共容纳20个实验同时进行了。但是,每组的流量不能太少,否则就可能失去统计特性,得不到有效的数据结果了。每家公司的产品,它们各自的用户数也不尽相同,用户多的产品也许可以分的组多一点,用户少的产品,能够分的组就少一点。这显然不是我们想要的结果。
仔细分析上面的情况,造成「流量不够用」这个问题的核心原因在于,每一个请求都最多只能被分配到一个实验当中。如果我们允许一个请求被同时分配到多个实验当中,也就能复用流量了,于是我们的系统能够同时容纳的实验数量也就没有上限了。
为了做到流量复用,我们将实验进行分层(layer),如下图所示,展示了14个实验(12个实验组和2个对照组)同时进行的情况(分布在两层):
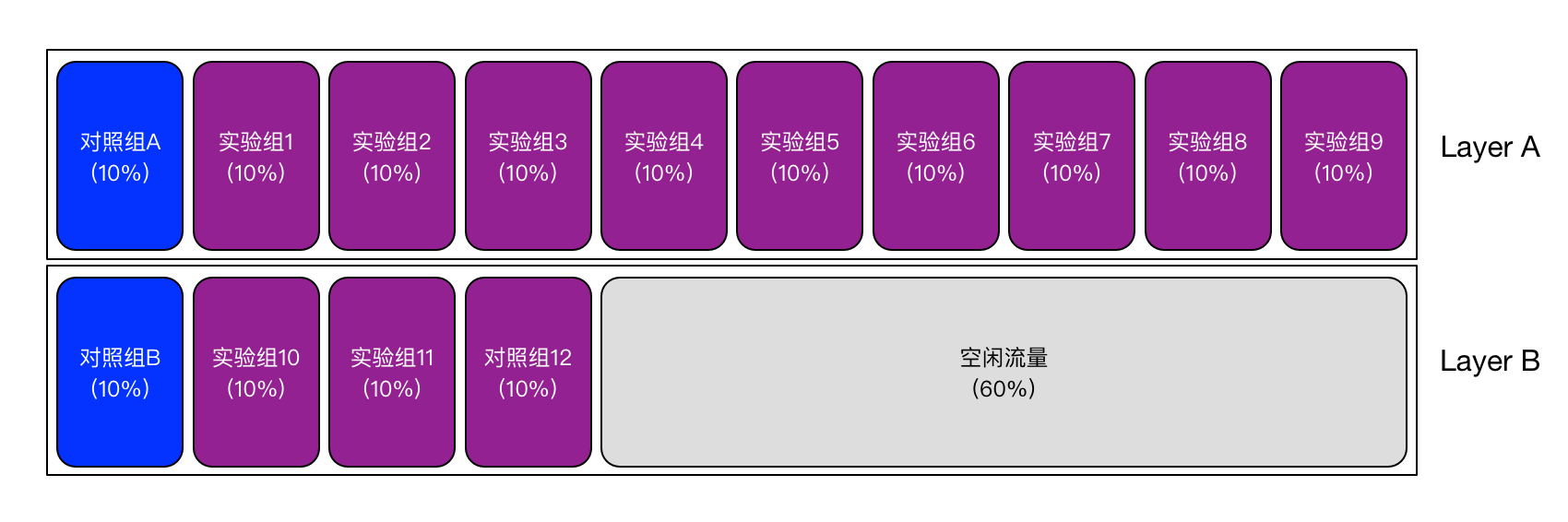
在上图的实验配置中,我们将14个实验分布在了两层之中(Layer A和Layer B)。这意味着,同一个请求,可能同时被分配到Layer A中的某个实验,同时又被分配到Layer B中的某个实验。显然,实验在两个层之间的分布是不能随意放置的,有依赖关系的两个实验就不能分布到两个不同的层中。
对于完全独立的两个实验,比如对两个完全无关联的产品模块的改动,我们就可以把它们放到不同的层。这时候,来自不同层的两个实验是完全正交的。「正交」是什么意思呢?这个词本身来源于数学,表示两个向量互相垂直,或者说它们各自向对方的投影为零,这里引申过来可以理解为,两个实验互相没有影响。到底是怎么做到没有影响的呢?实际是从宏观统计上来看的。还是以上图为例,通过Layer A中某个实验的流量,会重新打散,随机地分配到Layer B的每个实验中。比如对于Layer B中的实验组10中的某个用户来说,他看到Layer A中每个实验的概率都是10%。换句话说,Layer A中的实验对于Layer B中的实验,不是说真的没有影响,而是在统计上来说,Layer A中的某个实验对于Layer B中的每个实验的影响都是均等的,所以相当于没有影响。结果就是,Layer B中的每个实验在统计特征上仍然是具有可比性的。
那加入层的概念之后应该怎样分配流量,既能做到会话保持,又能做到层与层之间的影响正交呢?方法仍然不是唯一的,谷歌的论文中是这样计算mod的:
mod = f(cookie, layer) % 1000
将层的编号放入计算当中,容易看出,这样可以保证在同一层内,会话是可以保持的,也就是说cookie值相同的不同请求会落到同一个实验组或对照组中;而不同层之间的流量又是随机打散的。
我们前面说,只有相互没有依赖关系的两个实验,才能放到不同的层中。但在实际中,有时候实验之间是有依赖关系的。比如一个实验修改了页面背景颜色,而另一个实验修改了字体颜色,至少它们各自的颜色设置不能太接近,否则整个页面显示上就有问题了。再比如,一个实验给App的第一级页面增加了一个Tab,而第二个实验修改了某个二级页面,并且这个二级页面的入口是在第一个实验增加的那个Tab里面。这样第二个实验就依赖第一个实验。
这时候我们应该怎么做呢?应该把有依赖关系的实验放到同一层当中,这样它们会被分配不同的流量(即流量没有交集),从而消除互相的影响。如果有必要的话,也可能需要对实验重新进行设计。
在谷歌的论文中,一个实验被看成是对于系统参数(parameter)的修改,比如字体颜色是一个参数,再比如某个新feature的开关也是一个参数。按照这样来抽象概念的话,整个系统相当于有一个可修改(或者说可配置)的参数集合,而一个实验相当于在一部分流量上对于一个参数子集进行修改。每个层则相当于把整个的参数集合分成了若干个互不相交的子集,每个子集与一个层对应,而处于这个层中的所有实验都只能修改跟这个层对应的那个参数子集。
有些读者应该已经在上面的图中注意到一个细节了:对照组和对应的实验组都在同一层。实际上这个要求是必须的,「对照组A」只能和Layer A中的各个实验组进行对比,「对照组B」只能和Layer B中的各个实验组进行对比。而且,实验组和相应的对照组的流量占比也应该相同。
分层嵌套
这个分层实验模型还可以更加灵活,支持互相嵌套。比如系统中处于上下游的不同子系统,它们平常都是在不同层中进行各自的实验的(互相没有依赖)。但有一天,我们想做一个比较大的实验,需要同时修改来自多个子系统的参数。这就产生矛盾了,因为各个子系统的可修改参数集合在不同的层中,我们这个实验放在哪个层都不合适。
这时候怎么办呢?谷歌的论文中提出了Domain的概念。下图是一个例子:
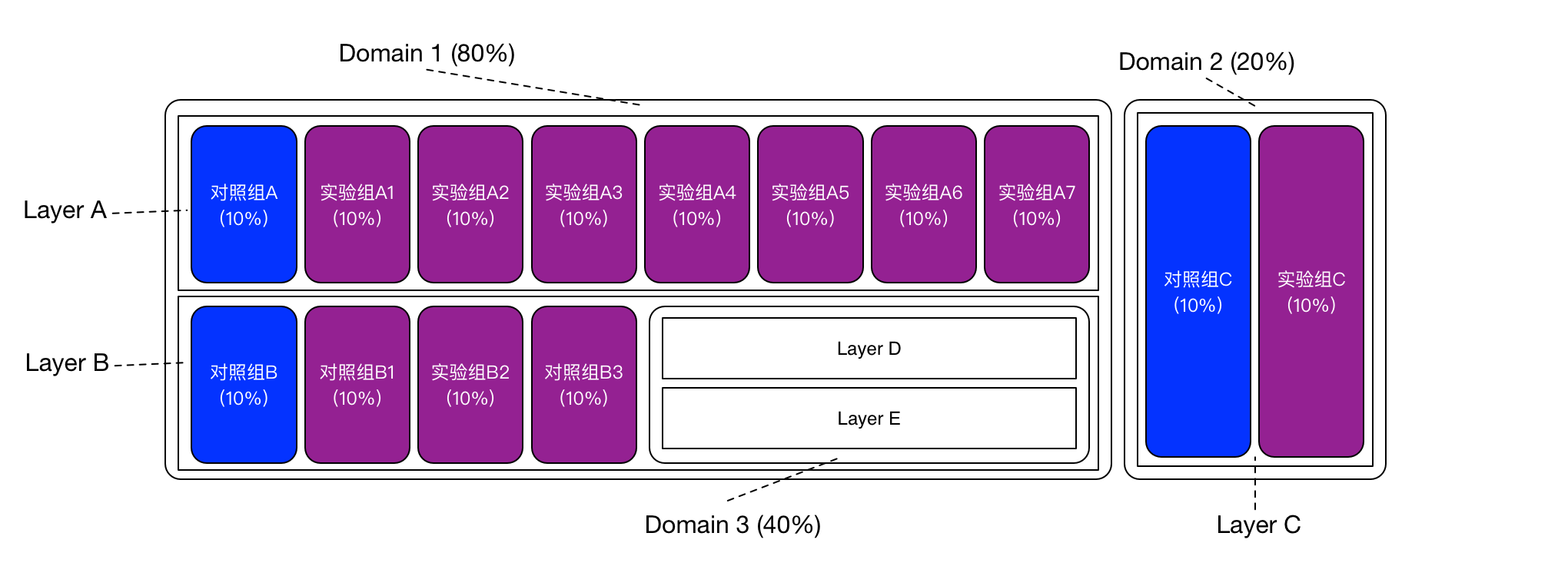
Domain代表了一部分切分好的流量,里面可以针对这部分流量再进行分层。Domain、Layer(层)和实验(experiment)这三个概念的关系就演变成:Domain可以包含若干Layer,一个Layer可以包含若干个实验,一个Layer也可以包含Domain。于是,Domain和Layer就可以层层嵌套下去。
总之,Domain和实验,与流量分配有关;Layer,与系统参数划分子集有关。
以上图为例,整个100%的流量先分成了Domain 1和Domain 2,它们各占80%和20%的流量。Domain 1内部包含了两个层:Layer A和Layer B;Domain 2只包含了一个Layer C。我们前面提到的「比较大的实验」,就可以在Layer C中进行,它可以修改所有的系统参数。
上图还有一个值得注意的点:Layer B中又嵌套了一个流量占比40%的Domain 3,Domain 3中可以继续分层,相当于把Layer B对应的参数子集再进一步划分子集。
condition和trigger
有些特殊的实验,根据业务本身的要求,是不能曝光给所有用户的。比如,一个多语种的国际化互联网服务,根据用户语言设置的不同,给用户展示的页面内容也会不同。如果一个实验是只针对日语用户的,那么随机切分的一份流量就不能全部用于这个实验,因为随机切分的流量里面也包含了非日语用户的请求。这时候就需要一个条件,称为condition,用来在随机切分的这部分流量中把日语用户的流量过滤出来。下图展示了一个例子:
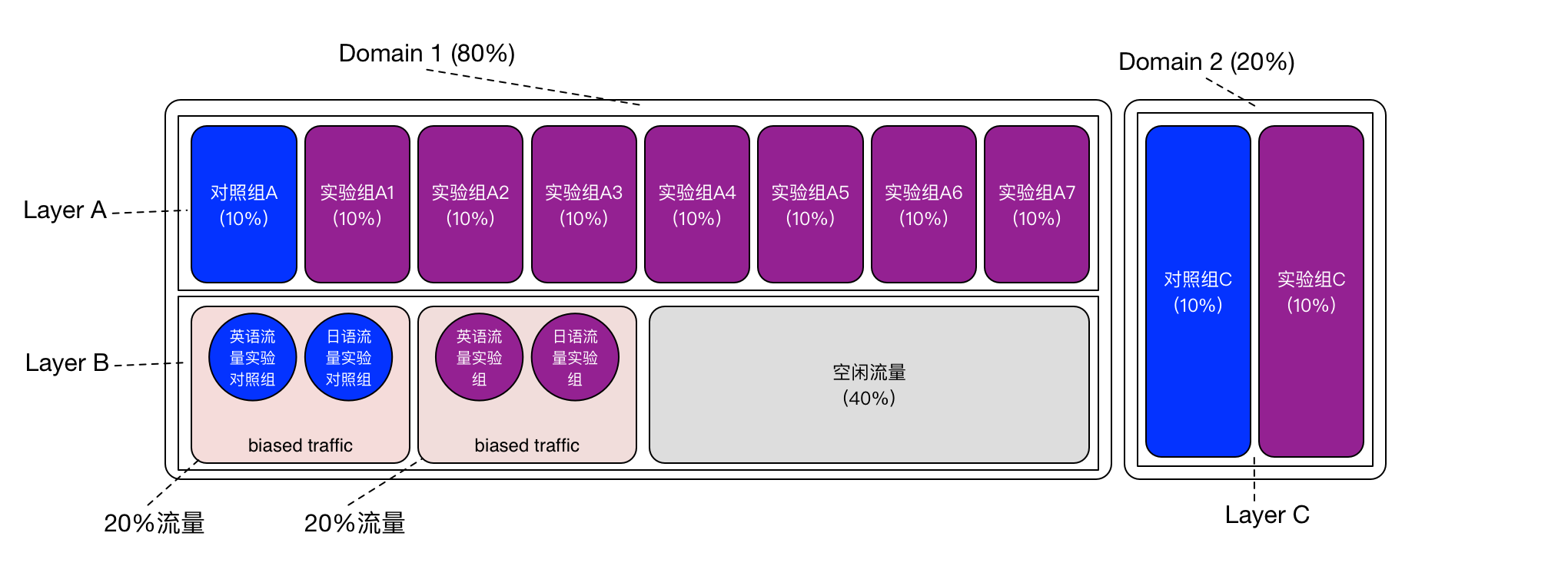
在上图的实验配置中,注意一下Layer B中随机切分了两部分流量,各有20%,分别用于对照组和实验组。但这各自20%的随机流量里面,使用两个不同的condition分别过滤出来了英语流量和日语流量,并分别运行了针对英语用户和日语用户的两个实验(还有两个对应的对照组实验)。
由于这一类实验对流量有特殊的要求,所以使用了condition在随机切分的流量中进一步切分流量。这种方式带来了一个好处,不同的若干个condition,只要它们的过滤条件互不相交,就可以共用同一份随机流量,从而提高了流量利用率。就像上图中的「英语流量实验组」和「日语流量实验组」一样,是分别使用「英语」和「日语」两个condition,在同一份20%的随机流量中进一步切分出了各自需要的流量。
一般来说,针对部分用户进行的定向实验,都可以认为是根据一个condition来切分流量。常见的condition包括:地域、人群、浏览器类型、客户端版本等等,只要经过合理的抽象,它们都可以在一个A/B实验系统中统一支持。
使用condition会对流量分配带来一个重要的影响:一份随机流量被condition切分出去一部分流量后剩余的流量,不能再分配给别的实验了。以上图为例,起初切分出来的20%的随机流量,除去「英语流量实验组」和「日语流量实验组」用掉的流量之外,剩余的空闲流量(即上图中浅粉色的部分)不能再分配给别的实验组了,因为这部分流量已经失去了随机特性了(缺少了英语和日语用户的请求)。否则就会产生前面提到过的选择性偏差。作为对比,我们注意一下上图中Layer B中那40%的空闲流量,它里面没有出现condition,所以是可以继续分配给别的实验(或Domain)的。
除了condition这种方式之外,还有一种情况,也需要在一份随机流量之中再过滤出一部分流量。谷歌的论文中提到了一个例子,假设有一个实验是为了测试一个搜索请求何时应该返回天气信息。这种情况下,A/B实验系统并不知道如何把需要返回天气信息的请求过滤出来,分配给这个实验,因为是否返回天气信息是由这个实验本身的逻辑来决定的。这是一个非常动态的过滤条件,A/B实验系统只能把切分出来的一份完整的随机流量都分配给这个实验,然后由这个实验本身的逻辑再来决定要不要「触发」天气信息的返回。这里的触发过程,称为trigger。trigger是需要实验本身的逻辑来动态决策的,因此无法用condition的方式由A/B实验系统统一支持。
trigger会引发一个非常微妙的问题:为了进行实验分析,我们必须把「触发」的请求记录(logging)下来。由于分配到实验组的所有请求,除了「触发」的请求,剩下的「未触发」的请求都是没有产品改动的(即跟对照组一样,用户感受不到实验),所以如果基于整个实验组和对照组的流量进行实验对比分析,会对实验结果的度量产生稀释。正确的做法肯定是对比实验组中真正「触发」的流量和对照组中「本应触发」的流量。什么叫「本应触发」呢?就是说按照实验本身的逻辑,本来一个请求应该触发,但由于当前是对照组,所以才没有触发。
最后需要说明的一点是,上面的例子中,我们的实验都是10%或20%的流量,这只是为了方便举例,实际中的一个实验可能用不了这么大的流量比例,可能1%就够了(针对具体情况而定)。
总结
科学探索世界的目标,就是为了发现事物发展变化的因果规律。而我们在日常工作中,显然也是希望按照科学方法来行事的。但当我们自认为已经按照「科学」的方法在行动的时候,稍有不慎却会落入思维的陷阱。
我们经常犯的错误包括:
- 把相关性当成因果性;
- 选择性偏差;
当然,最大的错误莫过于:对于逻辑和因果律的蔑视。既不遵循逻辑,又不重视因果关系的推导,随意而草率地分析现象之间的关系,完全按照个人的想法做决定,是造成很多方向性错误的根源。对于互联网公司来说,科学的A/B实验给我们提供了一个行动范本,可以引领我们如何做到数据驱动,一步步地提升我们的产品。
关于A/B实验,还有很多有意思而重要的课题值得讨论,比如对于实验结果的对比分析:如何判断一个实验的数据效果是正向的还是负向的,从而来决策这个实验到底应该推广开来还是应该放弃掉。由于统计数据的随机特性,这个问题有时候并不像想象地那么简单,需要用到统计学中的假设检验的理论。限于篇幅原因,我们以后有机会再讨论。
(正文完)
参考文献:
其它精选文章:
原创文章,转载请注明出处,并包含下面的二维码!否则拒绝转载!
本文链接:http://zhangtielei.com/posts/blog-ab-test.html
欢迎关注我的个人微博:微博上搜索我的名字「张铁蕾」。
